java集合list map set
java集合list map set
JDK提供了一组主要的数据结构实现,如List、Map、Set等常用数据结构。这些数据都继承自 java.util.Collection 接口,并位于 java.util 包内。
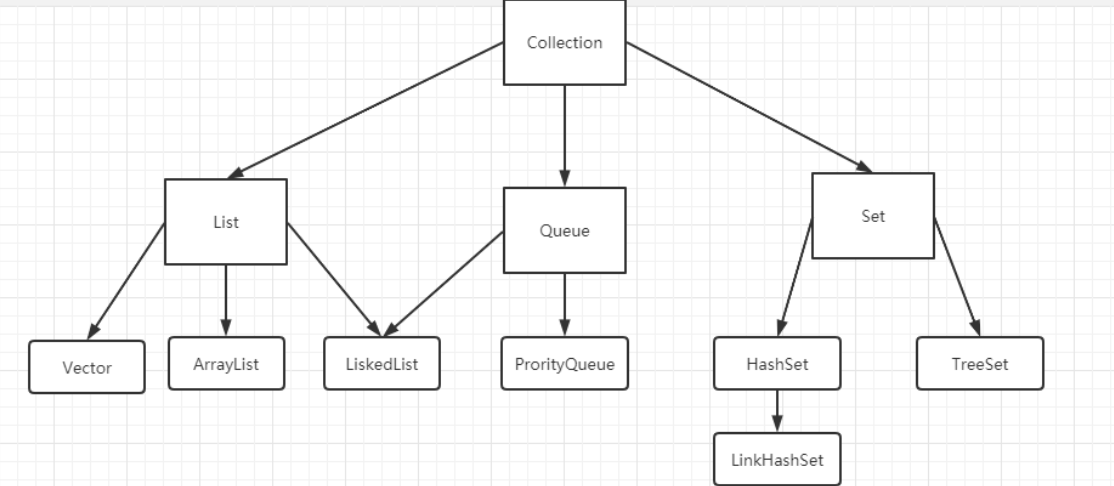
1、List接口
最重要的三种List接口实现:ArrayList、Vector、LinkedList。
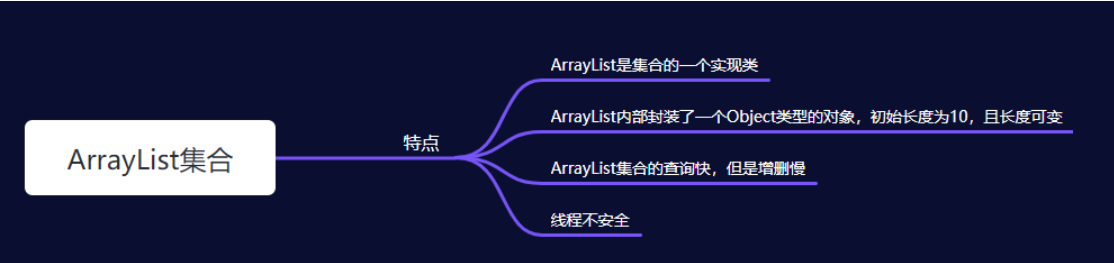
一、ArrayList集合
1.ArrayList集合的特点
2.ArrayList集合的一些方法
- add(Object element) 向列表的尾部添加指定的元素。
- size() 返回列表中的元素个数。
- get(int index) 返回列表中指定位置的元素,index从0开始。
- add(int index, Object element) 在列表的指定位置(从0开始)插入指定元素
- set(int i, Object element) 使用元素element替换索引i位置的元素,并返回被替换的元素
- clear() 从列表中移除所有元素
- contains(Object o) 如果列表包含指定的元素,则返回 true
- remove(int index) 移除列表中指定位置的元素,并返回被删元素,删除位置后面的元素(如果有)向前移动
- remove(Object o) 从List集合中移除第一次出现的指定元素,移除成功返回true,否则返回false。当且仅当List集合中含有满(o==null ? get(i)==null : o.equals(get(i)))条件的最低索引i的元素时才会返回true
- iterator() 返回按适当顺序在列表的元素上进行迭代的迭代器
3.ArrayList集合原理
- ArrayList 是 List 接口的可变数组非同步实现,并允许包括 null 在内的所有元素
- 底层使用数组实现
- 该集合是可变长度数组,数组扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组容量增长大约是其容量的 1.5 倍,这种操作的代价很高
- 采用了 Fail-Fast 机制,面对并发的修改时,迭代器很快就会完全失败,而不是冒着在将来某个不确定时间发生任意不确定行为的风险
- remove 方法会让下标到数组末尾的元素向前移动一个单位,并把最后一位的值置空,方便 GC(java垃圾回收)
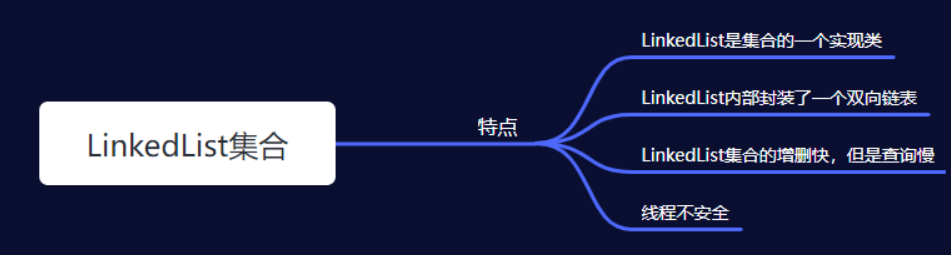
二、LinkedList集合
1.LinkedList集合的特点
2.LinkedList集合的一些方法
- 添加
boolean add(Object element) 它将元素附加到列表的末尾。
boolean add(int index,Object element) 指定位置插入。
void addFirst(E element) 元素附加到列表的头部
void addLast(E element) 元素附加到列表的尾部
- 获取数据
Object get(int index) 根据下标获取数据
Object getFirst() 它返回链表的第一个元素。
Object getLast() 它返回链接列表的最后一个元素。
- 查询
boolean contains(Object element)如果元素存在于列表中,则返回true。
- 修改
Object set(int index,Object element)它用于用新元素替换列表中的现有元素
- 删除
E remove() 删除第一个元素
E remove(int location) 删除指定位置的元素
E removeFirst() 删除并返回链接列表的头部一个元素
E removeLast() 删除并返回链接列表的尾部一个元素
- 清空
void clear():它删除列表中的所有元素。
- 链表长度
int size() :它返回链表的长度(元素个数)
3.LinkedList集合原理
- LinkedList 是 List 接口的双向链表非同步实现,并允许包括 null 在内的所有元素
- 底层的数据结构是基于双向链表的,该数据结构我们称为节点
- 双向链表节点对应的类 Node 的实例,Node 中包含成员变量:prev,next,item。其中,prev 是该节点的上一个节点,next 是该节点的下一个节点,item 是该节点所包含的值
- 它的查找是分两半查找,先判断 index 是在链表的哪一半,然后再去对应区域查找,这样最多只要遍历链表的一半节点即可找到
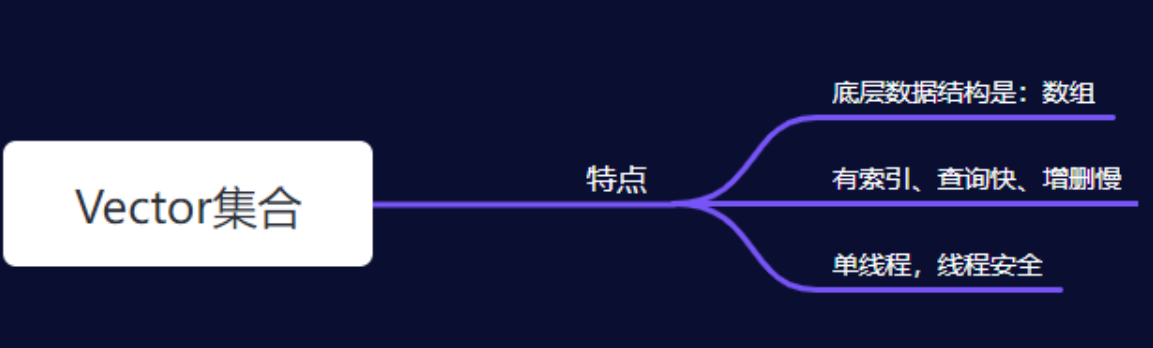
三、Vector集合(不建议使用)
四、List集合总结
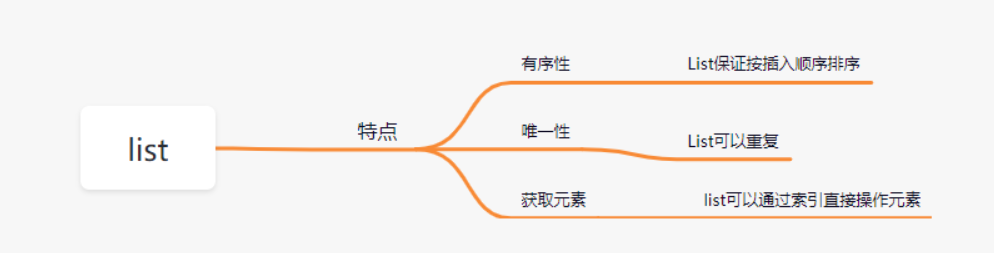
2、Set接口
一、HashSet集合
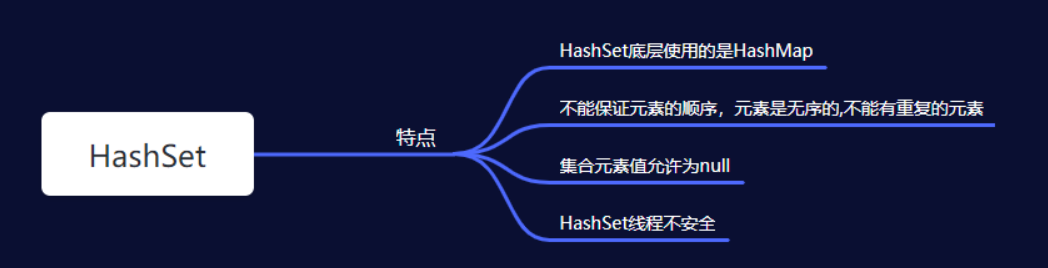
1.HashSet集合的特点
2.HashSet常用方法
-
add(Object o):向Set集合中添加元素,不允许添加重复数据。
-
size():返回Set集合中的元素个数
-
注意:不会按照保存的顺序存储数据(顺序不定),遍历时不能保证下次结果和上次相同。且向HashSet集合中添加元素,HashSet add方法实质是map全局变量调用了put方法,将数据存到了key,因为HashMap的 key不允许重复,所以HashSet添加的元素也不允许重复。
-
remove(Object o): 删除Set集合中的obj对象,删除成功返回true,否则返回false。
-
isEmpty():如果Set不包含元素,则返回 true。
-
clear(): 移除此Set中的所有元素。
-
iterator():返回在此Set中的元素上进行迭代的迭代器。
-
contains(Object o):判断集合中是否包含obj元素。
-
加强for循环遍历Set集合:
3.HashSet集合原理
- HashSet 由哈希表 (实际上是一个 HashMap 实例) 支持,不保证 set 的迭代顺序,并允许使用 null 元素
- 基于 HashMap 实现,API 也是对 HashMap 的行为进行了封装,可参考 HashMap
二、LinkedHashSet集合
LinkedHashSet集合的特点

三、TreeSet集合
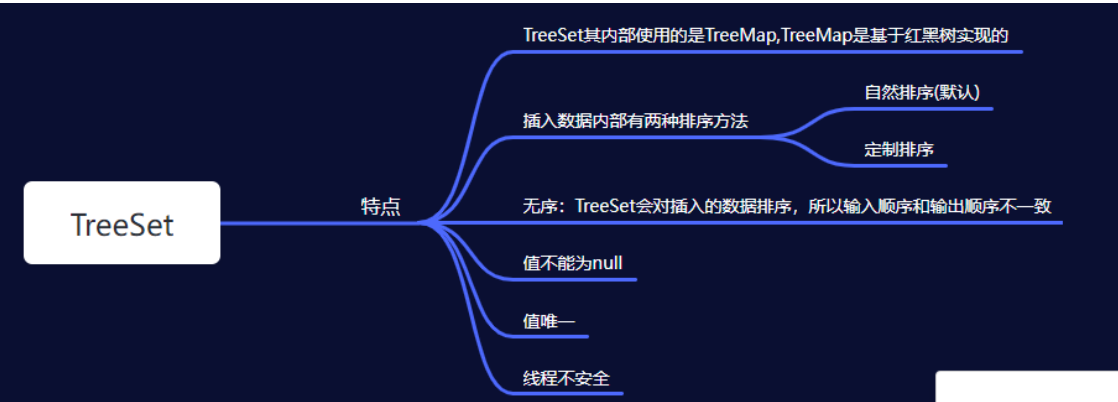
1.TreeSet集合的特点
2.TreeSet的基本使用
①.插入是按字典序排序的
public class Test {
public static void main(String[] args) {
TreeSet ts=new TreeSet();
ts.add("agg");
ts.add("abcd");
ts.add("ffas");
Iterator it=ts.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
}
}
输出 : 按照字典序排序的方式进行排序
abcd
agg
ffas
②.如果插入的是自定义对象 需要让类实现 Comparable 接口并且必须要重写compareTo
class Person implements Comparable{
String name;
int age;
Person(String name,int age)
{
this.name=name;
this.age=age;
}
@Override
public int compareTo(Object o) {
Person p=(Person)o;
//先对姓名字典序比较 如果相同 比较年龄
if(this.name.compareTo(p.name)!=0) {
return this.name.compareTo(p.name);
}
else
{
if(this.age>p.age) return 1;
else if(this.age<p.age) return -1;
}
return 0;
}
}
public class Test {
public static void main(String args[])
{
TreeSet ts=new TreeSet();
ts.add(new Person("agg",21));
ts.add(new Person("abcd",12));
ts.add(new Person("ffas",8));
ts.add(new Person("agg",12));
Iterator it=ts.iterator();
while(it.hasNext())
{
Person p=(Person)it.next();
System.out.println(p.name+":"+p.age);
}
}
}
输出
abcd:12
agg:12
agg:21
ffas:8
四、HashSet、LinkedHashSet、TreeSet的使用场景
- HashSet:HashSet的性能基本上比LinkedHashSet和TreeSet要好,特别是添加和查询,这也是用的最多的两个操作
- LinkedHashSet:LinkedHashSet的查询稍慢一些,但是他可以维持元素的添加顺序。所以只有要求当插入顺序和取出顺序一致的时候 才使用LinkedHashSet。
- TreeSet:只有在需要对元素进行排序时使用
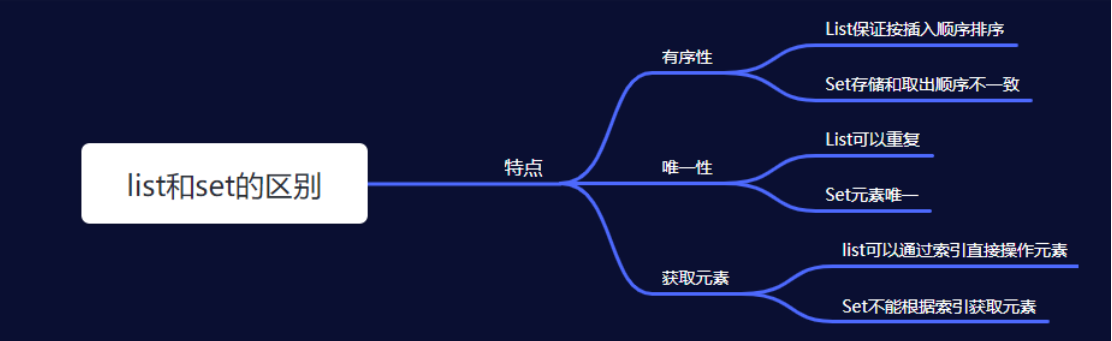
五、list和set集合的区别
2、Map接口
一、HashMap集合
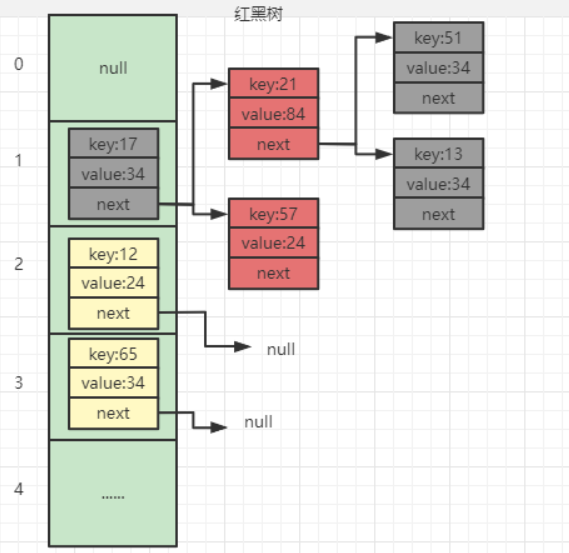
1.HashMap示意图
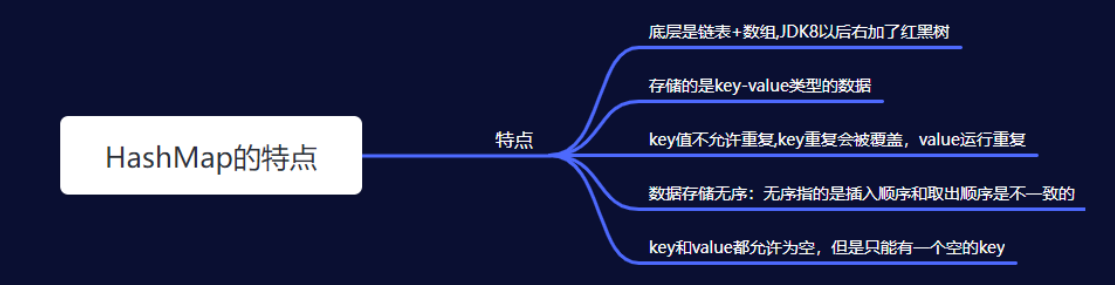
2.HashMap的特点
3.HashMap的常用方法
-
put(K key, V value) 将键(key)/值(value)映射存放到Map集合中
-
get(Object key) 返回指定键所映射的值,没有该key对应的值则返回 null,即获取key对应的value。
-
.size() 返回Map集合中数据数量,准确说是返回key-value的组数。
-
clear() 清空Map集合
-
isEmpty () 判断Map集合中是否有数据,如果没有则返回true,否则返回false
-
remove(Object key) 删除Map集合中键为key的数据并返回其所对应value值。
-
containsKey(Object key) Hashmap判断是否含有key
-
containsValue(Object value) Hashmap判断是否含有value
-
putAll():Hashmap添加另一个同一类型的map下的所有数据
-
public class Test { public static void main(String[] args) { HashMap<String, Integer> map=new HashMap<>(); HashMap<String, Integer> map1=new HashMap<>(); /*void*///将同一类型的map添加到另一个map中 map1.put("DEMO1", 1); map.put("DEMO2", 2); System.out.println(map);//{DEMO2=2} map.putAll(map1); System.out.println(map);//{DEMO1=1, DEMO2=2} } } -
replace(Object key,Object value):Hashmap替换这个key的value
4.HashMap集合原理
- HashMap 是基于哈希表的 Map 接口的非同步实现,允许使用 null 值和 null 键,但不保证映射的顺序
- 底层使用数组实现,数组中每一项是个单向链表,即数组和链表的结合体;当链表长度大于一定阈值时,链表转换为红黑树,这样减少链表查询时间
- HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Node 对象。HashMap 底层采用一个 Node [] 数组来保存所有的 key-value 对,当需要存储一个 Node 对象时,会根据 key 的 hash 算法来决定其在数组中的存储位置,在根据 equals 方法决定其在该数组位置上的链表中的存储位置;当需要取出一个 Node 时,也会根据 key 的 hash 算法找到其在数组中的存储位置,再根据 equals 方法从该位置上的链表中取出该 Node
- HashMap 进行数组扩容需要重新计算扩容后每个元素在数组中的位置,很耗性能
- 采用了 Fail-Fast 机制,通过一个 modCount 值记录修改次数,对 HashMap 内容的修改都将增加这个值。迭代器初始化过程中会将这个值赋给迭代器的 expectedModCount,在迭代过程中,判断 modCount 跟 expectedModCount 是否相等,如果不相等就表示已经有其他线程修改了 Map,马上抛出异常
二、TreeMap集合
1.TreeMap的特点

2.TreeMap的常用方法
- ceilingEntry(K key) 返回指定的 Key 大于或等于的最小值的元素,如果没有,则返回 null
public class Test {
public static void main(String[] args) {
TreeMap treeMap = new TreeMap();
treeMap.put("1", "demo1");
treeMap.put("2", "demo2");
treeMap.put("3", "demo3");
Entry entry = treeMap.ceilingEntry("2.5");
System.out.println(entry.getKey() + "||" + entry.getValue()); // 3||demo3
entry = treeMap.ceilingEntry("4");
System.out.println(entry); // null
}
}
- ceilingKey(K key) 返回指定的 Key 大于或等于的最小值的 Key,如果没有,则返回 null
public class Test {
public static void main(String[] args) {
TreeMap treeMap = new TreeMap();
treeMap.put("1", "demo1");
treeMap.put("2", "demo2");
treeMap.put("3", "demo3");
Object obj = treeMap.ceilingKey("2.5");
System.out.println(obj); // 3
obj = treeMap.ceilingKey("5");
System.out.println(obj); // null
}
}
- clone() 返回集合的副本
public class Test {
public static void main(String[] args) {
TreeMap treeMap = new TreeMap();
treeMap.put("1", "demo1");
treeMap.put("2", "demo2");
treeMap.put("3", "demo3");
Object obj = treeMap.clone();
System.out.println("treeMap集合中所有的元素:" + treeMap);
System.out.println("treeMap的副本:" + obj);
TreeMap tm = (TreeMap)obj;
System.out.println(tm.get("2"));
}
}
- public Comparator super comparator() 如果使用默认的比较器,就返回 null,如果使用其他的比较器,则返回比较器的哈希码值
public class Test {
public static void main(String[] args) {
TreeMap treeMap1 = new TreeMap();
TreeMap treeMap2 = new TreeMap();
treeMap1.put("1", "demo1");
treeMap1.put("2", "demo2");
treeMap2.put("a", "demo1");
treeMap2.put("b", "demo2");
System.out.println("treeMap1集合中所有的元素:" + treeMap1);
System.out.println("treeMap2集合中所有的元素:" + treeMap2);
Comparator comparator = treeMap1.comparator();
System.out.println(comparator);
comparator = treeMap2.comparator();
System.out.println(comparator);
TreeMap tm = new TreeMap(new Comparator<String>() {
public int compare(String o1, String o2) {
return o2.compareTo(o1); // 正负代表大小
}
});
tm.put("1", "test1");
tm.put("2", "test2");
tm.put("3", "test3");
System.out.println("tm集合中所有的元素:" + tm);
System.out.println(tm.comparator());
}
}
- descendingKeySet() 返回集合的全部 Key,并且是逆序的
public class Test {
public static void main(String[] args) {
TreeMap treeMap = new TreeMap();
treeMap.put("1", "demo1");
treeMap.put("2", "demo2");
treeMap.put("3", "demo3");
Set set = treeMap.descendingKeySet();
System.out.println(set);
}
}
- firstEntry() 返回集合中最小 Key 的元素
public class Test {
public static void main(String[] args) {
TreeMap treeMap = new TreeMap();
treeMap.put("1", "demo1");
treeMap.put("2", "demo2");
treeMap.put("3", "demo3");
Object key = treeMap.firstKey();
System.out.println(key); // 1
}
}
- floorEntry(K key) 返回小于等于 key 的最大 Key 的元素
public class Test {
public static void main(String[] args) {
TreeMap treeMap = new TreeMap();
treeMap.put("1", "demo1");
treeMap.put("2", "demo2");
treeMap.put("3", "demo3");
Entry entry = treeMap.floorEntry("2.5");
System.out.println(entry); // 2=demo2
}
}
- floorKey(K key) 返回小于等于 key 的最大 Key 的 key
public class Test {
public static void main(String[] args) {
TreeMap treeMap = new TreeMap();
treeMap.put("1", "demo1");
treeMap.put("2", "demo2");
treeMap.put("3", "demo3");
Map map = treeMap.headMap("2.5");
System.out.println(map);
}
}
- headMap(K toKey, boolean inclusive) 当 inclusive 为 true 时,就是返回 Key 小于等于 toKey 的所有元素
public class Test {
public static void main(String[] args) {
TreeMap treeMap = new TreeMap();
treeMap.put("1", "demo1");
treeMap.put("2", "demo2");
treeMap.put("3", "demo3");
Map map = treeMap.headMap("2", true);
System.out.println(map);
map = treeMap.headMap("2", false);
System.out.println(map);
}
}
更多方法参考
https://blog.csdn.net/weixin_32954161/article/details/114832951
https://else.wiki/post/JavaListMapSet