Java — Set \ List \ Map
参考博文
https://blog.csdn.net/lmarster/article/details/90672794
https://blog.csdn.net/Leon_Jinhai_Sun/article/details/104728299
http://data.biancheng.net/view/107.html
关于重写hashcode以及equals的介绍:https://blog.csdn.net/weixin_44259720/article/details/88414828
Set \ Map \ List
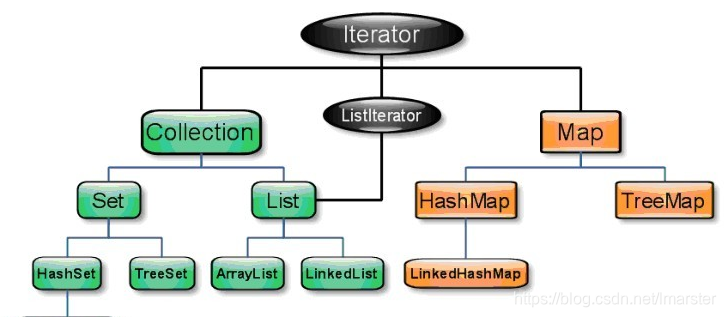
博客参考:https://blog.csdn.net/lmarster/article/details/90672794
Set
HashSet
- 特点
- 不能保证元素的排列顺序,顺序有可能发生变化
- 不是同步的
- 集合元素可以是null,但是只能有一个null
当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置。
简单的说,HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值相 等
注意,如果要把一个对象放入HashSet中,重写该对象对应类的equals方法,也应该重写其hashCode()方法。其规则是如果两个对 象通过equals方法比较返回true时,其hashCode也应该相同。另外,对象中用作equals比较标准的属性,都应该用来计算 hashCode的值。TreeSet
TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式,自然排序 和定制排序,其中自然排序为默认的排序方式。
TreeSet判断两个对象不相等的方式是两个对象通过equals方法返回false,或者通过CompareTo方法比较没有返回0。
二者的实现:
TreeSet 是二差树实现的,Treeset中的数据是自动排好序的,不允许放入null值。 HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束。 HashSet要求放入的对象必须实现HashCode()方法,放入的对象,是以hashcode码作为标识的,而具有相同内容的 String对象,hashcode是一样,所以放入的内容不能重复。但是同一个类的对象可以放入不同的实例 。
List
List接口继承了Collection接口以定义一个允许重复项的有序集合
ArrayList
LinkedList
addFirst(),addLast(),getFirst(),getLast(),removeFirst(),romoveLast()这些API可以使链表变成堆栈、队列、双向队列使用
/**
* List常用算法举例
*/
List p1 = new LinkedList();
List p2 = new LinkedList();
for(int i = 0; i<=9;i++){
p1.add("a"+i);
}
//打印p1[a0, a1, a2, a3, a4, a5, a6, a7, a8, a9]
System.out.println(p1);
//随机排列
Collections.shuffle(p1);
System.out.println(p1);
//逆序
Collections.reverse(p1);
System.out.println(p1);
//排序
Collections.sort(p1);
System.out.println(p1);
//折半查找
System.out.println(Collections.binarySearch(p1, "a5"));
Map
HashMap 存储数据采用的哈希表结构
最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度。HashMap最多只允许一条记录的键为Null(多条会覆盖);允许多条记录的值为 Null。非同步的。
由于要保证键的唯一、不重复,需要重写键的hashCode() 方法、equals() 方法。
- 根据键的HashCode存储数据
- 允许一条键为NULL
- 允许值为NULL
- 非同步
TreeMap
能够把它保存的记录根据键(key)排序,默认是按升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。TreeMap不允许key的值为null。非同步的。
- 键排序
- key不允许为空
- 非同步
HashTable
与 HashMap类似,不同的是:key和value的值均不允许为null;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢。
- 线程同步
LinkedHashMap 存储数据采用的哈希表结构+链表结构
保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.在遍历的时候会比HashMap慢。key和value均允许为空,非同步的。
通过哈希表结构可以保证的键的唯一、不重复,需要重写键的 hashCode() 方法、equals() 方法。