大数据技术介绍:02分布式文件系统HDFS
HDFS是什么?
HDFS源自于Google的GFS论文
发表于2003年10月
HDFS是GFS克隆版
Hadoop Distributed File System
易于扩展的分布式文件系统
运行在大量普通廉价机器上,提供容错机制
为大量用户提供性能不错的文件存取服务
HDFS的优点:
1.高容错性
数据自动保存多个副本
副本丢失后,自动恢复
2.适合批处理
移动计算而非数据
数据位置暴露给计算框架
3.适合大数据处理
GB、TB、甚至PB级数据
百万规模以上的文件数量
10K+节点规模
4.流式文件访问
一次性写入,多次读取
保证数据一致性
5.可构建在廉价机器上
通过多副本提高可靠性
提供了容错和恢复机制
HDFS典型应用:
快手用HDFS存储所有的视频数据
百度用HDFS存储用户行为数据和网页数据
滴滴用HDFS保存快车/专车等行为轨迹数据
阿里巴巴用HDFS保存用户行为数据
腾讯用HDFS保存用户行为数据、社交行为数据等
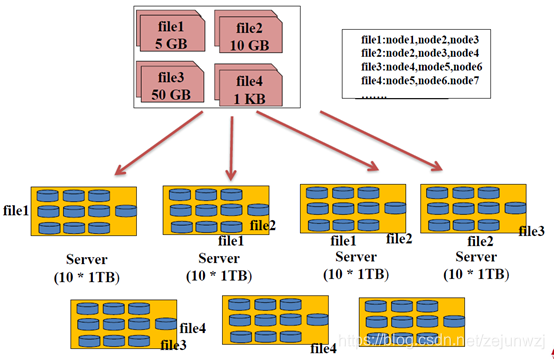
分布式文件系统的一种实现方式:如下图:
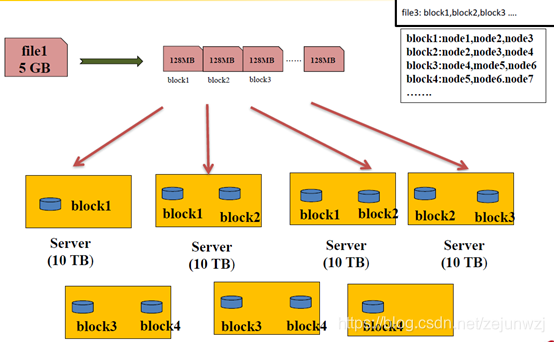
HDFS设计思想,如下图:
HDFS架构:如下图1,2,3
图1:
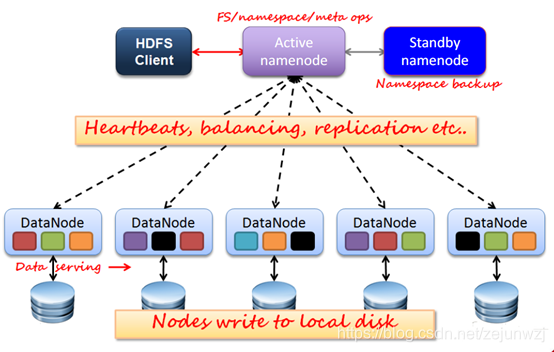
图2:
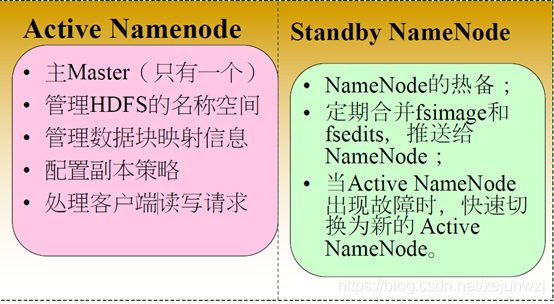
图3:

HA与Federation:
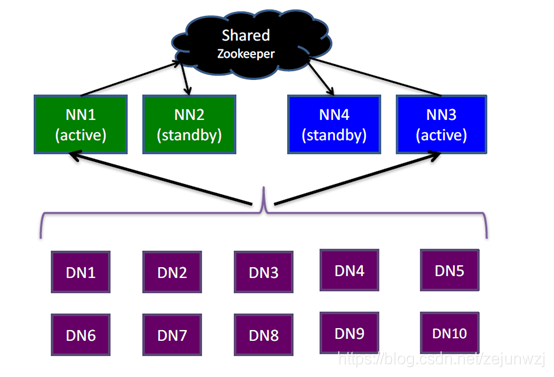
主备NameNode数据同步:
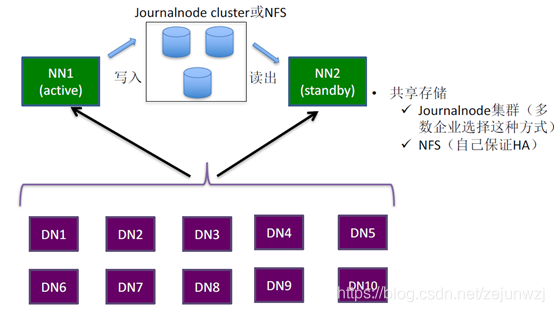
HDFS数据块(block)
文件被切分成固定大小的数据块;默认数据块大小为128MB,可配置;若文件大小不到128MB,则单独存成一个block
为何数据块如此之大?
数据传输时间超过寻道时间(高吞吐率)
一个文件存储方式
按大小被切分成若干个block,存储到不同节点上;默认情况下每个block有三个副本

为什么选择三副本?
1000TB数据集群,存储在各种RAID 级别上的风险,以数据丢失的概率为衡量标准(3年内的统计):RAID-5最不可靠,会损失2TB数据,而三副本方案最靠谱。
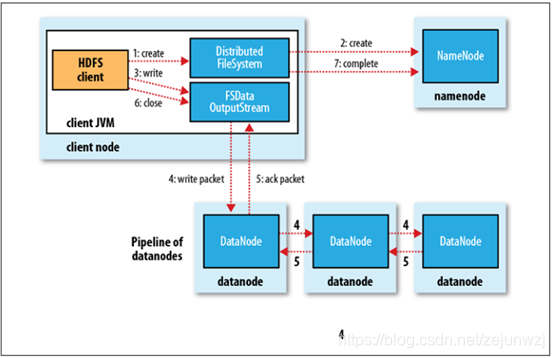
HDFS内部机制–写流程:如下图
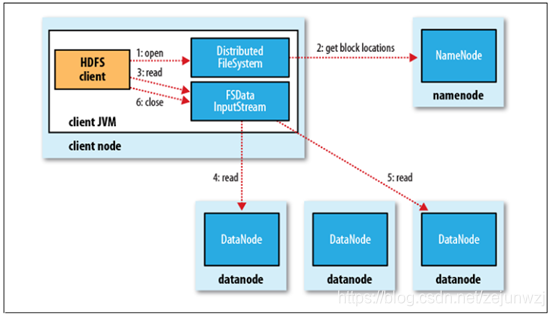
HDFS内部机制—读流程:如下图
HDFS内部机制—可靠性策略:
• 文件完整性
– CRC32校验
– 用其他副本取代损坏文件
• Heartbeat
– Datanode 定期向Namenode发
heartbeat
• 元数据信息
– FSImage(文件系统镜像)、Editlog
(操作日志)
– 多份存储
– 主备NameNode实时切换
常见的三种错误情况:
文件坏掉;
网络或者机器实现。
NameNode挂掉。
实践1:搭建HDFS集群(3):动态增加新的DataNode
将其他DataNode上的hadoop安装包(里面的配置文件已经修改好了)拷贝到新节点相同目录下;确保配置文件(比如core-site.xml,hdfs-site.xml等)是经过修改的,跟其他DataNode一致
在新节点上:
解压安装包
启动DataNode:hadoop-deamon.sh start datanode
问题讨论:
一:HDFS上的目录/data跟linux系统上的目录/data有关系吗?
没有任何关系,HDFS上的/data目录是虚拟的,元数据存储在NameNode中,数据存储在DataNode(具体可查看hdfs-site.xml中dfs.datanode.data.dir 对应的目录)上
如果不小心,格式化两次HDFS,怎么办?
Step 1:关闭HDFS所有活的服务
Step 2:删除hdfs-site.xml中配置dfs.namenode.name.dir和dfs.datanode.data.dir对应的目录
Step 3:重新格式化并启动HDFS
HDFS配置文件参数含义:

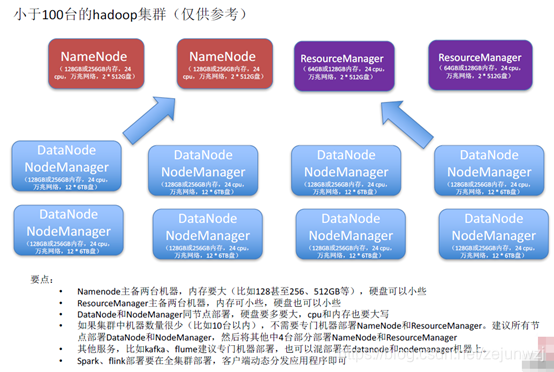
企业级大数据集群硬件选型和部署方案:如图仅供参考。
HDFS Java API介绍:
**Configuration类:**该类的对象封装了配置信息,这些配置信息来自core-*.xml;
FileSystem类:文件系统类,可使用该类的方法对文件/目录进行操作。一般通过FileSystem的静态方法
get获得一个文件系统对象;
FSDataInputStream和FSDataOutputStream类:
HDFS中的输入输出流。分别通过FileSystem的open方法和create方法获得。
以上类均来自java包:org.apache.hadoop.fs
HDFS Shell命令—文件操作命令:
将本地文件上传到HDFS上
bin/hdfs dfs -copyFromLocal /local/data /hdfs/data
bin/hdfs dfs -put /local/data /hdfs/data
删除文件/目录
bin/hdfs dfs -rmr /hdfs/data
创建目录
bin/hdfs dfs -mkdir /hdfs/data
HDFS Shell命令—文件操作命令
hdfs dfs
HDFS Shell命令—管理命令
hdfs dfsadmin
HDFS Shell命令—管理脚本。在sbin目录下
start-all.sh
start-dfs.sh
start-yarn.sh
hadoop-deamon(s).sh
单独启动某个服务(不需要设置SSH免密码)
单独启动namenode:hadoop-deamon.sh start namenode
单独启动DataNode:hadoop-deamon.sh start datanode
你知道吗?
bin/hdfs和bin/hadoop区别
(一样的,建议使用hdfs,hadoop是很早引入的,为保证兼容性,仍保留着)
bin/hdfs dfs -ls /tmp
bin/hadoop dfs -ls /tmp
不同目录表示的区别
bin/hdfs dfs -ls /tmp
bin/hdfs dfs -ls file:///tmp
bin/hdfs dfs -ls hdfs://master:8020/tmp
下载Hadoop安装包,解压并修改配置
格式化hdfs(只有第一次启动时需要格式化!),依次启动namenode和datanode
hadoop namenode –format
启动hdfs脚本:
/home/hadoopuser/hadoop/sbin/start-dfs.sh
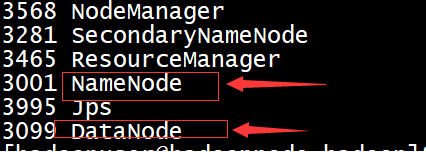
启动后jps如下图:NameNode和DataNode进程即为启动成功。
hdfs网址:WEB UI
http://IP或主机名:50070/
网页中可观察WEB UI中的信息
Datanode个数
总的文件数目,block数目
HDFS版本信息。
==============================
【完:2019-03-02 10:01】