flume简述
Flume 是什么?
- Flume 是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。

Flume 是 Cloudera 提供的分布式日志采集系统,支持在日志系统中定制各类数据发送方,用于收集数据,同时,Flume 提供对数据进行简单处理,并写到各种数据接收方(可定制,比如文本、HDFS、MySQL、HBase 等)。
Flume 的核心概念
- Agent: 使用 JVM 运行 Flume。每台机器运行一个 Agent,但是可以在一个 Agent 中包含多个 Sources 和 Sinks。
- Client: 生产数据,运行在一个独立的线程中。
- Source: 从 Client 收集数据,传递给 Channel。
- Channel: 连接 Sources 和 Sinks ,这个有点像一个队列。
- Sink: 从 Channel 收集数据,运行在一个独立线程中。
- Events: 可以是日志记录、Avro 对象等。
基本结构
基本结构图
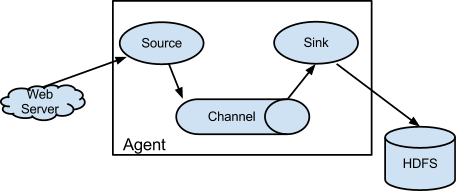
- Flume 以 Agent 为最小的独立运行单位,一个Agent就是一个JVM。
- 单 Agent 由 Source、Sink 和 Channel 三大组件构成。
- 通过这些组件,Event 可以从一个地方流向另一个地方,比如说送到图中的 HDFS。
- 简单来说 Flume 就是收集日志的。
组件详解
- Agent 包含: Source、Channel、Sink。
类似生产者、仓库、消费者的架构。 - Source 组件: 是专用于收集日志的。
可以处理各种类型各种格式的日志数据,包括 Avro、Thrift、Spooling Directory、Syslog、HTTP、自定义。Source 组件把数据收集来以后,临时存放在 Channel 中。 - Channel 组件: 是在 Agent 中专用于临时存储数据的,可以存放在 Memory、JDBC、File、自定义。Channel 中的数据只有在 Sink 发送成功之后才会被删除。
- Sink 组件: 是用于把数据发送到目的地的组件,目的地包括 HDFS、Logger、Avro、Thrift、File、null、HBase、Solr、自定义。
Flume 的广义用法

-
Flume 可以支持多级 Flume 的 Agent,即 Flume 可以前后相继
例如 Sink 可以将数据写到下一个 Agent 的 Source 中,这样的话就可以连成串了,可以整体处理了。
-
Flume 还支持扇入(fan-in)、扇出(fan-out)。
- 扇入就是 Source 可以接受多个输入
- 扇出就是 Sink 可以将数据输出多个目的地中
Event 详解
Flume 的核心
Flume 的核心是把数据从数据源(Source) 收集过来,再将收集到的数据送到指定的目的地(Sink)。为了保证输送的过程一定成功,在送到目的地(Sink)之前,会先缓存数据(Channel),待数据真正到达目的地(Sink)后,Flume 再删除自己缓存的数据。
- 数据传输顺序:Source(收集)->Channel(缓存数据,保证传输成功)->Sink(目的地)
Event 的数据流向图

- 在整个传输过程中,流动的是 Event,即事务保证是在 Event 级别进行的。
- Event 将传输的数据进行封装,是 Flume 传输数据的基本单位,如果是文本文件,通常是一行记录,Event 也是事务的基本单位。
- Event 从 Source,流向 Channel,再到 Sink,本身为一个字节数组,并可携带 headers(头信息)信息。
- Event 代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
Event 组成

- event headers
- event body
- event信息(即文本文件中的单行记录),即Flume 收集到的日记记录
Flume1.7.0 安装
-
1, 前提准备
安装 JDK1.7 及以上版本,并配置好环境变量。 -
2,下载安装包
官网:http://flume.apache.org
下载网址:http://www.apache.org/dyn/closer.lua/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz
版本号:apache-flume-1.7.0-bin.tar.gz扫描二维码关注公众号,回复: 5876732 查看本文章
-
3,上传至Linux服务器,并解压
解压命令:tar -zxvf apache-flume-1.7.0-bin.tar.gz -
4,修改 flume-env.sh 配置文件
1,进入FLUME_HOME/conf目录下[theone@hadoop01 software]$ cd apache-flume-1.7.0-bin/conf/2,复制配置文件
[theone@hadoop01 conf]$ cp flume-env.sh.template flume-env.sh3,编辑配置文件
[theone@hadoop01 conf]$ vim flume-env.sh4,修改JAVA_HOME变量值

-
5,配置环境变量
1,编辑.bash_profile[theone@hadoop01 ~]$ vim /home/theone/.bash_profile2,添加变量FLUME_HOME和PATH
export FLUME_HOME=/home/theone/Desktop/software/apache-flume-1.7.0-bin export PATH=$PATH:$FLUME_HOME/bin3,让配置文件立即生效
[theone@hadoop01 ~]$ source /home/theone/.bash_profil -
6,验证
在任意目录下执行命令flume-ng version
FLume相关应用
案例1:Avro 数据源(传输指定文件)
-
1,场景
两台机器或两个终端,一台为 Client,一台为 Agent,在 Client 上将指定文件传输到 Agent 机器上。 -
2,要求
监听一个指定的 Avro 端口,通过 Avro 端口可以获取到 Avro client 发送过来的文件。即只要应用程序通过 Avro 端口发送文件,Source 组件就可以获取到该文件中的内容。
(注:Avro 和 Thrift 都是一些序列化的网络端口,通过这些网络端口可以接受或者发送信息,Avro 可以发送一个指定的文件给 Flume,Avro 源使用 AVRO RPC 机制。)- 3,流程图

- 3,流程图
-
4,分析
该案例是,使用 Avro Source 接收外部数据源,Logger 作为 Sink,即通过 Avro RPC 调用,将数据缓存在 Channel 中,然后通过 Logger 打印出调用发送的数据。 -
5,具体实现
-
(1)创建 Agent 配置文件(Avro Source + Memory Channel + Logger Sink)
在FLUME_HOME/conf目录下创建avro.conf
[theone@hadoop01 conf]$ touch avro.conf或者根据 Flume 自身提供的模板,创建 avro.conf 配置文件
[theone@hadoop01 conf]$ cp flume-conf.properties.template avro.conf-
(2)编辑配置文件 avro.conf
[theone@hadoop01 conf]$ vim avro.conf ## Name the components on this agent agent1.sources = avro_source1 agent1.channels = memory_ch1 agent1.sinks = log_sink1 ## Describe/configure the source agent1.sources.avro_source1.type = avro agent1.sources.avro_source1.channels = memory_ch1 # 使用avro的source需要说明被监听的主机IP和端口号 # 监听的主机名或IP地址。0.0.0.0 代表所有不清楚的主机和目的网络,即表示整个网络,也就是网络中的所有主机。 agent1.sources.avro_source1.bind=0.0.0.0 # 监听端口号 agent1.sources.avro_source1.port=4141 ## Describe the sink # Logger Sink 记录 INFO 级别的日志,一般用于调试。 agent1.sinks.log_sink1.type = logger agent1.sinks.log_sink1.channel = memory_ch1 ## Use a channel which buffers events inmemory,channel为内存的一块空间 agent1.channels.memory_ch1.type = memory # Capacity为最大容量,transCapacity为Channel每次提交的Event的最大数量,Capacity>= transCapacity agent1.channels.memory_ch1.capacity=1000 agent1.channels.memory_ch1.transactionCapacity=100
-
-
3, 启动 Flume Agent agent1
flume-ng agent -n agent1 -c conf -f conf/avro.conf -Dflume.root.logger=INFO,console
-n agent1: 指定 agent 名字为 agent1,需要与 avro.conf 中设置的一致 -c conf: 指定配置文件目录为 conf -f conf/avro.conf: 指定配置文件为 conf/avro.conf -Dflume.root.logger=INFO,console: 指定 DEBUG 模式在 console 输出 INFO 信息 -
4,创建指定文件
打开另外一个终端,执行命令echo "hello theone" > /home/theone/Desktop/software/data/avro.txt
-
5,使用 avro-client 发送文件
由于当前环境是在单机上模拟两台机器,所以,直接在新的终端中执行以下命令:flume-ng avro-client -c conf -H 0.0.0.0 -p 4141 -F /home/theone/Desktop/software/data/avro.txt -
6,在启动 Flume Agent 的终端中查看打印结果

-
-
案例2:Spooldir 数据源(监听指定目录)
-
1,要求
监听一个指定的目录,即只要应用程序向这个指定的目录中添加新的文件,Source 组件就可以获取到该信息,并解析该文件的内容,然后写入到 Channle,最后上传到 HDFS 上。写入完成后,标记该文件已完成或者删除该文件。
-
2,注意事项
Spool 监测配置的目录下新增的文件,并将文件中的数据读取出来。需要注意两点:
(1) 拷贝到 Spool 目录下的文件不可以再打开编辑;
(2) Spool 目录下不可包含相应的子目录。 -
3,具体实现
(1)创建 Agent 配置文件(Spooling Directory Source + Memory Channel + HDFS Sink)
(2)在FLUME_HOME/conf目录下创建spooldir.conf
(3)touch spooldir.conf-
1,编辑配置文件 spooldir.conf
[software/data/avro.txt@hadoop01 conf]$ vim spooldir.conf ## Name the components on this agent agent1.sources = spool_source1 agent1.channels = memory_ch1 agent1.sinks = hdfs_sink1 ## Describe/configure the source agent1.sources.spool_source1.type = spooldir # 配置目录 source,监控目录的变化(目录必须提前创建好),要求文件名必须唯一,否则 Flume 报错 agent1.sources.spool_source1.spoolDir=/home/theone/Desktop/software/data/flumedata # 配置往memory_ch1传输数据 agent1.sources.spool_source1.channels = memory_ch1 # 是否在 Event 的 Header 中添加文件名,boolean 类型,默认为 false agent1.sources.spool_source1.basenameHeader = true # 若是 Event 中有了Header(basenameHeader配置为true)时,Event 的 Header 会存储文件名的<key,value>信息,默认的 key 为basename,value 为文件的名字(不含目录部分),即 basename=文件名 agent1.sources.spool_source1.basenameHeaderKey = basename ## Describe the sink agent1.sinks.hdfs_sink1.type = hdfs # 数据存放在HDFS上的目录 agent1.sinks.hdfs_sink1.hdfs.path=hdfs://hadoop01:9000/flumedata/%Y-%m-%d # 前缀名用上传之前的文件名 agent1.sinks.hdfs_sink1.hdfs.filePrefix = %{basename} # 数据流格式,默认为sequenceFile,但里面的内容无法直接打开浏览 agent1.sinks.hdfs_sink1.hdfs.fileType=DataStream # 文件写入格式包括 Text agent1.sinks.hdfs_sink1.writeFormat=TEXT # 按时间滚动文件,单位秒,默认30秒, 0不滚动 agent1.sinks.hdfs_sink1.hdfs.rollInterval=0 # 按文件大小滚动文件,单位字节,10M=10485760B agent1.sinks.hdfs_sink1.hdfs.rollSize=10485760 # 当events个数达到该数量时,将临时文件滚动成目标文件,默认是10,0为不基于消息个数 agent1.sinks.hdfs_sink1.hdfs.rollCount=0 # 超时后关闭无效文件,0 为禁止自动关闭闲置的文件 agent1.sinks.hdfs_sink1.hdfs.idleTimeout=60 # HDFS Sink 是否使用当地的时间,默认为false agent1.sinks.hdfs_sink1.hdfs.useLocalTimeStamp=true # 配置从memory_ch1接收数据 agent1.sinks.hdfs_sink1.channel = memory_ch1 ## Use a channel which buffers events inmemory,channel为内存的一块空间 agent1.channels.memory_ch1.type = memory # Capacity为最大容量,transCapacity为Channel每次提交的Event的最大数量,Capacity>= transCapacity agent1.channels.memory_ch1.capacity=1000 agent1.channels.memory_ch1.transactionCapacity=100 这样的配置会产生许多小文件,因为默认情况下,一个文件存储10个 Event,这个配置由 rollCount 控制,默认为10。此外还有一个参数为 rollSize,这个是控制一个文件的大小,如果文件大于这个数值,就是另起一文件。这里我们设置 rollSize 为 10M,也就是上传到 HDFS 上的文件大于 10M 后就会另起一个文件写入; 默认的文件名都是以 Event 开头,因为我想保留原来文件的名字,所以使用了以下配置(其中,basenameHeader 是相对 source 而言,filePrefix 是相对 sink 而言,分别这样设置之后,上传到 HDFS 上的文件名就会变成“原始文件名.时间戳”)。-
3,创建监听目录
[theone@hadoop01 ~]$ mkdir /home/theone/Desktop/software/data/flumedata/
-
4,启动 Flume Agent agent1
flume-ng agent -n agent1 -c conf -f conf/spooldir.conf -Dflume.root.logger=INFO,console -
5,往监控目录中上传文件
[theone@hadoop01 flumedata]$ cd /home/theone/Desktop/software/data [theone@hadoop01 test]$ cp rating.json /home/theone/Desktop/software/data/flumedata/
-
6,查看结果
监控目录中的效果

发现文件名称变成“文件名.COMPLATED”,这是为了标记该文件已经被写入完成。
HDFS上的效果

idleTimeout=60,rollSize 设置为 10M 时,原理是这样的,Flume 里面每生成一个接收文件时的命名规则。如:rating.json.1500274365422.tmp,.tmp 表示这个文件正在被使用来接收 Events,当满 10M 之后,这个文件会被 rename 成 rating.json.1500274365422,把 .tmp 后缀去掉,但是如果你停止了应用程序后,rating.json.1500274365422 还没满 10M,按照默认的 idleTimeout=0(禁用自动关闭空闲文件)设置,不会将它 rename,也就是 .tmp 后缀一直在,造成了这个文件一直在使用当中的一个假象,这是有问题的,我们设置idleTimeout=60,即 60 秒后这个文件还没有被写入数据,就会关闭它然后 rename 它去掉 .tmp,以后新进来的 Events,会新开一个 .tmp 文件来接收。
上图中,最后一个文件只有 1.6M,这是因为在写入 1.6M 后,监控目录中的文件已经写入完毕。 -
7,HDFS Sink 配置讲解
-
type 组件类型名称,需要是 HDFS hdfs.path HDFS 目录路径(例如HDFS://namenode:9000/flume/webdata/) hdfs.filePrefix 默认为FlumeData。写入 HDFS 的文件名前缀(注意:句点自动添加) hdfs.rollInterval 默认30s。滚动当前文件之前等待的秒数(0 =从不根据时间间隔滚动) hdfs.rollSize 默认1024KB。文件大小触发滚动,以字节为单位(0:从不根据文件大小滚动) hdfs.rollCount 默认10。在滚动之前写入文件的事件数(0 =从不根据事件数量滚动) hdfs.idleTimeout 默认为0s。超时之后,非活动文件关闭(0 =禁用自动关闭空闲文件) -