概述
之前介绍的几种垃圾回收算法都是间接式的,他们都需要从已知的根集合出发对存活对象图进行遍历,才能确定所有的存活对象。本章将介绍最后一种基本回收算法:引用计数。在引用计数算法中,对象的存活性可以通过引用关系的创建或删除直接判定,无须像追踪式垃圾回收器那样先通过堆遍历找出所有存活对象,然后再反向确定出未遍历到的对象。
引用计数算法所依赖的是一个十分简单的不变式:当且仅当指向某个对象的引用数量大于零时,该对象才有可能是存活的。下面的代码展示了最简单的引用计数实现:
New():
ref -> allocate()
if ref = NULL
error "Out Of Memory"
rc(ref) <- 0
return ref;
atomic Write(src, i, ref):
addReference(ref)
deleteReference(src[i])
src[i] <- ref
addReference(ref):
if ref != NULL
rc(ref) <- rc(ref) + 1
deleteReference(ref):
if ref != NULL
rc(ref) <- rc(ref) - 1
if rc(ref) = 0
for each fld in Pointers(ref)
deleteReference(*fld)
free(ref)
上图中,Write 方法用于增加新目标对象的引用计数。在多线程环境下,赋值器都需要执行一些额外的屏障操作,才能确保程序正确执行。
引用计数算法的优缺点
引用计数算法之所以能够成为一种有竞争力的自动内存管理策略,是由下面几个原因决定的:
- 引用计数算法的内存管理开销分摊在程序运行过程中,同时一旦某一对象成为垃圾便可立即得到回收,因此引用计数算法可以持续操作即将填满的堆,不必像追踪式回收器那样需要一定的保留空间。
- 引用计数算法直接操作指针的来源和目标,因此其局部性不会比所服务的应用程序差。
- 引用计数算法无需确定程序的根,即使当系统部分不可用时,也能够回收部分内存。
正是由于这些原因,引用计数算法在众多系统中得到了应用,包含一些编程语言实现(早期的 Smalltalk、List,以及 awk、perl、Python),还有 C++ 里的 Boost 智能指针库。
但是,引用计数也存在一系列缺陷:
- 引用计数给赋值器带来额外时间开销,对指针做读写操作时,都需要调整相关联的引用计数。例如在对链表进行迭代时,链表中的每个对象都需要先增加,接着再减少一次。从性能角度来看,如果对寄存器或线程栈上的操作也需要引入这一开销,显然是不能接受的。
- 为避免多线程竞争可能导致的对象释放过早,引用计数的增减操作以及加载和存储指针的操作都必须是原子化的,而仅对引用计数的增减操作进行保护是不够的。在后面的章节将详细讨论引用计数和并发问题的细节。
- 在简单的引用计数算法中,即使是只读操作,也需要引发一次内存写请求(变更引用计数)。
- 简单的引用计数算法无法回收环装引用数据结构。
- 在最坏情况下,某一对象的引用计数可能等于堆中对象总数,这意味着引用计数所占用的域必须与一个指针域的大小相同。鉴于面向对象语言中对象的平均大小通常较小(例如 Java 程序中对象大小通常是 20 ~ 64 字节),这一空间开销便显得十分昂贵。
- 引用计数算法仍有可能导致停顿出现。当删除某一大型指针结构根节点的最后一个引用时,引用计数算法会递归地删除根节点的每一个子孙节点。
在引用计数所面临的问题当中,有两项可以得到解决:即引用计数操作的开销问题,以及环状垃圾的回收问题。对于这两个问题的解决,一般都需要引入万物静止式的停顿。
提升效率
引用计数算法的效率可以从两方面提升:一方面是减少屏障操作次数,另一方面是用更加廉价的非同步操作代替昂贵的同步操作。主要有以下几种解决方案:
- 延迟引用计数:以牺牲少量细粒度回收增量的时效性,来换取效率的提升。该方案将某些垃圾对象的鉴别推迟到某一时段结束时的回收阶段,从而避免了某些屏障操作。
- 合并引用计数:许多引用计数操作都是临时性的,不必要的,开发者可以手动去掉这些无用操作,在某些特殊场景下编译器也可以完成这些操作。
- 缓冲引用计数:同样会延迟垃圾对象的鉴别,但与前两者不同的是,该方法将所有的引用计数增减操作缓冲起来以便后续处理,同时只有回收线程执行引用计数变更操作。缓冲引用计数关注的是“何时”,而不是“是否”需要进行变更。
上述三种方案解决效率问题的思想是相通的,即将程序的执行划分为一系列时段,在同一时段内赋值器可以省略部分甚至所有的同步引用计数操作,或者将其替换为非同步的写操作。垃圾的鉴定是在每个时段结束时进行的,此时便需要将赋值器线程挂起,或者使用一个独立的回收器线程和赋值器线程并发处理。
本章将讨论延迟引用计数与合并引用计数,在这两种回收算法中,相邻回收时段会被万物静止式的停顿分开以实现引用计数的修正。在后面的章节将介绍缓冲引用计数如何将引用计数操作转移给其他并发线程,以及如何并发地进行合并引用计数。
延迟引用计数
与简单的追踪式回收算法相比,引用计数操作给赋值器带来的开销相对较高。分代与并发回收算法也会给赋值器带来一定的开销,但其远远小于安全地进行引用计数所需的开销。
大多数高性能引用计数系统都使用延迟引用计数策略。绝大多数指针加载操作都是将其加载到局部变量或寄存器、栈槽中,如何移除这些情况下的引用计数操作呢?可以将局部变量、寄存器等产生的引用计数变更延迟执行,仅当赋值器操作堆中对象时产生的引用计数变更才需要立即执行。延迟带来的影响是引用计数不再准确,因此立即回收引用计数为零的对象便不再安全。为了确保所有垃圾都能够得到回收,延迟引用计数必须引入万物静止式的停顿来定期修正引用计数,但幸运的是停顿时间通常要比追踪式回收器用的时间短。
下面是延迟引用计数算法的示例代码,可以看到在 Write 操作中,当操作堆中元素时,如果引用计数变为 0,就需要将其添加到零引用表 zct 中,而非直接释放。
New():
ref -> allocate()
if ref = NULL
collect() // 堆内存耗尽时,启动垃圾回收
ref -> allocate()
if ref = NULL
error "Out Of Memory"
rc(ref) <- 0
add(zct, ref)
return ref;
Write(src, i, ref):
if src = Roots
src[i] <- ref
else
atomic
addReference(ref)
remove(zct, ref) // 非零引用对象从 zct 中移除,有利于控制零引用表的大小
deleteReferenceToZCT(src[i])
src[i] <- ref
deleteReferenceToZCT(ref):
if ref != NULL
rc(ref) <- rc(ref) - 1
if rc(ref) = 0
add(zct, ref) // 延迟释放
atomic collect():
for each fld in Roots // 标记栈
addReference(*fld)
sweepZCT()
for each fld in Roots
deleteReferenceToZCT(*fld) // 反标记栈
sweepZCT():
while not isEmpty(zct)
ref <- remove(zct)
if rc(ref) = 0
for each fld in Pointers(ref)
deleteReference(*fld)
free(ref)
延迟引用计数消除了赋值器操作局部变量时的引用计数变更开销,一些较早研究表明,延迟引用计数可以将指针操作减少 80% 甚至更多,如果再考虑其对局部性的提升,那么在现代硬件条件下,其在性能提升方面应该更有优势。然而对象指针域的引用计数操作却无法延迟,必须立即执行,而且必须为原子操作。下一节将探讨如何使用简单方法替代由对象域变更引起的昂贵的引用计数原子操作,以及如何减少引用计数的修改次数。
合并引用计数
延迟引用计数解决了赋值器操作局部变量时的引用计数开销,但是当赋值器将某一对象的引用存入堆中时,引用计数的变更开销依然无法避免。研究表明,对于任意时段内的任意对象域,回收器只需关注其在该时段开始和结束时的状态,而时段内的引用计数操作可以忽略,因此可以将对象的多个状态合并成两个。例如,某个对象 X 的指针域 f 引用了对象 O0,该域在某个时段内先后被修改为 O1、O2…On,此时引用计数的更新操作如下图所示:
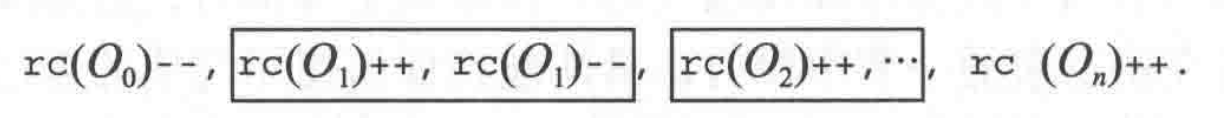
中间状态的一堆操作相互抵消后,只剩下了开始的 O0,和结束的 On。在每个时段内,写操作会在对象首次得到修改之前将其复制到本地日志中。具体算法如下所示:
me <- myThreadId
Write(src, i, ref):
if not dirty(src) // not dirty 表示是该时段内第一次修改,将其本身和指针域信息存到本地更新缓冲区中
log(src)
src[i] <- ref
log(obj):
for each fld in Pointers(ref)
if *fld != NULL
append(updates[me], *fld)
if not dirty(obj)
slot <- appendAndCommit(updates[me], obj)
setDirty(obj, slot) // 将被修改的对象标记位脏
dirty(obj):
return logPointer(obj) != CLEAN
setDirty(obj, slot):
logPointer(obj) <- slot
当赋值器更新某一指针域时,将对象的地址及其每个指针域都记录到本地更新缓冲区中,同时将被修改的对象标记位脏。在 log 方法中,为避免对象重复加入本地日志,算法先讲对象指针域初始值添加到对象中,同时只有当 src 不为脏时,才将其添加到日志中,然后再增加日志内部游标,并将对象打上脏标记。将对象标记位脏的方法是将其,在日志中对应条目地址写入其头域,即使竞争导致在多个线程本地缓冲区里出现同一对象的条目,算法也能保证各个条目包含相同的信息,因此无需关心对象头域中所记录的日志条目究竟位于哪个线程的本地缓冲区中。
这一章简单使用万物静止式停顿来周期性的处理日志,对于如何在赋值器线程处理同时并发处理合并引用计数将在后面章节讨论。在回收周期的开始阶段,现将每个线程挂起,然后再将每个线程的更新缓冲区合并到回收器的日志中,最后再为每个线程分派新的更新缓冲区。
atomic collect():
collectBuffers()
processReferenceCounts()
sweepZCT()
collectBuffers():
collectorLog <- []
for each t in threads
collectorLog <- collectorLog + updates[t]
processReferenceCounts():
for each entry in collectorLog
obj <- objFromLog(entry)
if dirty(obj) // 避免重复处理
logPointer(obj) <- CLEAN
incrementNew(obj)
decrementOld(entry)
decrementOld(entry):
for each fld in Pointers(entry)
child <- *fld
if child != NULL
rc(child) <- rc(child) - 1
if rc(child) = 0
add(zct, child)
incrementNew(obj):
for each fld in Pointers(entry)
child <- *fld
if child != NULL
rc(child) <- rc(child) + 1
上文提到,竞争关系可能导致多个线程的本地缓冲区中包含同一对象的条目,这就确保回收器只会对每个脏对象处理一次,因此 processReferenceCounts 在更新引用计数之前会先判断对象是否为脏。对于标记位脏的对象,回收器先清空其标记确保不会重复处理,然后再将回收时刻其所有子节点引用计数加 1,再讲当前时段内该对象首次得到修改之前的子节点的引用计数减 1。在简单引用计数系统中,一旦某一对象引用计数降至 0 就会立即得到递归释放。但是,如果算法将引用计数变更延迟,或者出于效率原因无法确保所有引用计数的增加操作先于减少操作执行,则需要将零引用对象记录到零引用表里。在该时段内,对象的最初子节点可以从日志中获得,而对象的当前子节点则可以从对象自身获取。
以下图为例来演示合并引用计数的处理过程,假设对象 A 的某个指针域在某一时间段内从对象 C 修改为对象 D,则在该时段结束时,对象 A 的两个指针域原有的值(B 和 C)已经记录到了回收器日志中,因此回收器会增加对象 B、D 的引用计数,同时减少 B、C 的引用计数。由于对象 A 中指向对象 B 的指针域并未修改,因此对象 B 的引用计数不变。

将延迟引用计数与合并引用计数相结合,可以降低赋值器上大部分引用计数操作的开销,代价是再次引入了停顿,尽管停顿时间要比追踪式回收器的短。我们降低了回收的时效性,同时日志缓冲区和零引用表也带来了额外的空间开销。
环状引用计数
对于环状数据结构而言,其内部对象的引用计数至少为 1,因此仅靠引用计数本身无法回收环状垃圾。不论是在应用程序还是运行时系统中,环状数据结构都是否普遍,如双向链表或环状缓冲区。
最简单的策略是在引用计数回收之外,偶尔使用追踪式回收作为补充。该方法假定大多数对象不会被环状数据结构所引用,因此可以通过引用计数方法实现快速回收,而追踪式回收则负责处理剩余的环状数据结构。
在所有能够处理环状数据结构的引用计数算法中,得到最广泛认可的是试验删除算法。该算法无需使用后备的追踪式回收器来进行整个存活对象图的扫描,相反它将注意力集中在可能会因删除引用而产生环状垃圾的局部对象图上。在引用计数算法中:
- 在环状垃圾指针结构内部,所有对象的引用计数都由其内部对象之间的指针产生。
- 只有在删除某一对象的某个引用之后,该对象的引用计数扔大于零时,才有可能出现环状垃圾。
部分追踪算法充分利用上述两个结论,该算法从一个可能是垃圾的对象开始进行子图追踪。对于遍历到的每个引用,算法将对其目标对象进行试验删除,即临时性地减少目标对象的引用计数,从而移除由内部指针产生的引用计数。追踪完成后,如果某个对象的引用计数仍然不是零,则必然是因为子图之外的其他对象引用了该对象,进而可以判定该对象及其传递闭包都不是垃圾。
Recycler 算法支持环状引用计数的并发回收,主要分为以下三个阶段:
- 回收器从某个可能是环状垃圾成员的对象出发进行子图追踪,同时减少由内部指针产生的引用计数。算法将遍历到的对象着为灰色。
- 对子图中所有对象进行检测,如果某一对象的引用计数不是零,则该对象必然被子图外的其他对象引用。此时需要对第一阶段的试验删除操作进行修正,算法将存活的灰色对象重新着为黑色,同时将其他灰色对象着为白色。
- 子图中依然为白色的对象必然是垃圾,算法可以将其回收。
New():
ref -> allocate()
if ref = NULL
collect() // 堆内存耗尽时,启动垃圾回收
ref -> allocate()
if ref = NULL
error "Out Of Memory"
rc(ref) <- 0
return ref;
addReference(ref):
if ref != NULL
rc(ref) <- rc(ref) + 1
color(ref) <- black
deleteReference(ref):
addReference(ref):
if ref != NULL
rc(ref) <- rc(ref) - 1
if rc(ref) = 0
release(ref)
else
candidate(ref)
release(ref):
for each fld in Pointers(ref)
deleteReference(fld)
color(ref) <- black
if not ref in candidates // 备选垃圾将稍后处理
free(ref)
candidate(ref):
if color(ref) != purple
color(ref) <- purple
candidates.add(ref)
atomic collect():
markCandidates()
for each ref in candidates
scan(ref)
collectCandidates()
markCandidates():
for each ref in candidates
if color(ref) = purple // 紫色表示备选垃圾
markGray(ref)
else
remove(candidates, ref)
if color(ref) = black && rc(ref) = 0
free(ref)
markGray(ref): // 试验删除,标记灰色
if color(ref) != gray
color(ref) <- gray
for each fld in Pointers(ref)
child <- *fld
if child != NULL
rc(child) <- rc(child) - 1
markGray(child)
scan(ref):
if color(ref) = gray
if rc(ref) > 0 // 试验删除之后,依然大于0,表示存在外部引用
scanBlack(ref) // 需要反向试验删除,也就是删除操作
else
color(ref) <- white
for each fld in Pointers(ref)
child <- *fld
if child != NULL
scan(child)
scanBlack(ref):
color(ref) <- black
for each fld in Pointers(ref)
child <- *fld
if child != NULL
rc(child) <- rc(child) - 1 // 反向试验删除
if color(child) != black
scanBlack(child)
collectCandidates(): // 回收依然为白色的对象
while not isEmpty(candidates)
ref <- remove(candidates)
collectWhite(ref)
collectWhite(ref):
if color(ref) = white && not ref in candidates
color(ref) <- black
for each fld in Pointers(ref)
child <- *fld
if child != NULL
collectWhite(child)
free(ref)
环状引用计数示例如下图所示:

对某些类型的对象进行特殊处理可以进一步提升回收性能,此类对象包括不包含指针的对象、永远不可能是环状数据结构成员的对象等。
受限域引用计数
对象的引用计数在其头部所占用的空间也是值得注意的。从理论上讲,某一对象可能会被堆中所有的对象引用,因此引用计数域的大小应当与指针域的大小相同,但对于小对象而言,这一开销显得过于昂贵。在实际应用中,大部分对象的引用计数通常较小,那么如何优化其空间开销呢?
如果事先知道引用计数可能达到的上限,则可以使用较小的域来记录引用计数,但应用程序往往会存在少量被广泛引用的对象。在面对引用计数偶尔超出上限的问题时,如果能够引入后备处理机制,则仍有可能限制引用计数域的大小。比如一旦某个对象的引用计数达到最大值,则将其转变成粘性引用,即之后的任何指针操作都不再改变该对象的引用计数值,其结果是:一旦对象的引用计数超出上限,则不能通过引用计数来回收此对象,此时就需要后备的追踪式回收器来处理这种对象。
总结
引用计数算法的优点是:
- 时效性较高。
- 具有良好的局部性。
其缺点是:
- 简单引用计数无法处理环状垃圾,若要处理就需要引入更复杂的算法。
- 每次指针读写都伴随着引用计数变更操作,在吞吐量方面开销更大,特别是多线程引用程序中的引用计数变更操作需要使用昂贵的同步操作。
- 增大了对象的空间大小。
环状垃圾可以由后备的追踪式回收器或者试验删除算法处理,但这两种策略都需要在回收环状数据时挂起赋值器线程。
延迟引用计数会忽略赋值器对局部变量的操作,合并引用计数仅关注某一对象在开始和结束时的状态,同时忽略时段内的指针操作,减少了引用计数和某些同步操作,然而代价是再次引入了万物静止式的停顿。
高级引用计数算法可以解决原生引用计数算法中存在的诸多问题,但矛盾的是这些算法都需要引入与追踪式回收类似的万物静止式停顿。