python优雅自由的编程风格,让人爱不释手。而他优雅的背后,则是其对内存的合理设计。
目前python内存管理,采用了三大技术,内存池,引用计数器,垃圾回收。其中,引用计数器、垃圾回收
内存池技术
使用背景:许多时候,python中的对象,所需要使用的内存,都是比较小的,而且申请、释放是比较频繁的。如果采用直接向操作系统malloc申请、free释放的方式,频发操作,必然影响python的性能。而引入内存池技术,就可以有效解决这个问题。
技术原理:
第一步,在python运行时,python会先调用malloc,向操作系统申请一大片内存。这片内存,我可以将其成为area。
第二步,将area进行分层为不同的pool,将每一个pool分为block。不同pool之间的block大小可能是不一样的,同一个pool中的block大小是相同的。block,就是存储一个python对象的最小内存单元;block的大小必需是ALIGNMENT的整数倍。
下图表格,就是python在32位机器与64位机器上的内存池分层大小的一些数据。
| 32 位机器 | 64 位机器 | |
|---|---|---|
| arena size | 256 KB | 1 MB |
| pool size | 4 KB | 16 KB |
| ALIGNMENT | 8 B | 16 B |
这里有一个不太明确的点,就是32位和64位机器上block大小的最大值,我这里暂时没有找到准确的资料。根据网络资料,这里总结了一下,如有错误,欢迎指正:
32位机器,block大小分别为8位,16位,24位,32位……512位,对应级别从0,1,2,3-63级
64位机器,block大小分别为16位,32位,48位,54位……512位,对应级别从0,1,2,3-31级
第三步,在运行时,根据请求的内存大小n,内存池进行合理的内存分配。基本原则如下:
a,当n<block大小最大值512位时,python就会调用malloc从操作系统申请一块内存,用以存放该python对象
b,当n<block大小最大值512位时,python就直接调用内存池pymalloc进行内存分配——分配原则就是,给出大于等于n的最小block。举例说明,n=101,32位机器上最小的block是104位,在64位机器上就是112位的block
c,垃圾回收的内存,直接交给内存池管理,而不是交给操作系统。
引用计数器
有了内存池的管理,那么剩下的问题,就只有怎么回收内存的问题了。
python这里,引入了’对象引入计数器‘的概念。这在java中也是常见的。
具体原理,简单提一嘴,就是所有python对象,都维护着一个引用计数器,当程序调用这个对象式,计数器就会加1,不再使用这个对象时,计数器就会减1。
垃圾回收
python的垃圾回收,有两个启动条件,
1,程序员手动启动,直接调用gc.collect()
2,让python自动启动垃圾回收,启动条件就是:python分配对象次数,与python取消分配对象的次数,两者的差值超过一个额定的阈值,python就会启动垃圾自动回收功能。
import gc
print(gc.get_threshold())
>>>(700, 10, 10)(1)
大家在python中运行这串代码,就会得到(700, 10, 10)这个结果。这个结果的第一个元素700,就是python分配/取消分配次数两者之差的阈值,超过700,python就会启动垃圾回收。
第二个元素10,第三个元素10,就代表一代对象、二代对象扫描的频率。这个在垃圾回收策略中会具体讲到。
垃圾回收策略:
1,根据引用计数器,来回收变量。如果引用计数器为0,则表明,该对象没有被使用了,直接回收垃圾。
这里,有一个特殊情况,就是循环引用。举例说明,python对象a引用了b,b对象引用了a,那么a对象,b对象的引用计数器最少都为1,这就导致两个对象循环引用,无法释放。针对这种情况,python引入了”标记清除“的方法,具体规则如下:
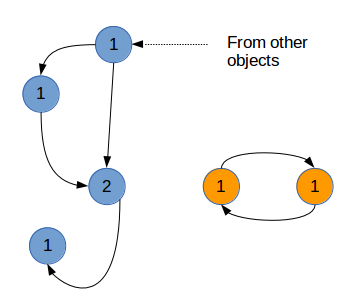
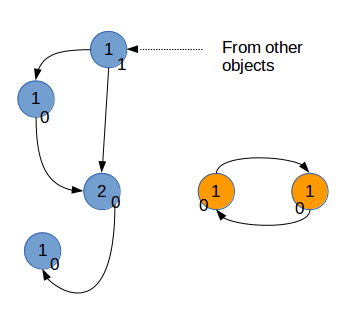
(这两个图片就是循环引用、标记清除的简略示意图)
a,对所有相互引用的python对象的引用计数,复制一份副本。这个副本依然复制了原来python对象的相互引用关系——本质上就是链表结构;
b,在计数副本中,对一个计数减一,相应的这个计数器所指向的下一个计数器,也要减一。
c,所有副本中的计数器遍历一遍之后,所有计数为0的节点,就是需要被垃圾回收的对象。
d,通过副本的操作,垃圾回收就会把对应的python对象释放掉。
2,分代回收机制
技术背景:频繁的对所有python对象进行垃圾回收,会严重影响程序性能。所以有必要,对python对象进行分类,针对不同的类型,采取不同的垃圾扫描策略。
技术原理:
基本假设条件:存活时间越长的python对象,它在将来的程序运行中,成为垃圾的概率会越小。所以,我们可以采取”空间换时间“的策略,减少垃圾回收的扫描范围、扫描策略
a,对所有的python对象进行分类,对应等级为0代,1代,2代。所有新建的python对象,都是0代。
b,经过一定次数的垃圾扫描,有一些长寿的python对象,依然在使用,则将这些长寿对象,划归为1代。
c,1代经过一定次数的垃圾扫描,在1代中依然有一些长寿的python对象,还在使用,则将1代中的这些长寿对象,划归为2代。
d,进行垃圾回收时,0代经过一定次数的扫描,就会1代进行一次扫描;1代经过一定次数的扫描,就会对2代进行扫描。举例说明,在(1)中我们得到一组数据(700, 10, 10),后面的两个10,就是代表这里的扫描阈值次数,在0代每经过10次扫描后,就会对1代进行一次扫描;在1代经过每10次扫描后,就会对2代进行一次扫描
最后,通过扫描引用计数器、分代扫描后,一些不在 使用的变量就会被python回收,交给内存池进一步管理。
参考资料: