研究浏览器渲染这一块
参考链接:https://www.cnblogs.com/yanglang/p/7090120.html
http://assets.en.oreilly.com/1/event/83/How WebKit Renders the Web Presentation.pdf
https://blog.csdn.net/greenqingqingws/article/details/19163061
根据博客1大佬的说明,完成了一张图如下
重排和重绘会影响浏览器的性能等
重排reflow: 当影响到布局的时候,浏览器就会进行重排,比如img大小未知重新加入页面的时候浏览器就会倒回去加载img,img以下的代码重新渲染 (img加载是异步,head里面的css和js是同步加载)
重绘repaint: 只是改变某个元素的背景色、文字颜色、边框颜色等等不影响它周围或内部布局的属性, 发生重绘
重绘比重排效率高很多
浏览器组成
- 用户界面 - 包括地址栏、后退/前进按钮、书签目录等,也就是你所看到的除了用来显示你所请求页面的主窗口之外的其他部分。
- 浏览器引擎 - 用来查询及操作渲染引擎的接口。
- 渲染引擎 - 用来显示请求的内容,例如,如果请求内容为html,它负责解析html及css,并将解析后的结果显示出来。
- 网络 - 用来完成网络调用,例如http请求,它具有平台无关的接口,可以在不同平台上工作。
- UI后端 - 用来绘制类似组合选择框及对话框等基本组件,具有不特定于某个平台的通用接口,底层使用操作系统的用户接口。
- js解释器 - 用来解释执行JS代码。
- 数据存储 - 属于持久层,浏览器需要在硬盘中保存类似cookie的各种数据,Html5定义了web database技术,这是一种轻量级完整的客户端存储技术
浏览器解析html
1. 解析dom树
看了大佬的文档,唤醒了我残留的大学编译原理知识
但是DOM树的构建由于种种原因依赖的是浏览器自己带的编译程序,原因大概有如下:
- html语言允许某些隐式添加的标志,可以省略起始活着结束标签,html不是上下文无关语法
- 浏览器可以接受一些常见的无效HTML用法
- 解析过程需要不断反复。在脚本标记中添加document.write,可以添加HTML标记,在解析过程中更改了输入内容
浏览器在渲染的过程中以8k作为一个单位进行渲染
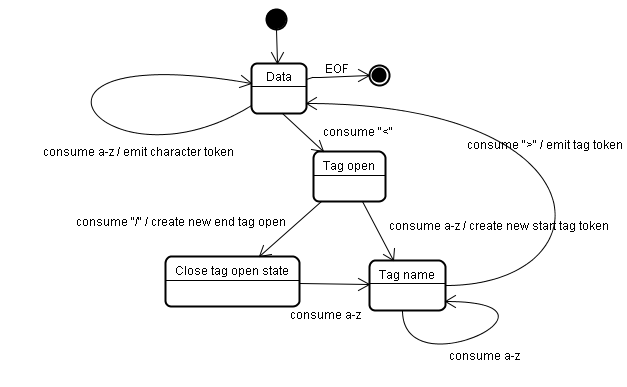
标记化
标记化算法的输入结果是HTML标记,使用状态机表示。状态机一共有4个状态:数据状态(Data)、标记打开状态(Tag open)、标记名称状态(Tag name)、关闭标记打开状态(Close tag open state)。
初始状态是数据状态。
当标记是处于数据状态时,
-
遇到字符<时,状态更改为“标记打开状态”:
a. 接收一个a-z字符会创建“起始标记”,状态更改为“标记名称状态”,并保持到接收>字符。此期间的字符串会形成一个新的标记名称。接收到>标记后,将当前的新标记发送给树构造器,状态改回“数据状态”。
b. 接收下一个输入字符/时,会创建关闭标记打开状态,并更改为“标记名称状态”。直到接收>字符,将当前的新标记发送给树构造器,并改回“数据状态”。 -
遇到a-z字符时,会将每个字符创建成字符标记,并发送给树构造器。
大佬原文,经过我的理解应该是这个样子
一个<html></html>标签
图画的很丑,然后原图在此
<html>
<body>
Hello world
</body>
</html>
html开始标记、body开始标记、H字符、e字符、l字符、l字符、o字符、空格字符、w字符、o字符、r字符、l字符、d字符、body结束标记、html结束标记、文件结束标记
对于自闭合的标签识别,比如<img src="" />这种的识别
如前面的原图,当识别到 /时,就会进入关闭标记打开状态了,不需要标签状态返回到数据态了
dom树构建
- 在创建解析器的同时,也会创建Document对象。
- 在树构建阶段,以Document为根节点的DOM树也会不断进行修改,添加各种元素。
- 标记生成器发送的每个节点都会由树构建器进行处理。
- 每个标记都有对应的DOM元素,这些元素会在接收到标记时创建。
开放元素的堆栈:添加到DOM树中的元素也会添加到开放元素的堆栈中,用于纠正嵌套错误和处理未关闭的标记。
树构建算法可以用状态机来描述,称为“插入模式”。
树构建阶段的输入是一个来自标记化阶段的标记序列。
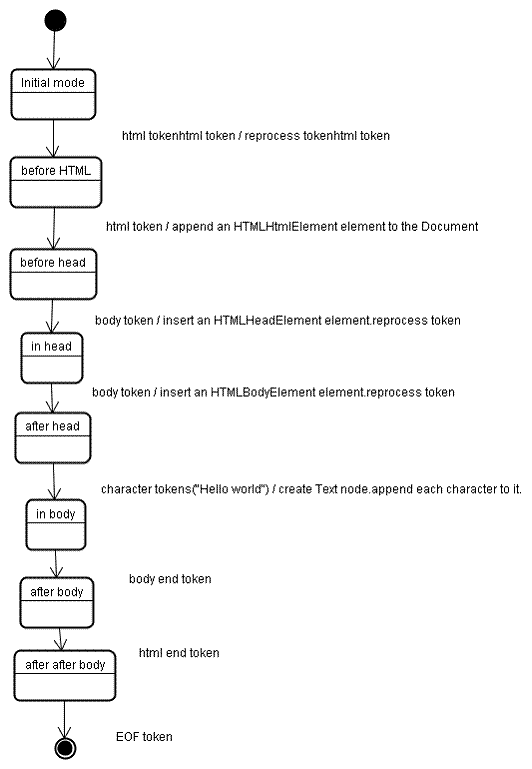
以上例来说明,
- 第一个模式是“initial mode”。接收HTML标记后转为“before html”,并在这个模式下创建一个HTMLHtmlElement元素,并将其附加到Document根对象上。
- 状态改为“before head”。此时接收到“body”标记,系统创建一个HTMLHeadElement,并添加到树中,
- 然后进入“in head”模式,
- 然后转入“after head”模式。
- 系统对body标记重新处理,创建HTMLBodyElement并插入到DOM树,模式变为“in body”。
- 然后接收到“H”字符标记,创建Text节点。
- 后面的“ello world”字符标记也被附加到了这个Text节点上。
- 接收到body结束标记时,系统进入“after body”模式。
- 在接收到html结束标记时,进入“after after body”模式。接收到文件结束标记后,解析过程结束。
构造出类似这样的一个dom树
在这个阶段,浏览器将文档标记为可交互的,并开始解析处于延时模式中的脚本——这些脚本在文档解析后执行。
文档状态将被设置为完成,同时触发一个load事件。
Html5规范中有符号化及构建树的完整算法(http://www.w3.org/TR/html5/syntax.html#html-parser)。