一、变量与对象
关系图如下:
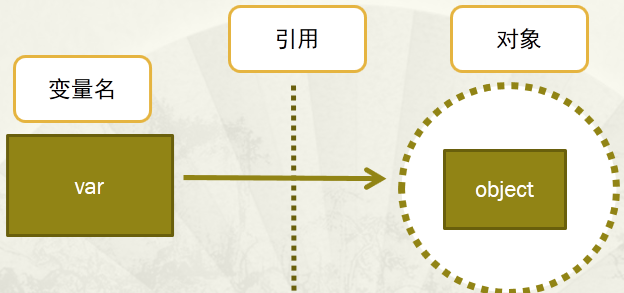
1、变量:通过变量指针引用对象
变量指针指向具体对象的内存空间,取对象的值。
2、对象:类型已知,每个对象都包含一个头部信息(头部信息:类型标识符和引用计数器)
注意:
变量名没有类型,类型属于对象(因为变量引用对象,所以类型随对象),变量引用什么类型的对象,变量就是什么类型的。
eg:
在Python37解释器中:
In [32]: var1=object In [33]: var2=var1 In [34]: id(var1) Out[34]: 139697863383968 In [35]: id(var2) Out[35]: 139697863383968
在JetBrain中:
var1 = object var2 = var1 print(id(var1)) print(id(var2))
输出:
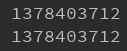
PS:id()是python的内置函数,用于返回对象的身份,即对象的内存地址。
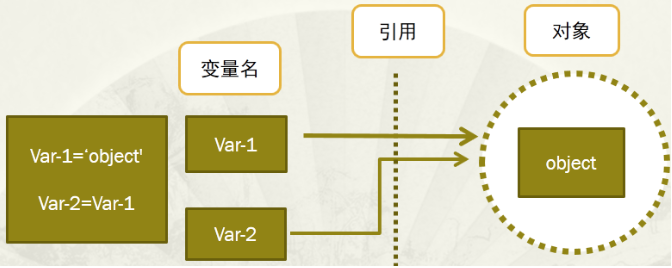
在内存中:
示例1:
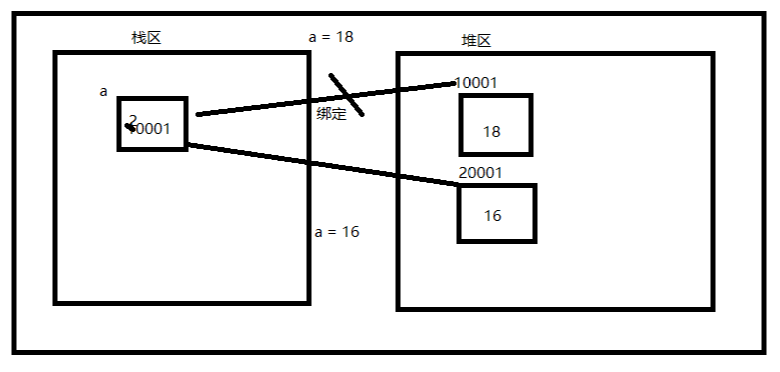
示例2:
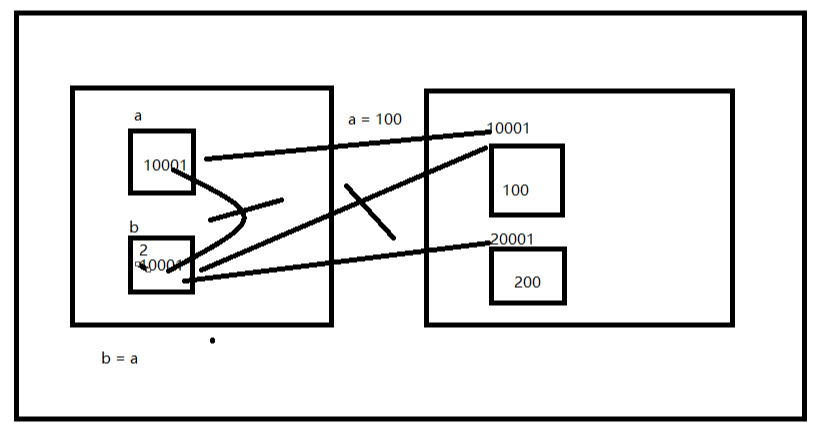
示例3:
In [39]: a=123 In [40]: b=a In [41]: id(a) Out[41]: 23242832 In [42]: id(b) Out[42]: 23242832 In [43]: a=456 In [44]: id(a) Out[44]: 33166408 In [45]: id(b) Out[45]: 23242832
3、引用所指判断
通过 is 进行引用所指判断,is是用来判断两个引用所指的对象是否相同。
示例:
整数:
In [46]: a=1 In [47]: b=1 In [48]: print(a is b) True
短字符串:
In [49]: c="good" In [50]: d="good" In [51]: print(c is d) True
长字符串:
In [52]: e="very good" In [53]: f="very good" In [54]: print(e is f) False
列表:
In [55]: g=[] In [56]: h=[] In [57]: print(g is h) False
由运行结果可知:
1、Python缓存了整数和短字符串,因此每个对象在内存中只存有一份,引用所指对象就是相同的,即使使用赋值语句,也只是创造新的引用(在内存的栈区内创建新的内存空间),而不是对象本身(对象依然存在于堆区),id相同;
2、Python没有缓存长字符串、列表及其他对象,即使由多个相同的对象,可以使用赋值语句创建出新的对象,id不同。
查看id()的源码:
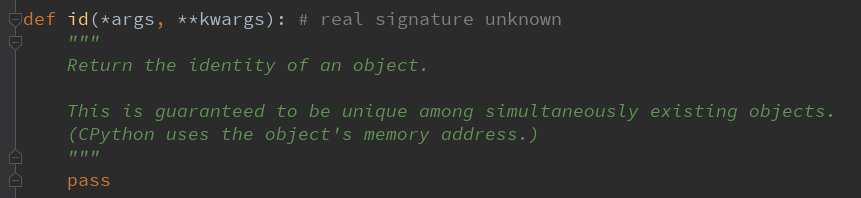
def id(* args,** kwargs):#真正的签名未知 “”” 返回对象的标识。 这保证在同时存在的对象中是唯一的。 (CPython使用对象的内存地址。) “”” 通过
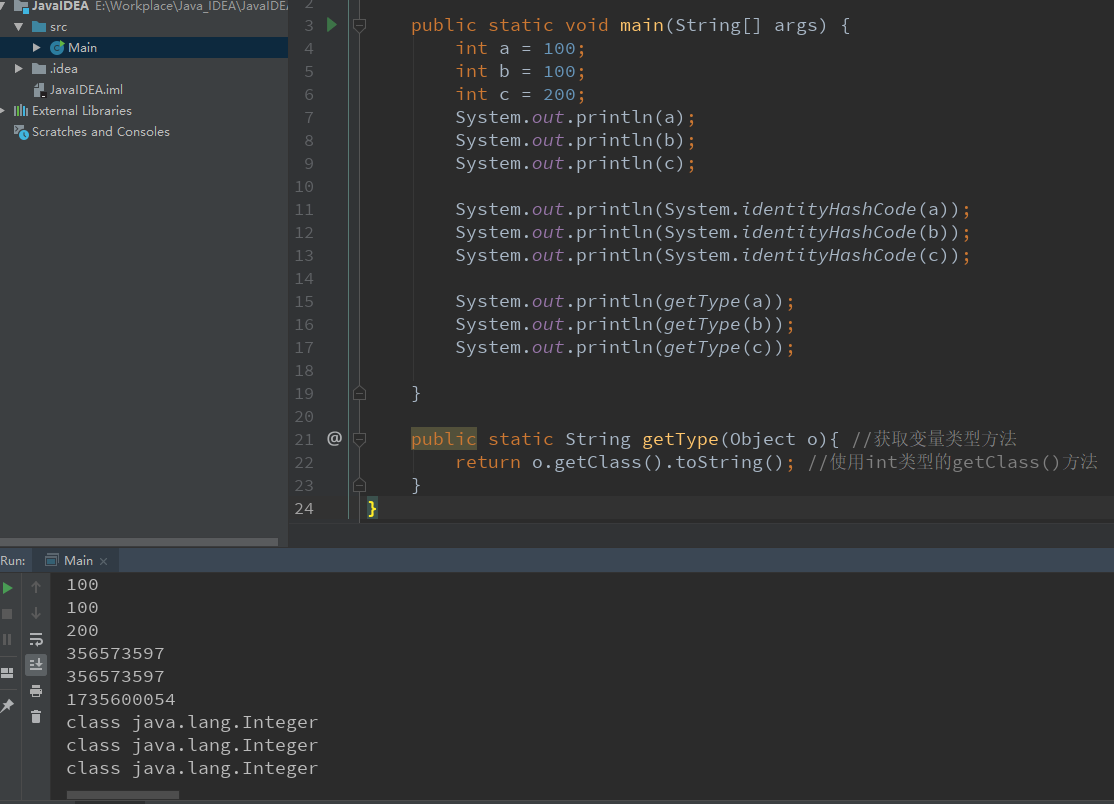
在 Java中获取对象的内存地址方法 如下:
二、内存池
Python中有分为大内存和小内存:(256K为界限分大小内存)
1、大内存使用malloc进行分配
2、小内存使用内存池进行分配
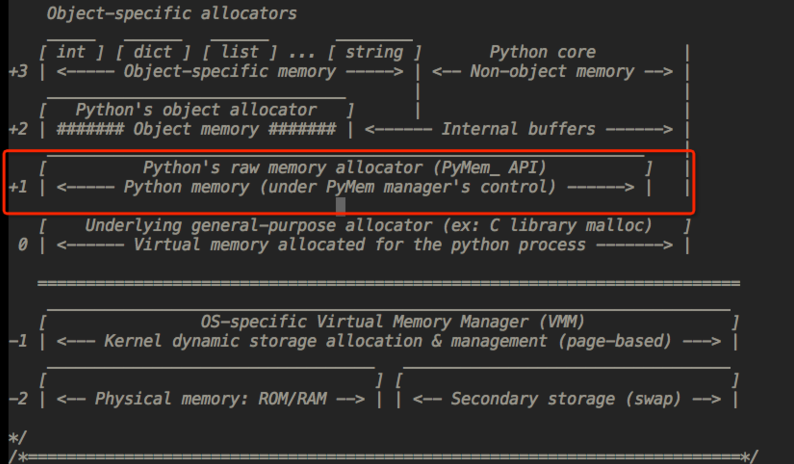
3、Python的内存池(金字塔)
第3层:最上层,用户对Python对象的直接操作
第1层和第2层:内存池,有Python的接口函数PyMem_Malloc实现-----若请求分配的内存在1~256字节之间就使用内存池管理系统进行分配,调用malloc函数分配内存,但是每次只会分配一块大小为256K的大块内存,不会调用free函数释放内存,将该内存块留在内存池中以便下次使用。
第0层:大内存-----若请求分配的内存大于256K,malloc函数分配内存,free函数释放内存。
第-1,-2层:操作系统进行操作