引言
梯度or进化
梯度下降和进化算法的比较:
在梯度下降中, 我们需要的只是梯度, 让这个神经网络的参数滑到梯度躺平的地方就好了, 因为梯度给你指明了一个优化的方向, 所以如果是监督学习, 优化起来会非常快. 而神经网络的进化, 使用的却是另一种手段. 用原始的点创造出很多新的点, 然后通过新的点来确定下一代的起点在哪. 这样的循环再不断地继续. 可以想象, 如果在监督学习中, 我们需要不断产生非常多新的网络, 测试新的网络, 这将比梯度法慢很多. 但是不使用梯度的方法还有一个好处, 那就是有效避免局部最优.
强化学习中采用进化算法的原因:
梯度下降的关键是计算合适的梯度,推动你向好的解决方案迈进。在监督学习中,通过标注数据集可以较轻松地获取「高质量梯度」。然而在强化学习中,你只有稀疏的奖励,毕竟随机的初始行为不会带来高回报,而奖励只有在几次动作之后才会出现。总之,分类和回归问题中的损失可以较好地代表需要近似的函数,而强化学习中的奖励往往不是好的代表。正由于强化学习中的梯度难以保证质量,Uber 和 OpenAI 最近采用进化算法来改善强化学习效果。
局部最优or全局最优
大家知道, 在梯度下降中, 神经网络很容易会走到一个局部最优, 但是如果是使用基于遗传算法的神经网络, 这个优化过程虽然慢, 我们的网络却可以随时跳出局部最优, 因为它完全不受梯度的限制. 而且除了监督学习, 我们还能用进化理论的神经网络做强化学习, 在这点上, 已经有最新的研究指出, 基于进化策略的神经网络完全有能力替代传统的基于梯度的强化学习方法.
神经进化
在遗传算法 (Genetic Algorithm) 中, 种群 Population 是通过不同的 DNA 配对, DNA 变异来实现物种的多样性, 然后通过自然选择 (Natural Selection), 繁衍下一代来实现 “适者生存, 不适者淘汰” 这条定律。在神经网络中,主要有以下几种尝试:
尝试1: 固定神经网络形态 (Topology), 改变参数 (weight)
通过不断尝试变异, 修改链接中间的 weight, 改变神经网络的预测结果, 保留预测结果更准确的, 淘汰不那么准确的. 在这方面, OpenAI 在2017年做出了一个有贡献的研究. 他们将进化策略 (Evolution Strategy) 衍生到神经网络, 然后不断进化神经网络中的参数. 他们的实验结果都能够媲美很多强化学习方法, 比如 Q-learning, Policy Gradient.
OpenAI 提出的能够替代强化学习的 ES 可以终结如下:
- 固定神经网络结构;
- 使用正态分布来扰动 (perturb) 神经网络链接参数;
- 使用扰动的网络在环境中收集奖励;
- 用奖励 (reward) 或者 效用 (utility) 来诱导参数更新幅度;
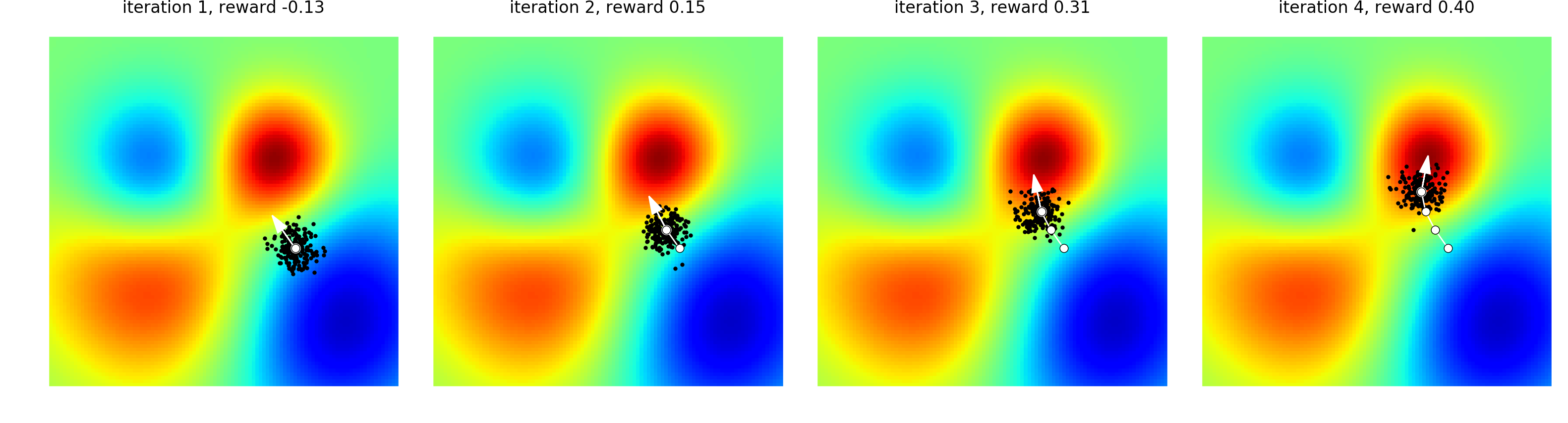
如果机器学习就是为了找到图中最红的地方, 那么 ES 就是在自己周围随机繁殖后代, 然后有些后代会靠近红色的地方, 有些不会. 那么我们就修改 ES 神经网络的参数, 让它更加像那些好后代的参数. 使用这种方式来越来越靠近红色.
尝试2: 修改参数 和 形态
典型算法:NEAT算法
NEAT 可以最小化结构. 换句话说如果你拿一个 50 层的神经网络训练, 但是要解决的问题很简单, 并不会用到那么复杂的神经网络, 越多的层结构也是一种浪费, 所以用 NEAT 来自己探索需要使用多少链接, 他就能忽略那些没用的链接, 所以神经网络也就比较小, 而且小的神经网络运行也快。
NEAT算法
NEAT 有几个关键步骤:
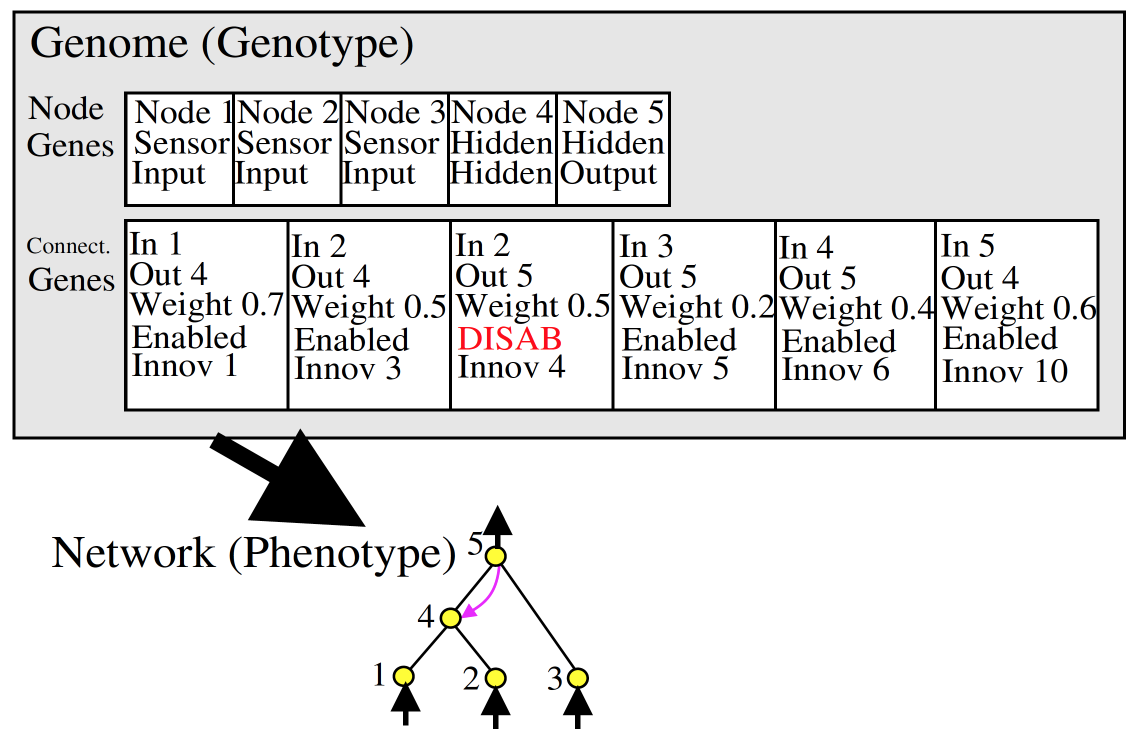
- 使用 创新号码 (Innovation ID) 对神经网络直接编码 (direct coding)
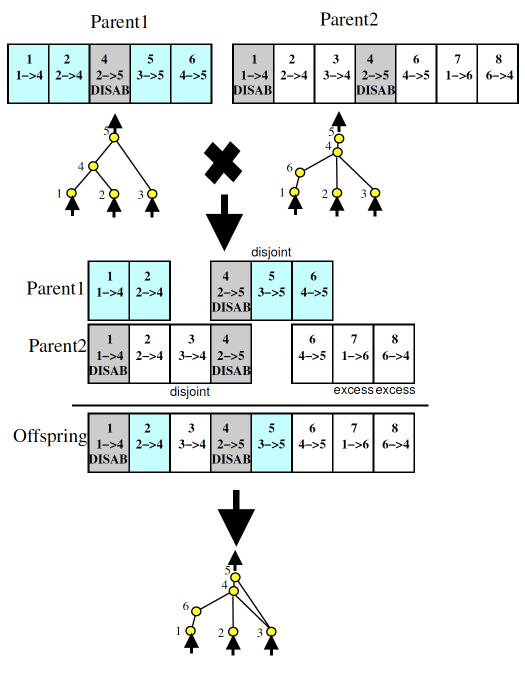
- 根据 innovation ID 进行 交叉配对 (crossover)
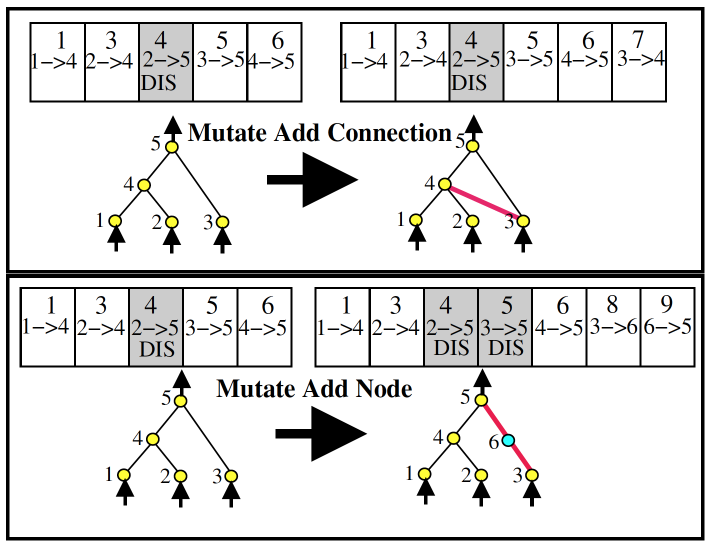
- 对 神经元 (node), 神经链接 (link) 进行 基因突变 (mutation)
- 尽量保留 生物多样性 (Speciation) (有些不好的网络说不定突然变异成超厉害的)
- 通过初始化只有 input 连着 output 的神经网络来尽量减小神经网络的大小 (从最小的神经网络结构开始发展)
参考网址:
莫烦python-神经进化
神经进化会成为深度学习的未来吗?