上一篇我们说到了Hystrix的请求熔断和服务降级,接下来我们说说Hystrix的请求缓存,线程隔离和请求合并。
Hystrix的隔绝策略分为两种:线程隔离和信号量隔离
线程隔离:Hystrix在用户请求和服务之间加入了线程池。Hystrix为每个依赖调用分配一个小的线程池,如果线程池已满调用将被立即拒绝,默认不采用排队.加速失败判定时间。线程数是可以被设定的。
原理:用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,如果线程池已满,则会进行降级处理,用户的请求不会被阻塞,至少可以看到一个执行结果(例如返回友好的提示信息),而不是无休止的等待或者看到系统崩溃。
@HystrixCommand(groupKey = “”, threadPoolKey = “”)
groupKey,threadPoolKey用于线程分组
信号量隔离:每次调用线程,当前请求通过计数信号量进行限制,当信号大于了最大请求数时,进行限制,调用fallback接口快速返回。
官网对信号量隔离的描述建议
Generally the only time you should use semaphore isolation for HystrixCommands is when the call is so high volume (hundreds per second, per instance) that the overhead of separate threads is too high; this typically only applies to non-network calls.
理解下两点:
- 隔离的细粒度太高,数百个实例需要隔离,此时用线程池做隔离开销过大
- 通常这种都是非网络调用的情况下
一般来说,只有当调用负载非常高时(例如每个实例每秒调用数百次)才需要使用信号量隔离,因为这种场景下使用线程隔离开销会比较高。信号量隔离一般仅适用于非网络调用的隔离。Hystrix中默认并且推荐使用线程隔离。
二者的比较
| 隔离策略 | 线程隔离 | 信号量隔离 |
|---|---|---|
| 线程 | HystrixCommand将会在单独的线程上执行 | HystrixCommand将会在调用线程上执行 |
| 开销 | 排队、调度、上下文开销等 | 无线程切换,开销低 |
| 异步 | 支持 | 不支持 |
| 并发支持 | 支持(最大线程池大小) | 支持(最大信号量上限) |
| 是否支持超时 | 支持,直接返回 | 不支持,如果阻塞,只能通过调用协议(如:socket超时才能返回) |
| 是否支持熔断 | 支持,当线程池到达maxSize后,再请求会触发fallback接口进行熔断 | 支持,当信号量达到maxConcurrentRequests后。再请求会触发fallback |
信号量:跟锁机制存在一定的相似性,semaphore也是一种锁机制,不同的是,reentrantLock是只允许一个线程获得锁,而信号量持有多个许可(permits),允许多个线程获得许可并执行。可以用来控制同时执行某个指定操作的数量。
我们模拟一下信号量
//假设线程数为29
int num = 29;
//信号量为5
Semaphore semaphore = new Semaphore(5);
for (int i = 0; i < num; i++) {
new Worker(i, semaphore).start();
}
Worker类
public class Worker extends Thread {
private int i;
private Semaphore semaphore;
public Worker(int i, Semaphore semaphore) {
this.i = i;
this.semaphore = semaphore;
}
@Override
public void run() {
try {
semaphore.acquire();
System.out.println("线程" + this.i + "占用机器生产");
Thread.sleep(3000);
semaphore.release();
System.out.println("线程" + this.i + "释放机器");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
程序运行之后我们发现同一时刻只会有5个线程占用机器进行生产,因为信号量限制只会有5台机器进行生产。
请求缓存。。。说实话这个功能比较鸡肋,为什么这么说呢?因为这个缓存是基于request的,因为每次请求来之前都必须HystrixRequestContext.initializeContext();进行初始化,每请求一次controller就会走一次filter,上下文又会初始化一次,前面缓存的就失效了,又得重新来。所以你如果想测缓存就必须在一次请求中访问两次,第二次会从缓存中拿,这里这个功能就不测了,因为实在比较鸡肋。
请求合并:把重复的请求批量的用一个HystrixCommand命令去执行,以减少通信消耗和线程数的占用,默认合并10ms内的请求
优点:减少了通信开销,
缺点:请求延迟增加
步骤:
1、自定义类继承HystrixCollapser类,去合并请求,合并成一个集合,并且返回各自的结果
2、继承HystrixCommand类,执行合并后的请求
3、初始化HystrixRequestContext,创建自定义类,传递查询条件
我们在进行请求合并之前先改造一下之前做过的eureka-client的代码,添加下面的方法,用来模拟请求合并。这里我们创建一个list集合来模拟合并请求返回的结果,后面会合并三个请求,所以这里封装三个数据。
@RequestMapping("/demo")
public List<String> demo(String id){
System.out.println(id);
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
return list;
}
第一步:自定义类继承HystrixCollapser类
点进源码我们可以看到三个泛型分别是批处理的返回类型,单个请求的返回类型,请求参数类型
HystrixCollapser<BatchReturnType, ResponseType, RequestArgumentType>
//合并请求
public class MergeCollapser extends HystrixCollapser<List<String>,String, Long> {
private Long id;
private RestTemplate restTemplate;
public MergeCollapser(Long id, RestTemplate restTemplate) {
//合并100ms内的请求,withTimerDelayInMilliseconds默认是10ms
super(Setter.withCollapserKey(HystrixCollapserKey.Factory.asKey("world"))
.andCollapserPropertiesDefaults(HystrixCollapserProperties.Setter().
withTimerDelayInMilliseconds(100)));
this.id = id;
this.restTemplate = restTemplate;
}
//返回请求参数
@Override
public Long getRequestArgument() {
return id;
}
//合并条件
@Override
protected HystrixCommand<List<String>> createCommand(Collection<CollapsedRequest<String, Long>> collection) {
List<Long> ids = new ArrayList<>(collection.size());
//将请求参数封装
for (CollapsedRequest<String, Long> request : collection){
ids.add(request.getArgument());
}
//将参数传入Command类,由Command类执行合并后的请求
Command command = new Command("hello",restTemplate,ids);
return command;
}
//返回各自的请求结果
@Override
protected void mapResponseToRequests(List<String> results, Collection<CollapsedRequest<String, Long>> collection) {
int count = 0;
for (CollapsedRequest<String, Long> request : collection) {
String result = results.get(count++);
request.setResponse(result);
}
}
}
第二步:继承HystrixCommand类,执行合并后的请求
//执行合并的请求
public class Command extends HystrixCommand<List<String>> {
private RestTemplate restTemplate;
private List<Long> ids;
protected Command(String groupKey, RestTemplate restTemplate, List<Long> ids) {
super(HystrixCommandGroupKey.Factory.asKey(groupKey));
this.restTemplate = restTemplate;
this.ids = ids;
}
@Override
protected List<String> run() throws Exception {
System.out.println("参数为:" + ids.toString() + "--" + Thread.currentThread().getName());
String[] result = restTemplate.getForEntity("http://eureka-client/demo?id={1}", String[].class, StringUtils.join(ids, ",")).getBody();
return Arrays.asList(result);
}
}
StringUtils.join(ids, “,”)的意思是将ids集合转成一个字符串,用’,'连接
比如说ids集合是[1,2,3],转成的字符串就是"1,2,3",传过去的参数就是合并后的参数“1,2,3”,客户端对参数进行split操作,可以得到每一次传递的参数,进行数据库操作,这里为了方便我们在客户端是直接返回一个list集合,没有连接数据库,感兴趣的小伙伴可以自己研究。
controller层面:
@RequestMapping("/merge")
public String merge() throws ExecutionException, InterruptedException {
//进行初始化操作,不加这个会报错
HystrixRequestContext context = HystrixRequestContext.initializeContext();
MergeCollapser mergeCollapser1 = new MergeCollapser(1L,restTemplate);
MergeCollapser mergeCollapser2 = new MergeCollapser(2L,restTemplate);
MergeCollapser mergeCollapser3 = new MergeCollapser(3L,restTemplate);
Future<String> future1 = mergeCollapser1.queue();
Future<String> future2 = mergeCollapser2.queue();
//让mergeCollapser3睡2s,会错过我们设置的100ms合并的时间
//就会合并到下一次请求中
Thread.sleep(2000);
Future<String> future3 = mergeCollapser3.queue();
System.out.println(future1.get());
System.out.println(future2.get());
System.out.println(future3.get());
return null;
}
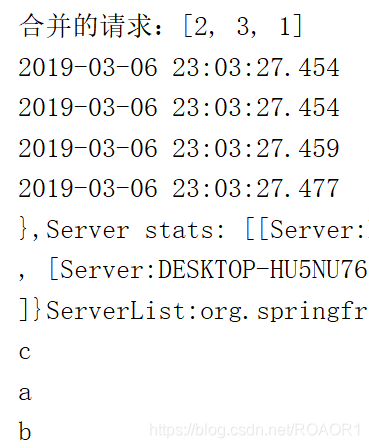
返回结果

下面使用注解的方式进行请求合并:
//用来进行接收参数,将参数传递给getMerge
@HystrixCollapser(batchMethod = "getMerge", collapserProperties = {@HystrixProperty(name = "timerDelayInMilliseconds", value = "200")})
public Future<String> merge(Long id){
return null;
}
//getMerge方法合并参数,接着发送请求
@HystrixCommand
public List<String> getMerge(List<Long> ids){
System.out.println("合并的请求:"+ids.toString());
String[] result = restTemplate.getForEntity("http://eureka-client/demo?id={1}",String[].class,StringUtils.join(ids,",")).getBody();
return Arrays.asList(result);
}
controller中调用
@RequestMapping("/merge2")
public String merge3() throws ExecutionException, InterruptedException {
HystrixRequestContext context = HystrixRequestContext.initializeContext();
Future<String> future1 = mergeService.merge(1L);
Future<String> future2 = mergeService.merge(2L);
Future<String> future3 = mergeService.merge(3L);
System.out.println(future1.get());
System.out.println(future2.get());
System.out.println(future3.get());
return null;
}
请求结果
最后附上Hystrix的属性介绍
https://www.cnblogs.com/duan2/p/9302431.html