服务降级
在继承HystrixCommand时,通过重写getFallback()方法来实现服务的降级处理逻辑,当run()执行过程中出现错误、超时、线程池拒绝、断路器熔断等情况时会执行此方法内的逻辑。具体代码在上面可以找到。
在继承HystrixObservableCommand时,通过重写resumeWithFallback()方法来实现服务降级逻辑,该方法会返回Observable对象,当命令执行失败时,Hystrix会将Observable中的结果通知给所有订阅者。
若通过注解实现服务降级则只需要使用@HystrixCommand中的fallbackMethod参数来指定具体的服务降级实现方法。
@HystrixCommand(fallbackMethod = "helloFallback")
public String hello() {
String result = restTemplate.getForEntity("http://HELLO-SERVICE/hello", String.class).getBody();
return result;
}
public String helloFallback() {
return "error";
}注意Hystrix命令与fallback实现方法必须在一个类中,并且fallbackMethod的值必须与实现fallback方法的名字相同,对于该方法额访问修饰符没有要求,private、protected、public都可以。
下面看一个例子:
@HystrixCommand(fallbackMethod = "defaultfallback")
public String test() {
String result = restTemplate.getForEntity("http://HELLO-SERVICE/hello", String.class).getBody();
return result;
}
@HystrixCommand(fallbackMethod = "defaultfallbackSec")
private String defaultfallback() {
//可能这个方法依然也有网络请求
String result = restTemplate.getForEntity("http://HELLO-SERVICE/hello", String.class).getBody();
return result;
}
private String defaultfallbackSec() {
return "error";
}
如果fallbackMethod指定的方法并不是一个稳定的逻辑,它依然可能发生异常,那么我们也可以为它添加@HystrixCommand注解并通过fallbackMethod指定服务降级逻辑,直到服务降级逻辑是一个稳定逻辑为止。
大多数情况下我们需要为可能失败的Hystrix命令实现服务降级逻辑,但也有一些情况不需要去实现降级逻辑,如:
执行写操作的命令:当Hystrix命令是执行写操作而不是返回一些信息时,这类操作的返回类型一般是void或者是空的Observable,实现服务降级的意义不是很大,当操作失败时我们只需要通知调用者即可。
执行批处理或离线计算的命令:当Hystrix命令是用来执行批处理程序生成报告或进行离线技术时,通常只需要将错误传播给调用者让调用者稍后重试而不是发送给调用者一个静默的降级处理响应。
异常处理
扫描二维码关注公众号,回复: 3001088 查看本文章
异常传播
在HystrixCommand实现的run()方法中抛出异常时,除了HystrixBadRequestException之外,其它异常都会被Hystrix认为命令执行失败并触发服务降级的处理逻辑,所以当需要在命令执行中抛出不触发服务降级的异常时来使用它。
在使用注解实现Hystrix命令时可以通过设置@HystrixCommand注解的ignoreExceptions参数来指定忽略的异常类型。
/**
* 当设置ignoreExceptions参数时,
* 抛出对应的异常就不会触发降级(也就是不会调用failMethod()方法).
*/
@HystrixCommand(
ignoreExceptions = {NullPointerException.class, ArithmeticException.class},
fallbackMethod = "failMethod"
)
public String getUserName(Long id) {
Long re = id/0; //会抛ArithmeticException
String param = null;
param.trim(); // 此处会抛NullPointException
return "张三";
}
private String failMethod(Long id, Throwable e) {
return e.getMessage();
}异常获取
通过继承实现的Hystrix命令中,可以在getFallback()方法中通过Throwable getExecutionException()方法来获取具体的异常。
@Override
protected User getFallback() {
Throwable ex = getFailedExecutionException();
System.out.println(ex.getMessage());
return new User("error",0);
}通过注解实现的Hystrix命令,只需要在fallback实现方法的参数中增加Throwable e对象的定义就可。
private String failMethod(Long id, Throwable e) {
return e.getMessage();
}命名名称、分组以及线程池划分
以继承方式实现的Hystrix命令使用类名作为默认的命名名称,我们也可以在构造方法中通过Setter静态类来设置。
public UserCommand() {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("GroupName"))
.andCommandKey(HystrixCommandKey.Factory.asKey("CommandName")));
}从上面Setter的使用可以看到,我们没有直接设置命令名称,而是先调用了withGroupKey来设置命令组名,然后调用andCommandKey来设置命令名。这是因为在Setter的定义中,只有withGroupKey静态函数可以创建Setter实例,所以GroupKey是每个Setter必须的参数,CommandKey是一个可选的参数。
那么为什么要设置命令组呢?因为命令组可以实现统计(仪表盘),且Hystrix命令默认的线程划分是根据命令组来实现的。默认情况下,Hystrix会让相同组名的命令使用同一个线程池,所以我们需要在创建Hystrix命令时为其指定命令组名来实现默认的线程池划分。
如果只使用命令组来分配线程池则不够灵活,所以Hystrix还提供了HystrixThreadPoolKey来对线程池进行设置,来实现更细粒度的线程池划分。
public UserCommand() {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("GroupName"))
.andCommandKey(HystrixCommandKey.Factory.asKey("CommandName"))
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("ThreadPoolKey")));
}如果没有指定HystrixThreadPoolKey,依然会使用命令组的方式来划分线程池。通常情况下尽量通过HystrixThreadPoolKey的方式来指定线程池的划分,而不是通过组名的默认方式实现划分。
使用注解设置命令名称、分组以及线程池划分可以通过指定commandKey、groupKey和threadPoolKey属性来设置,它们分别代表了命令名称、分组以及线程池划分。
@HystrixCommand(commandKey="userCommand",groupKey="userGroup",threadPoolKey="userThread")
public String hello3() {
User user = restTemplate.getForObject("http://HELLO-SERVICE/user2?name={1}&age={2}", User.class, "xiaogang",
12);
return user.toString();
}请求缓存
Hystrix提供了请求缓存的功能,在高并发的场景下,我们可以方便的开启和使用请求缓存来优化系统,达到减轻高并发时的请求线程消耗、降低请求响应时间的效果。
开启请求缓存功能
通过继承的方式实现Hystrix请求缓存很简单,只需要在实现HystrixCommand或者HystrixObservableCommand时,重写getCacheKey()方法来开启请求缓存。比如
public class UserCommand extends HystrixCommand<User> {
private RestTemplate restTemplate;
private String name;
private int age;
public UserCommand(RestTemplate restTemplate, String name, int age) {
super(HystrixCommandGroupKey.Factory.asKey("exampleGroup"));
this.restTemplate = restTemplate;
this.name = name;
this.age = age;
}
@Override
protected User run() throws Exception {
User user = restTemplate.getForObject("http://HELLO-SERVICE/user2?name={1}&age={2}", User.class, name, age);
return user;
}
/**
* 降级。Hystrix会在run()执行过程中出现错误、超时、线程池拒绝、断路器熔断等情况时, 执行getFallBack()方法内的逻辑
*/
@Override
protected User getFallback() {
return new User("error", 0);
}
/**
* 开启缓存 不能返回null值
*/
@Override
protected String getCacheKey() {
return name;
}
}在上面的例子中,我们通过getCacheKey()方法中返回的请求缓存key值(使用了传入的获取User对象的name值,不可以返回null值),就能让该请求命令具备缓存功能。此时当不同的外部请求处理逻辑调用了同一个依赖服务时,Hystrix会根据getCacheKey方法返回的值来区分是否是重复的请求,如果它们的cacheKey相同(这里name就是cacheKey),那么该依赖服务只会在第一个请求到达时被真实的调用一次,其余的请求直接从缓存中返回结果,所以通过开启请求缓存key有以下几个好处:
- 减少重复的请求数,降低依赖服务的并发度。
- 在同一用户请求的上下文中,相同依赖服务的返回数据始终保持一致。
- 请求缓存在run()和construct()执行之前生效,所以可以有效减少不必要的线程开销。
注意:这里大家可能有一个误解,可能会把Hystrix的请求缓存当作和Redis缓存一样的概念,就是如果数据存到缓存了,那么任意用户再次请求时都会在缓存中取出数据,其实并不是这样,Hystrix缓存仅限于当前线程内如果重复调用相同的服务依赖会返回缓存的数据,看下面的测试代码:
@Test
public void testCacheDemo() {
//初始化context
HystrixRequestContext context = HystrixRequestContext.initializeContext();
try {
User user = new UserCommand(restTemplate, "test1", 1).execute();
User user2 = new UserCommand(restTemplate, "test1", 1).execute();
User user3 = new UserCommand(restTemplate, "test2", 1).execute();
System.out.println(user.toString());
System.out.println(user2.toString());
System.out.println(user3.toString());
} catch (Exception e) {
e.printStackTrace();
}finally {
context.shutdown();
}
}Hystrix缓存是在同一个context内有效的,在上面的例子里user2会使用user的缓存,所以不需要重新请求依赖服务,user3需要重新请求依赖服务,因为它的name和user的不一样(这里用的name做的cacheKey)。而且,当你再次调用这个测试方法时,Hystrix还是会去调用依赖服务的,因为已经不是在同一个context了,所以这里要把和Redis这类缓存的概念区分开来。这么一看感觉缓存这个功能貌似还是有点不如意,毕竟同一个请求内多次调用同一个依赖服务的几率还是低的。
另外,在执行命令之前先要先初始化请求上下文,就是第一行代码,如果没有这行代码会报错:
Caused by: java.lang.IllegalStateException: Request caching is not available. Maybe you need to initialize the HystrixRequestContext?
只要报这个错就看看你的代码是否初始化了HystrixRequestContext。
当然上述代码是测试环境的写法,Web项目是使用过滤器来初始化请求上下文的。
import com.netflix.hystrix.strategy.concurrency.HystrixRequestContext;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import java.io.IOException;
@WebFilter(filterName = "hystrixRequestContextServletFilter",urlPatterns = "/*",asyncSupported = true)
public class HystrixRequestContextServletFilter implements Filter {
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
HystrixRequestContext context = HystrixRequestContext.initializeContext();
try {
chain.doFilter(request, response);
} finally {
context.shutdown();
}
}
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void destroy() {
}
}所以每次向Controller发起请求都会走这个过滤器,重新生成一个context,在不同context中的缓存是不共享的,还有这个request内部一个ThreadLocal,所以request只能限于当前线程。
关于Spring Boot添加过滤器可以参考这篇博文:https://www.cnblogs.com/begin2016/p/8947887.html
清理失效缓存功能
使用请求缓存时,如果只是读操作,那么不需要考虑缓存内容是否正确的问题,但是如果请求命令中有更新数据的写操作,那么缓存中的数据就需要我们在进行写操作时进行及时处理,以防止读操作的请求命令获取到了失效的数据。
在Hystrix中,我们可以通过HystrixRequestCache.clear()方法进行缓存的清理。如下所示,模拟一个读操作和写操作:
public class UserGetCommand extends HystrixCommand<User> {
private static final HystrixCommandKey GETTER_KEY = HystrixCommandKey.Factory.asKey("CommandName");
private RestTemplate restTemplate;
private String name;
private int age;
public UserGetCommand(RestTemplate restTemplate, String name, int age) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("GetSetGet")).andCommandKey(GETTER_KEY));
this.restTemplate = restTemplate;
this.name = name;
this.age = age;
}
@Override
protected User run() throws Exception {
User user = restTemplate.getForObject("http://HELLO-SERVICE/user2?name={1}&age={2}", User.class, name, age);
return user;
}
/**
* 降级。Hystrix会在run()执行过程中出现错误、超时、线程池拒绝、断路器熔断等情况时, 执行getFallBack()方法内的逻辑
*/
@Override
protected User getFallback() {
return new User("error", 0);
}
/**
* 开启缓存
*/
@Override
protected String getCacheKey() {
// TODO Auto-generated method stub
return name;
}
/**
* 清理缓存
* @param name 这里当做cacheKey
*/
public static void flushCache(String name) {
HystrixRequestCache.getInstance(GETTER_KEY, HystrixConcurrencyStrategyDefault.getInstance()).clear(name);
}
}public class UserPostCommand extends HystrixCommand<String> {
private RestTemplate restTemplate;
private String name;
private int age;
public UserPostCommand(RestTemplate restTemplate, String name, int age) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("GetSetGet")));
this.restTemplate = restTemplate;
this.name = name;
this.age = age;
}
@Override
protected String run() throws Exception {
String user = restTemplate.postForObject("http://HELLO-SERVICE/user4", new User(name,age), String.class);
// 清理缓存
UserGetCommand.flushCache(name);
return user;
}
/**
* 降级。Hystrix会在run()执行过程中出现错误、超时、线程池拒绝、断路器熔断等情况时, 执行getFallBack()方法内的逻辑
*/
@Override
protected String getFallback() {
return "error";
}
}该示例中UserGetCommand请求命令用于根据name获取对象(实际上应该以id为cacheKey,这里只是介绍使用,就不尽善尽美了),而UserPostCommand用于更新User对象,所以我们必须为UserPostCommand命令实现缓存的清理,以保障User被更新后,Hystrix请求缓存中相同缓存key的结果被移除,这样下一次获取User时就不会再从缓存中取出已过期的未更新结果。
@Test
public void testCacheRemove() {
//初始化context
HystrixRequestContext context = HystrixRequestContext.initializeContext();
try {
User user1 = new UserGetCommand(restTemplate, "test1", 1).execute();
// 清理缓存之前 把age变成了2查看效果
User user2 = new UserGetCommand(restTemplate, "test1", 2).execute();
// 清理缓存
String user3 = new UserPostCommand(restTemplate, "test1", 2).execute();
// 清理缓存后 把age变成了2查看效果
User user4 = new UserGetCommand(restTemplate, "test1", 2).execute();
System.out.println(user1.toString());
System.out.println(user2.toString());
System.out.println(user3);
System.out.println(user4.toString());
} catch (Exception e) {
e.printStackTrace();
}finally {
context.shutdown();
}
}工作原理
getCacheKey()方法是在AbstractCommand内继承而来:
protected String getCacheKey() {
return null;
}
protected boolean isRequestCachingEnabled() {
return properties.requestCacheEnabled().get() && getCacheKey() != null;
}
通过AbstractCommand源码看到,如果不重写getCacheKey方法,让它返回一个非null值,那么缓存功能不会开启,同时请求命令的缓存开启属性也需要设置为true才能开启(该属性默认为true,可以通过该属性强制关闭缓存)。
public Observable<R> toObservable() {
// 尝试在缓存获取结果
final boolean requestCacheEnabled = isRequestCachingEnabled();
final String cacheKey = getCacheKey();
/* try from cache first */
if (requestCacheEnabled) {
HystrixCommandResponseFromCache<R> fromCache = (HystrixCommandResponseFromCache<R>) requestCache.get(cacheKey);
if (fromCache != null) {
isResponseFromCache = true;
return handleRequestCacheHitAndEmitValues(fromCache, _cmd);
}
}
Observable<R> hystrixObservable =
Observable.defer(applyHystrixSemantics)
.map(wrapWithAllOnNextHooks);
Observable<R> afterCache;
// put in cache 加入缓存
if (requestCacheEnabled && cacheKey != null) {
// wrap it for caching
HystrixCachedObservable<R> toCache = HystrixCachedObservable.from(hystrixObservable, _cmd);
HystrixCommandResponseFromCache<R> fromCache = (HystrixCommandResponseFromCache<R>) requestCache.putIfAbsent(cacheKey, toCache);
if (fromCache != null) {
// another thread beat us so we'll use the cached value instead
toCache.unsubscribe();
isResponseFromCache = true;
return handleRequestCacheHitAndEmitValues(fromCache, _cmd);
} else {
// we just created an ObservableCommand so we cast and return it
afterCache = toCache.toObservable();
}
} else {
afterCache = hystrixObservable;
}
return afterCache
.doOnTerminate(terminateCommandCleanup) // perform cleanup once (either on normal terminal state (this line), or unsubscribe (next line))
.doOnUnsubscribe(unsubscribeCommandCleanup) // perform cleanup once
.doOnCompleted(fireOnCompletedHook);
}
});
}尝试获取缓存:Hystrix命令在执行前先根据 isRequestCachingEnabled()方法判断是否开启了缓存,如果开启了缓存并且重写了getCacheKey方法并且返回了非null的缓存key值,那么就用返回的key值去调用HystrixRequestCache中的get(String cacheKey)来获取缓存的HystrixCache的Observable对象。
将请求结果加入缓存:在执行命令缓存操作之前,我们已经获得了一个延迟执行的命令结果对象hystrixObservable。接下来依然是先判断是否开启了缓存,如果开启了缓存就将hystrixObservable对象包装成请求缓存结果HystrixCachedObservable的实例对象toCache,然后将其放入当前命令的缓存对象中。在缓存对象HystrixRequestCache中维护了一个线程安全的Map来保存请求缓存的响应。
使用注解实现请求缓存

设置请求缓存:添加@CacheResult注解即可,当依赖服务被调用并返回User对象时,由于该方法被@CacheResult注解修改,所以Hystrix会将该结果置入请求缓存中,而它的缓存key值会使用所有的参数。
@CacheResult
@HystrixCommand
public User getUser(String name,int age){
User user = restTemplate.getForObject("http://HELLO-SERVICE/user2?name={1}&age={2}", User.class, name, age);
return user;
}定义缓存Key:key使用@CacheResult和@CacheRemove注解的cacheKeyMethod方法来指定具体的生成函数,也可以通过@CacheKey注解在方法参数中指定用于组装缓存Key的元素。
@CacheResult(cacheKeyMethod="getCacheKey")
@HystrixCommand
public User getUser(String name,int age){
User user = restTemplate.getForObject("http://HELLO-SERVICE/user2?name={1}&age={2}", User.class, name, age);
return user;
}
private String getCacheKey(String name){
return name;
}通过@CacheKey更加简单,但是它的优先级比cacheKeyMethod低,如果已经使用了cacheKeyMethod,则@CacheKey不会生效。@CacheKey除了指定参数为key值外还可以指定对象的属性来作为key。
@CacheResult
@HystrixCommand
public User getUser2(@CacheKey("name")String name,int age){
User user = restTemplate.getForObject("http://HELLO-SERVICE/user2?name={1}&age={2}", User.class, name, age);
return user;
}
@CacheResult
@HystrixCommand
public User getUser2(@CacheKey("name")User user){
User user = restTemplate.getForObject("http://HELLO-SERVICE/user2?name={1}&age={2}", User.class, user.getName(), user.getAge());
return user;
}缓存清理:使用@CacheRemove注解来实现失效缓存的清理。
/**
* @CacheResult开启请求缓存 cacheKeyMethod = "getCacheKey"指定获取cacheKey的回调方法
* 此时@CacheKey不生效 (优先级比cacheKeyMethod低)
* @param name
* @param age
* @return
*/
@CacheResult(cacheKeyMethod = "getCacheKey")
@HystrixCommand(commandKey = "getUserByName", groupKey = "userGroup", threadPoolKey = "userThread")
public User getUser2(@CacheKey("name") String name, int age) {
User user = restTemplate.getForObject("http://HELLO-SERVICE/user2?name={1}&age={2}", User.class, name, age);
return user;
}
/**
* @CacheRemove清空缓存
* @param name
* @param age
* @return
*/
@CacheRemove(commandKey = "getUserByName", cacheKeyMethod = "getUserCacheKey")
@HystrixCommand(commandKey = "getUserByName", groupKey = "userGroup", threadPoolKey = "userThread")
public String updateUser(@CacheKey("name") User user) {
return restTemplate.postForObject("http://HELLO-SERVICE/user4", user, String.class);
}
private String getCacheKey(String name, int age) {
return name;
}
private String getUserCacheKey(User user) {
return user.getName();
}@CacheRemove的commandKey属性必须指定,它用来指定需要使用请求缓存的请求命令,只有通过该属性的配置,Hystrix才能找到正确的请求命令缓存位置。
注意:cacheKeyMethod指定的方法的参数列表必须与@HystrixCommand注解修饰的方法的参数列表相同,否则会报错找不到方法。
关于使用@CacheKey注解会报这个错:
java.beans.IntrospectionException: Method not found: isName
暂时还未找到原因,等我找到原因再来告诉大家。
请求合并
微服务架构中的依赖通常通过远程调用实现,而远程调用最常见的问题就是通信消耗与连接数占用。在高并发情况下,因通信次数增多,将出现排队等待与响应延迟的情况。为了优化这两个问题,Hystrix提供了HystrixCollapser来实现请求的合并,以减少通信消耗的线程数的占用。
HystrixCollapser实现了在HystrixCommand之前放置一个合并处理器,将处于一个很短的时间窗(默认10ms)内对同一依赖服务的多个请求进行整合并以批量方式发起请求的功能(服务提供方也需要提供相应的批量实现接口)。通过HystrixCollapser的封装,开发者不需要关注线程合并的细节过程,只需关注批量化服务和处理。
public abstract class HystrixCollapser<BatchReturnType, ResponseType, RequestArgumentType> implements HystrixExecutable<ResponseType>, HystrixObservable<ResponseType> {
public abstract RequestArgumentType getRequestArgument();
protected abstract HystrixCommand<BatchReturnType> createCommand(Collection<CollapsedRequest<ResponseType, RequestArgumentType>> requests);
protected abstract void mapResponseToRequests(BatchReturnType batchResponse, Collection<CollapsedRequest<ResponseType, RequestArgumentType>> requests);
}从HystrixCollapser抽象类的定义来看,它指定了三个不同的类型。
BatchReturnType:合并后批量请求的返回类型。
ResponseType:单个请求返回的类型。
RequestArgumentType:请求参数类型。
而对于这三个类型的使用可以在它的三个抽象方法中看。
RequestArgumentType getRequestArgument():该方法用来定义获取请求参数的方法。
createCommand(Collection<CollapsedRequest<ResponseType, RequestArgumentType>> requests):合并请求产生批量命令的具体实现方法。
mapResponseToRequests(BatchReturnType batchResponse, Collection<CollapsedRequest<ResponseType, RequestArgumentType>> requests):批量命令结果返回后的处理,这里需要实现将批量结果拆分并传递给合并前的各个原子请求命令的逻辑。
接下来,我们通过一个简单示例来理解实现请求合并的过程。
假设当前微服务HELLO-SERVICE提供了两个获取User的接口。
/collapse/users/{id}:根据id返回User对象的GET请求接口。
/collapse/users?ids={ids}:根据ids返回User对象列表的GET请求接口,其中ids为以逗号分隔的id集合。
在服务消费端,为上面两个接口通过RestTemplate实现简单的调用。
@Service("userService")
public class UserService {
@Autowired
private RestTemplate restTemplate;
public User findById(int id) {
return restTemplate.getForObject("http://HELLO-SERVICE/collapse/user/{1}", User.class, 1);
}
public List<User> findAll(List<Integer> ids) {
return restTemplate.getForObject("http://HELLO-SERVICE/collapse/user/{1}", List.class,
StringUtils.join(ids, ","));
}
}接下来,我们实现将短时间内多个获取单一User对象的请求命令进行合并。
第一步,为请求合并的实现准备一个批量请求命令的实现,
批量请求命令实际上就是一个简单的HystrixCommand实现,从上面的实现中可以看到它通过调用userService.finAll方法来访问/collapse/users?ids={ids}接口以返回User的列表结果。
第二步,通过继承HystrixCollapser实现请求合并器:
public class UserCollapseCommand extends HystrixCollapser<List<User>, User, Integer> {
private UserService userService;
private Integer id;
public UserCollapseCommand(com.wya.springboot.collapse.UserService userService, Integer id) {
super(Setter.withCollapserKey(HystrixCollapserKey.Factory.asKey("userCollapseCommand"))
.andCollapserPropertiesDefaults(HystrixCollapserProperties.Setter().withTimerDelayInMilliseconds(100)));
this.userService = userService;
this.id = id;
}
@Override
public Integer getRequestArgument() {
// TODO Auto-generated method stub
return id;
}
/**
* @param requests
* 保存了延迟时间窗中收集到的所有获取单个User的请求。通过获取这些请求的参数来组织
* 我们准备的批量请求命令UserBatchCommand实例
* @return
*/
@Override
protected HystrixCommand<List<User>> createCommand(
Collection<com.netflix.hystrix.HystrixCollapser.CollapsedRequest<User, Integer>> requests) {
List<Integer> ids = new ArrayList<Integer>(requests.size());
ids.addAll(requests.stream().map(CollapsedRequest::getArgument).collect(Collectors.toList()));
return new UserBatchCommand(userService, ids);
}
/**
* 在批量请求命令UserBatchCommand实例被触发执行完成后,该方法开始执行,
* 在这里我们通过批量结果batchResponse对象,为collapsedRequests中每个合并前的单个请求设置返回结果。
* 来完成批量结果到单个请求结果的转换
* @param batchResponse 保存了createCommand中组织的批量请求命令的返回结果
* @param collapsedRequests 代表了每个合并的请求
*/
@Override
protected void mapResponseToRequests(List<User> batchResponse,
Collection<com.netflix.hystrix.HystrixCollapser.CollapsedRequest<User, Integer>> requests) {
// TODO Auto-generated method stub
System.out.println("mapResponseToRequests========>");
int count = 0;
for(CollapsedRequest<User, Integer> collapsedRequest : requests) {
User user = batchResponse.get(count++);
collapsedRequest.setResponse(user);
}
}
}
在上面的构造函数中,我们为请求合并器设置了时间延迟属性,合并器会在该时间窗内收集获取单个User请求并在时间窗结束时进行合并组装成单个批量请求。getRequestArgument方法返回给定的单个请求参数id。
createCommand:该方法的requests参数中保存了延迟时间窗中收集到的所有获取单个User的请求,通过获取这些请求的参数来组织我们准备的批量请求命令UserBatchCommand实例。
mapResponseToRequests:在批量请求命令UserBatchCommand实例被触发执行完成之后,该方法开始执行,其中batchResponse参数保存了createCommand中组织请求命令的返回结果,而requests参数代表了每个请求合并的请求。在这里我们通过遍历批量结果batchResponse对象,为requests中每一个合并前的单个请求设置返回结果,以此完成批量结果到单个请求结果的转换。
下图展示了未使用HystrixCollapser请求合并器之前的使用情况。可以看到当服务消费者同时对HELLO-SERVICE的/user/{id}接口发起五个请求时,会向该依赖服务的独立线程池申请五个线程了完成各自的请求操作。
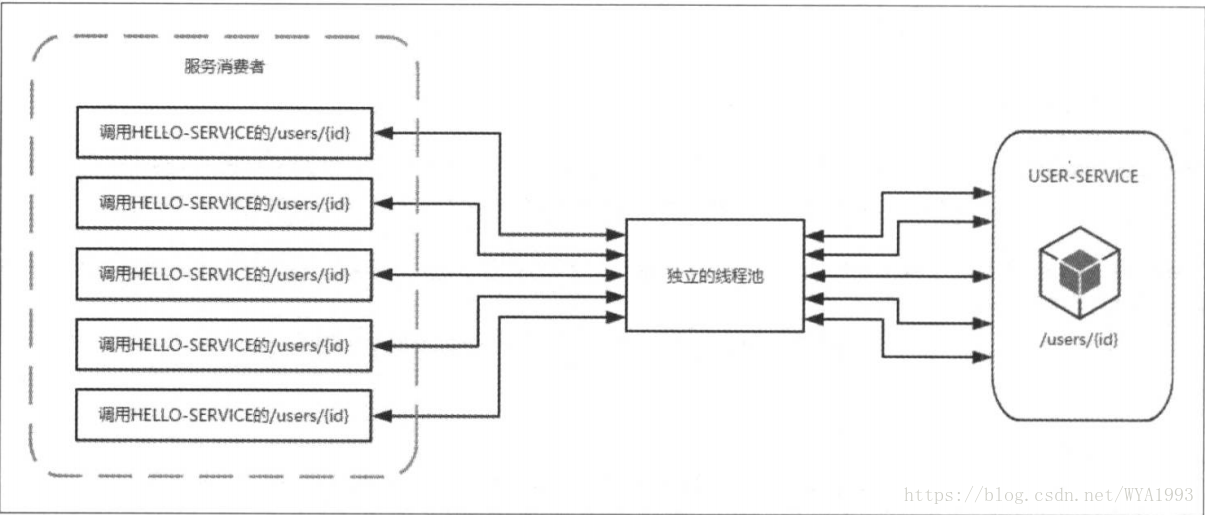
当使用了HystrixCollapser请求合并器后,会将这五个请求拦截并在合并器组合成一个批量请求,只用一个线程就可以了,所以在资源有效且短时间内会产生高并发请求的时候,为避免连接不够用而引起的延迟可以考虑使用请求合并器的方式来处理。
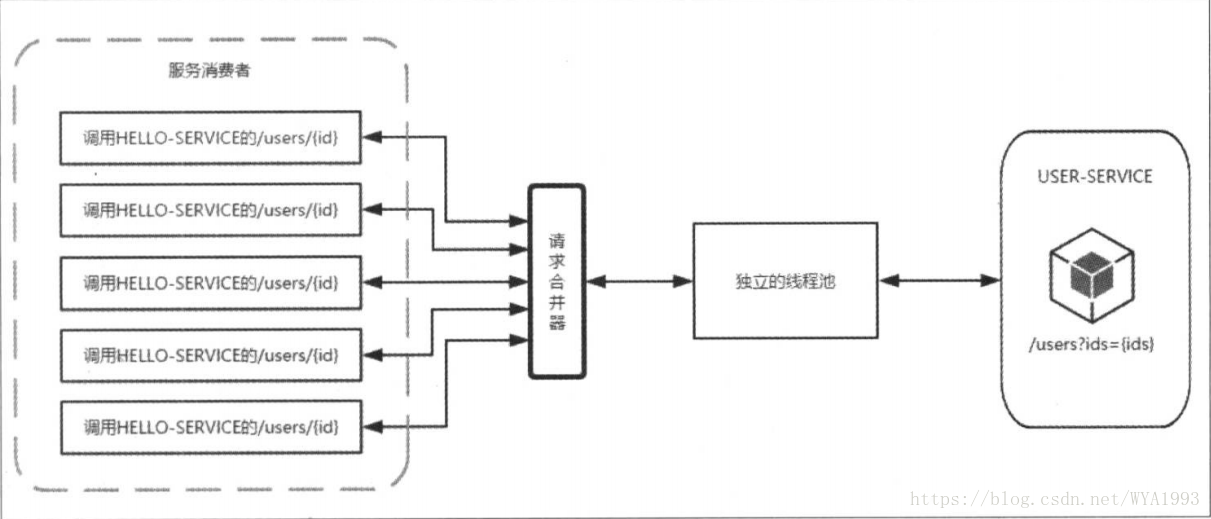
使用注解实现请求合并