微服务架构中的依赖通常通过远程调用实现,而远程调用最常见的问题就是通信消耗与连接数占用。在高并发情况下,因通信次数增多,将出现排队等待与响应延迟的情况。为了优化这两个问题,Hystrix提供了HystrixCollapser来实现请求的合并,以减少通信消耗的线程数的占用。
HystrixCollapser实现了在HystrixCommand之前放置一个合并处理器,将处于一个很短的时间窗(默认10ms)内对同一依赖服务的多个请求进行整合并以批量方式发起请求的功能(服务提供方也需要提供相应的批量实现接口)。通过HystrixCollapser的封装,开发者不需要关注线程合并的细节过程,只需关注批量化服务和处理。
public abstract class HystrixCollapser<BatchReturnType, ResponseType, RequestArgumentType> implements HystrixExecutable<ResponseType>, HystrixObservable<ResponseType> {
public abstract RequestArgumentType getRequestArgument();
protected abstract HystrixCommand<BatchReturnType> createCommand(Collection<CollapsedRequest<ResponseType, RequestArgumentType>> requests);
protected abstract void mapResponseToRequests(BatchReturnType batchResponse, Collection<CollapsedRequest<ResponseType, RequestArgumentType>> requests);
}从HystrixCollapser抽象类的定义来看,它指定了三个不同的类型。
- BatchReturnType:合并后批量请求的返回类型。
- ResponseType:单个请求返回的类型。
- RequestArgumentType:请求参数类型。
而对于这三个类型的使用可以在它的三个抽象方法中看。
- RequestArgumentType getRequestArgument():该方法用来定义获取请求参数的方法。
- createCommand(Collection<CollapsedRequest<ResponseType, RequestArgumentType>> requests):合并请求产生批量命令的具体实现方法。
- mapResponseToRequests(BatchReturnType batchResponse, Collection<CollapsedRequest<ResponseType, RequestArgumentType>> requests):批量命令结果返回后的处理,这里需要实现将批量结果拆分并传递给合并前的各个原子请求命令的逻辑。
接下来,我们通过一个简单示例来理解实现请求合并的过程。
通过继承实现请求合并
假设当前微服务HELLO-SERVICE提供了两个获取User的接口。
/collapse/users/{id}:根据id返回User对象的GET请求接口。
/collapse/users?ids={ids}:根据ids返回User对象列表的GET请求接口,其中ids为以逗号分隔的id集合。
在服务消费端,为上面两个接口通过RestTemplate实现简单的调用。
@Service("userService")
public class UserService {
@Autowired
private RestTemplate restTemplate;
public User findById(int id) {
return restTemplate.getForObject("http://HELLO-SERVICE/collapse/users/{1}", User.class, 1);
}
public List<User> findAll(List<Integer> ids) {
return restTemplate.getForObject("http://HELLO-SERVICE/collapse/users?ids={1}", List.class,
StringUtils.join(ids, ","));
}
}接下来,我们实现将短时间内多个获取单一User对象的请求命令进行合并。
第一步,为请求合并的实现准备一个批量请求命令的实现。
public class UserBatchCommand extends HystrixCommand<List<User>> {
private UserService UserService;
private List<Integer> ids;
protected UserBatchCommand(UserService UserService,List<Integer> ids) {
super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("userServiceGroup"))
.andCommandKey(HystrixCommandKey.Factory.asKey("userServiceCommand")));
this.UserService = UserService;
this.ids = ids;
}
@Override
protected List<User> run() throws Exception {
return UserService.findAll(ids);
}
}批量请求命令实际上就是一个简单的HystrixCommand实现,从上面的实现中可以看到它通过调用userService.finAll方法来访问/collapse/users?ids={ids}接口以返回User的列表结果。
第二步,通过继承HystrixCollapser实现请求合并器:
public class UserCollapseCommand extends HystrixCollapser<List<User>, User, Integer> {
private UserService userService;
private Integer id;
public UserCollapseCommand(com.wya.springboot.collapse.UserService userService, Integer id) {
super(Setter.withCollapserKey(HystrixCollapserKey.Factory.asKey("userCollapseCommand"))
.andCollapserPropertiesDefaults(HystrixCollapserProperties.Setter().withTimerDelayInMilliseconds(100)));
this.userService = userService;
this.id = id;
}
@Override
public Integer getRequestArgument() {
// TODO Auto-generated method stub
return id;
}
/**
* @param requests
* 保存了延迟时间窗中收集到的所有获取单个User的请求。通过获取这些请求的参数来组织
* 我们准备的批量请求命令UserBatchCommand实例
* @return
*/
@Override
protected HystrixCommand<List<User>> createCommand(
Collection<com.netflix.hystrix.HystrixCollapser.CollapsedRequest<User, Integer>> requests) {
List<Integer> ids = new ArrayList<Integer>(requests.size());
ids.addAll(requests.stream().map(CollapsedRequest::getArgument).collect(Collectors.toList()));
return new UserBatchCommand(userService, ids);
}
/**
* 在批量请求命令UserBatchCommand实例被触发执行完成后,该方法开始执行,
* 在这里我们通过批量结果batchResponse对象,为collapsedRequests中每个合并前的单个请求设置返回结果。
* 来完成批量结果到单个请求结果的转换
*
* @param batchResponse
* 保存了createCommand中组织的批量请求命令的返回结果
* @param collapsedRequests
* 代表了每个合并的请求
*/
@Override
protected void mapResponseToRequests(List<User> batchResponse,
Collection<com.netflix.hystrix.HystrixCollapser.CollapsedRequest<User, Integer>> requests) {
// TODO Auto-generated method stub
System.out.println("mapResponseToRequests========>");
int count = 0;
for (CollapsedRequest<User, Integer> collapsedRequest : requests) {
User user = batchResponse.get(count++);
collapsedRequest.setResponse(user);
}
}
}
}
在上面的构造函数中,我们为请求合并器设置了时间延迟属性,合并器会在该时间窗内收集获取单个User请求并在时间窗结束时进行合并组装成单个批量请求。getRequestArgument方法返回给定的单个请求参数id。
- createCommand:该方法的requests参数中保存了延迟时间窗中收集到的所有获取单个User的请求,通过获取这些请求的参数来组织我们准备的批量请求命令UserBatchCommand实例。
- mapResponseToRequests:在批量请求命令UserBatchCommand实例被触发执行完成之后,该方法开始执行,其中batchResponse参数保存了createCommand中组织请求命令的返回结果,而requests参数代表了每个请求合并的请求。在这里我们通过遍历批量结果batchResponse对象,为requests中每一个合并前的单个请求设置返回结果,以此完成批量结果到单个请求结果的转换。
创建测试方法
@RestController
public class HystrixController {
@Autowired
private UserService userService;
/**
* 测试请求合并
*
* @return
* @throws Exception
*/
@GetMapping("findById")
public List<User> findById() throws Exception {
List<User> users = new ArrayList<>();
Future<User> f1 = new UserCollapseCommand(userService, 1).queue();
Future<User> f2 = new UserCollapseCommand(userService, 2).queue();
Future<User> f3 = new UserCollapseCommand(userService, 3).queue();
Thread.sleep(3000);
Future<User> f4 = new UserCollapseCommand(userService, 4).queue();
Future<User> f5 = new UserCollapseCommand(userService, 5).queue();
User u1 = f1.get();
User u2 = f2.get();
User u3 = f3.get();
User u4 = f4.get();
User u5 = f5.get();
users.add(u1);
users.add(u2);
users.add(u3);
users.add(u4);
users.add(u5);
return users;
}
@GetMapping("test")
public User test() {
return userService.findById(1);
}
@GetMapping("findAll")
public List<User> findAll() {
List<Integer> ids = new ArrayList<>();
ids.add(1);
ids.add(2);
ids.add(3);
List<User> users = userService.findAll(ids);
return users;
}
}
接下来有个坑了,请求findById方法,报错了,
Caused by: rx.exceptions.OnErrorNotImplementedException: java.util.LinkedHashMap cannot be cast to com.wya.springboot.entity.User
我调试了半天没发现为啥mapResponseToRequests方法的List<User> batchResponse参数类型变成了LinkedHashMap,后来通过找资料发现我的UserService的findAll方法是这样写的
public List<User> findAll(List<Integer> ids) {
return restTemplate.getForObject("http://HELLO-SERVICE/collapse/users?ids={1}", List.class,
StringUtils.join(ids, ","));
}
这样的话http请求会把返回类型包装成LinkedHashMap,需要将这个方法改一改
public List<User> findAll(List<Integer> ids) {
ParameterizedTypeReference<List<User>> res = new ParameterizedTypeReference<List<User>>() {
};
ResponseEntity<List<User>> resp = restTemplate.exchange("http://HELLO-SERVICE/collapse/users?ids={1}",
HttpMethod.GET, null, res, StringUtils.join(ids, ","));
return resp.getBody();
/*return restTemplate.getForObject("http://HELLO-SERVICE/collapse/users?ids={1}", List.class,
StringUtils.join(ids, ","));*/
}这样再次运行就不会报错了,而且测试方法的前三个请求是一个线程,睡眠3s后最后两个请求是一个线程。
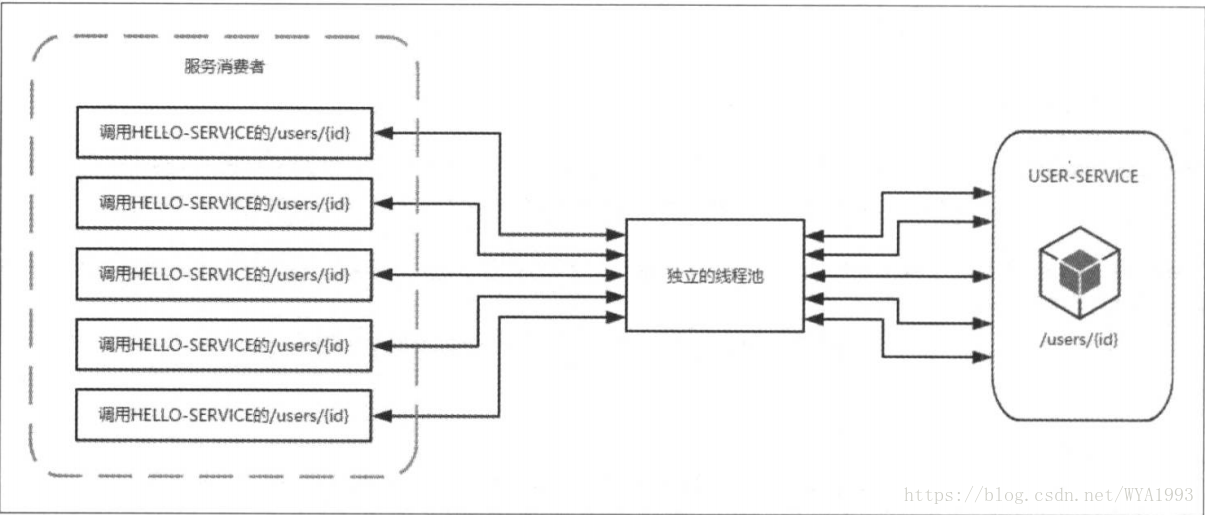
下图展示了未使用HystrixCollapser请求合并器之前的使用情况。可以看到当服务消费者同时对HELLO-SERVICE的/user/{id}接口发起五个请求时,会向该依赖服务的独立线程池申请五个线程了完成各自的请求操作。
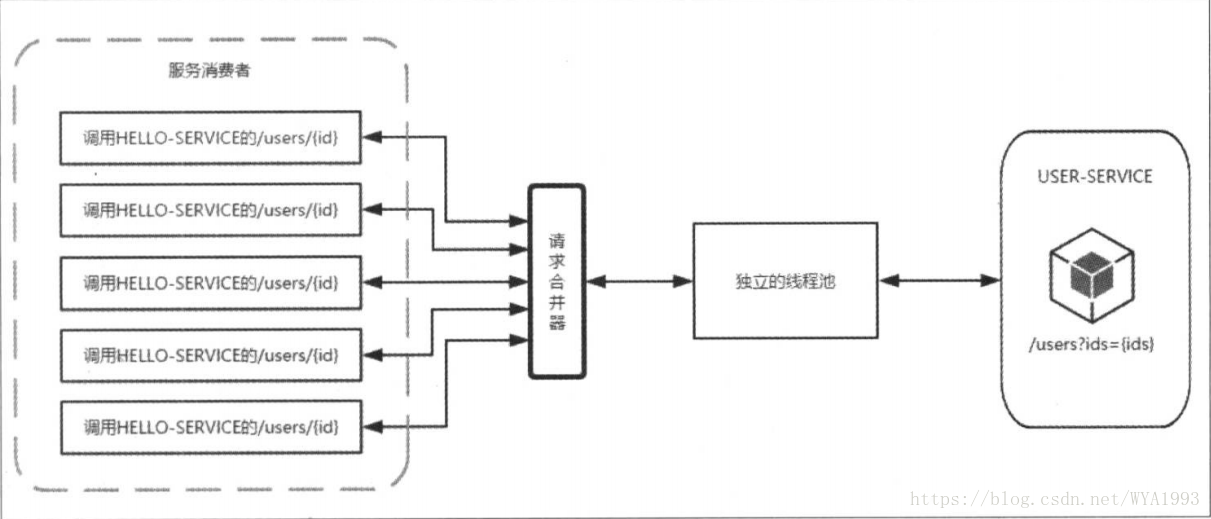
当使用了HystrixCollapser请求合并器后,会将这五个请求拦截并在合并器组合成一个批量请求,只用一个线程就可以了,所以在资源有效且短时间内会产生高并发请求的时候,为避免连接不够用而引起的延迟可以考虑使用请求合并器的方式来处理。
使用注解实现请求合并
先看一下@HystrixCollapser的源码,发现@HystrixCollapser是必须配合@HystrixCommand使用的
package com.netflix.hystrix.contrib.javanica.annotation;
import com.netflix.hystrix.HystrixCollapser.Scope;
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/**
* 此注解用来将一些命令合并成单个后端依赖关系调用
* 此注解需要与{@link HystrixCommand}注解一起使用
* <p/>
* 示例:
* <pre>
* @HystrixCollapser(batchMethod = "getUserByIds"){
* public Future<User> getUserById(String id) {
* return null;
* }
* @HystrixCommand
* public List<User> getUserByIds(List<String> ids) {
* List<User> users = new ArrayList<User>();
* for (String id : ids) {
* users.add(new User(id, "name: " + id));
* }
* return users;
* }
*</pre>
*
* 使用{@link HystrixCollapser}注解的方法可以返回任何兼容的类型,返回结果并不影响合并请求的执行,甚至可以返回{@code null}或者其他子类
* 需要注意的是:注解的方法如果返回Future类型,那么泛型必须和命令方法返回的List泛型一致
* 例如:
* <pre>
* Future<User> - {@link HystrixCollapser}注解方法返回值
* List<User> - 批量命令方法返回值
* </pre>
* <p/>
* 注意:批量命令方法必须用{@link HystrixCommand}注解标记
*/
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface HystrixCollapser {
/**
* 指定一个key,默认值是注解方法名
*/
String collapserKey() default "";
/**
* 批量命令方法的名称,指定的方法必须有如下的签名
* java.util.List method(java.util.List)
* 注意:指定的方法只能有一个参数
*/
String batchMethod();
/**
* 指定合并请求的范围默认是{@link Scope#REQUEST}
*/
Scope scope() default Scope.REQUEST;
/**
* 指定合并请求的配置,具体参见{@link HystrixCollapserProperties}
*/
HystrixProperty[] collapserProperties() default {};
}@HystrixCollapser(batchMethod="findByBatch",collapserProperties={
@HystrixProperty(name="timerDelayInMilliseconds",value="100")
})
public Future<User> find(Integer id) {
return null;
}
@HystrixCommand
public List<User> findByBatch(List<Integer> ids) {
ParameterizedTypeReference<List<User>> res = new ParameterizedTypeReference<List<User>>() {
};
ResponseEntity<List<User>> resp = restTemplate.exchange("http://HELLO-SERVICE/collapse/users?ids={1}",
HttpMethod.GET, null, res, StringUtils.join(ids, ","));
return resp.getBody();
}其中find方法通过@HystrixCollapser注解为其创建了请求合并器,通过batchMethod属性指定了批量请求的实现方法findByBatch,同时通过collapserProperties属性为合并请求器设置了相关属性,这里是将合并时间窗设置为100ms,即将100ms以内的相同请求合并。注意一点,find方法和findByBatch方法的参数类型应该一致,find方法的参数类型是Integer包装类,findByBatch方法就必须是List<Integer> ,第一次写的时候把find方法的参数写成了int 结果报错了。
测试方法:
/**
* 测试请求合并
*
* @return
* @throws Exception
*/
@GetMapping("find")
public List<User> find() throws Exception {
List<User> users = new ArrayList<>();
Future<User> u1 = userService.find(1);
Future<User> u2 = userService.find(2);
Future<User> u3 = userService.find(3);
Thread.sleep(3000);
Future<User> u4 = userService.find(4);
Future<User> u5 = userService.find(5);
users.add(u1.get());
users.add(u2.get());
users.add(u3.get());
users.add(u4.get());
users.add(u5.get());
return users;
}注意:请求合并必须异步调用,即通过Future获取User对象,否则不会合并请求。原因是如果你使用同步,是一个请求完成后另一个请求才能继续执行,所以必须异步才能请求合并。
下面贴一下服务提供者代码:
@RestController
@RequestMapping("collapse")
public class CollapseController {
@GetMapping("users/{id}")
public User getUserById(@PathVariable("id")Integer id) {
System.out.println("getUserById");
return new User(id, "cc", 22);
}
@GetMapping("users")
public List<User> getUserByIds(@RequestParam("ids")String ids) {
System.out.println("getUserByIds");
List<User> users = new ArrayList<>();
if(ids != null){
String[] idsAr = ids.split(",");
for(String id : idsAr){
users.add(new User(Integer.parseInt(id),"xxxx",23));
}
}
return users;
}
}
请求合并的额外开销
虽然通过请求合并可以减少请求的数量以缓解依赖服务线程池的资源,但是在使用的时候也需要注意它所带来的额外开销:用于请求合并的延迟时间窗会使用依赖服务的请求延迟增高。比如某个请求不通过请求合并器访问的平均时耗为5ms,请求合并的延迟时间窗为10ms(默认值),那么当该请求设置了请求合并器后,最坏情况下(在延迟时间窗结束时发起请求)该请求需要15ms才能完成。所以是否使用请求合并器需要根据依赖服务调用的实际情况来选择,主要考虑下面两个方面。
- 请求命令本身的延迟:如果依赖服务的请求命令本身是一个高延迟的命令,那么可以使用请求合并器,因为延迟时间窗的时间消耗显得微不足道了。
- 延迟时间窗内的并发量:如果一个时间窗内只有1~2个请求,那么这样的依赖服务不适合使用请求合并器。这种情况不但不能提升系统性能,反而会成为系统瓶颈,因为每个请求都需要多消耗一个时间窗才响应。相反,如果一个时间窗内具有很高的并发量,并且服务提供方也实现了批量处理接口,那么使用请求合并器可以有效减少网络连接数量并极大提升系统吞吐量,此时时间窗所增加的消耗可以忽略不计了。