文章目录
目录
1.spark介绍
1.1 spark介绍


spark不仅仅是一个计算框架,而是一个大数据处理的平台,或者说生态。
1.2 scale介绍

1.3 spark和Hadoop比较



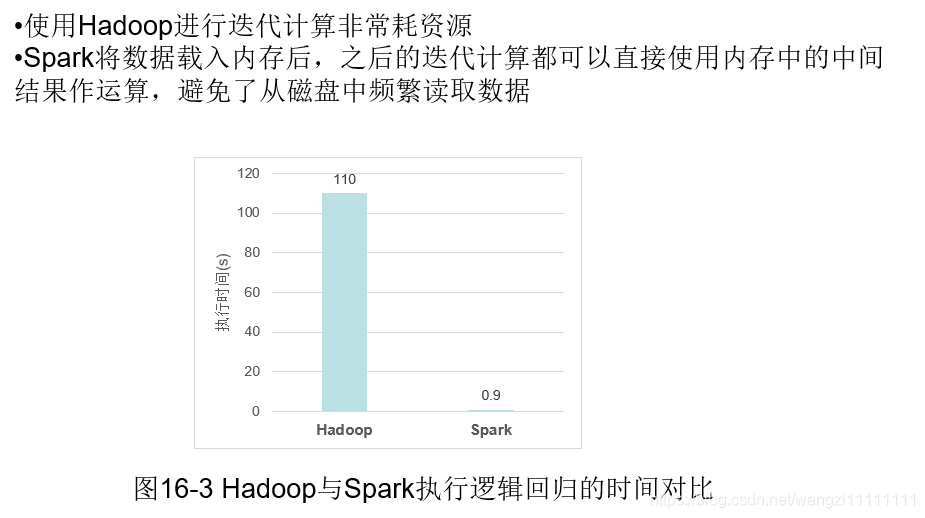
spark将运行的中间结果写入内存,而不是如MapReduce那样每次都写入磁盘,所以速度非常快,那么肯定就有疑问,内存相比于磁盘来说,那么小,如何解决大数据的中间结果的存储,spark是采用优先写内存,内存写满后,才往磁盘中写入。
2.spark生态系统


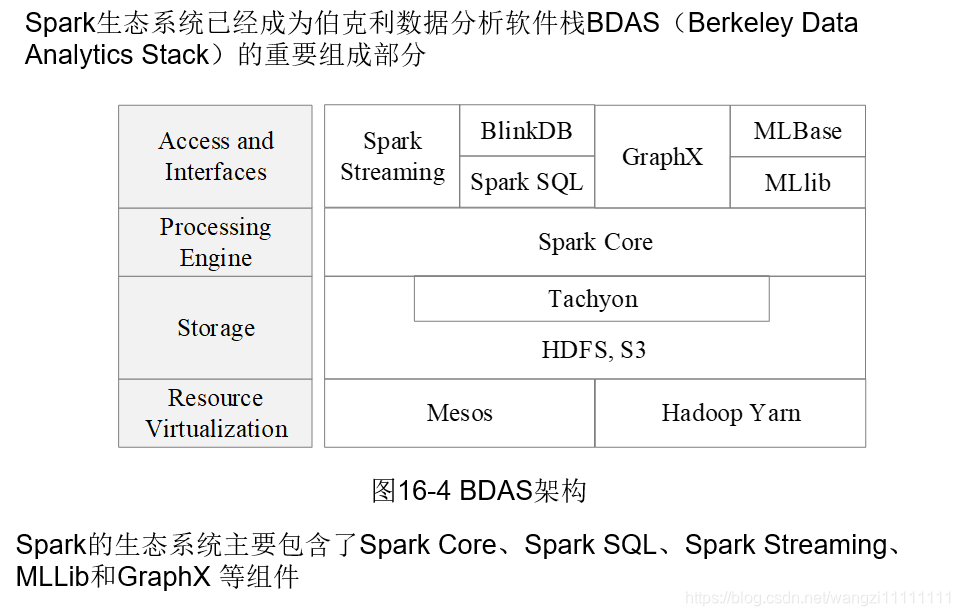
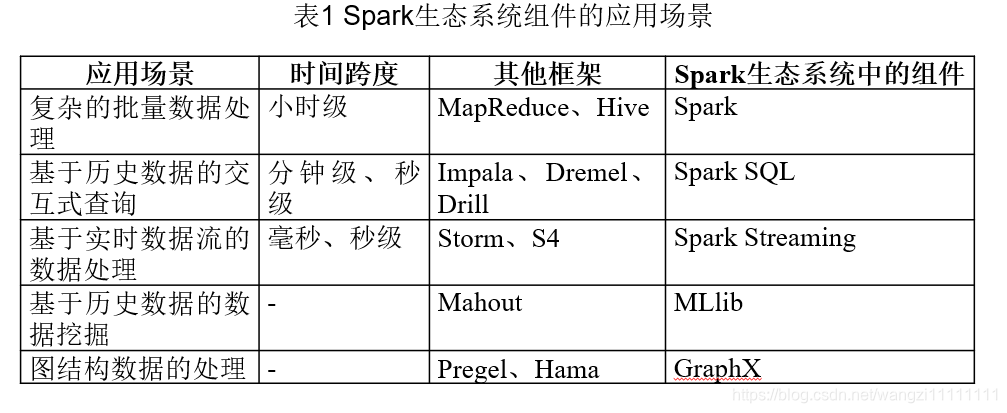
3.spark运行框架
3.1 基本概念

3.2 架构的设计
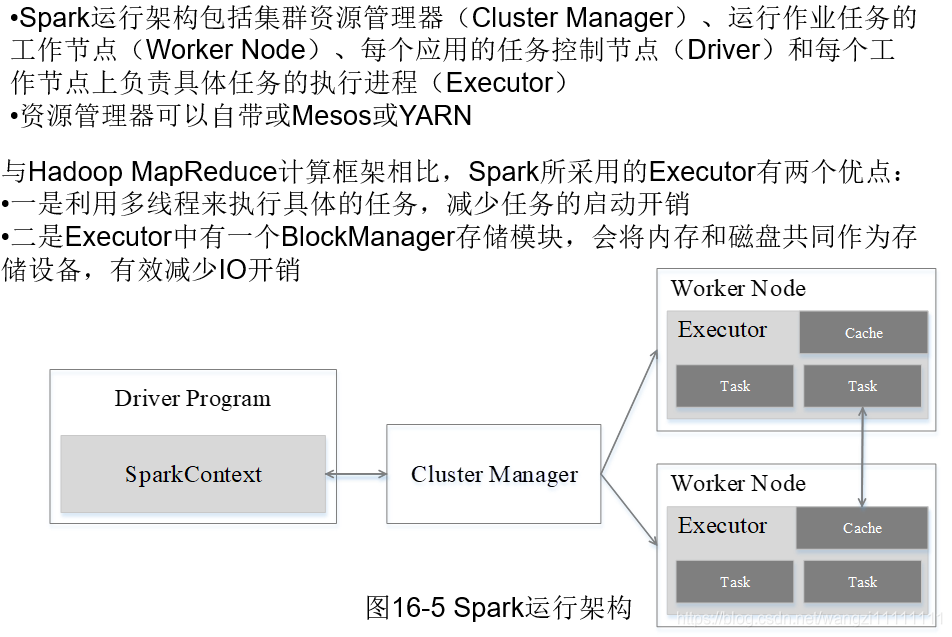

3.3 spark运行基本流程
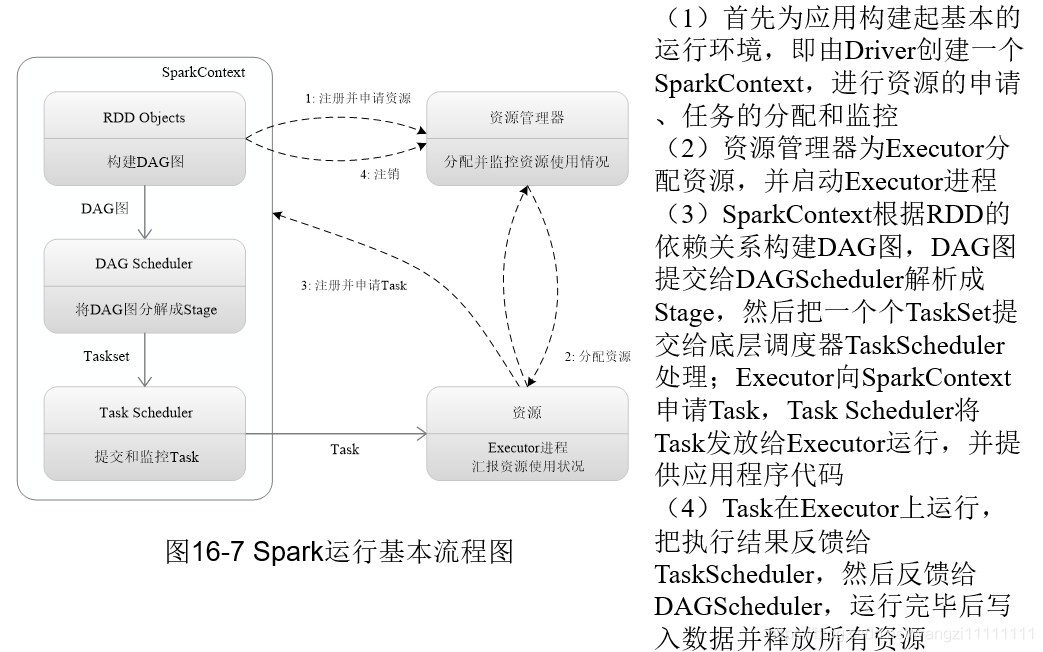
3.4 spark运行原理

3.5 RDD运行原理
3.5.1 设计背景

3.5.2 RDD概念和特性


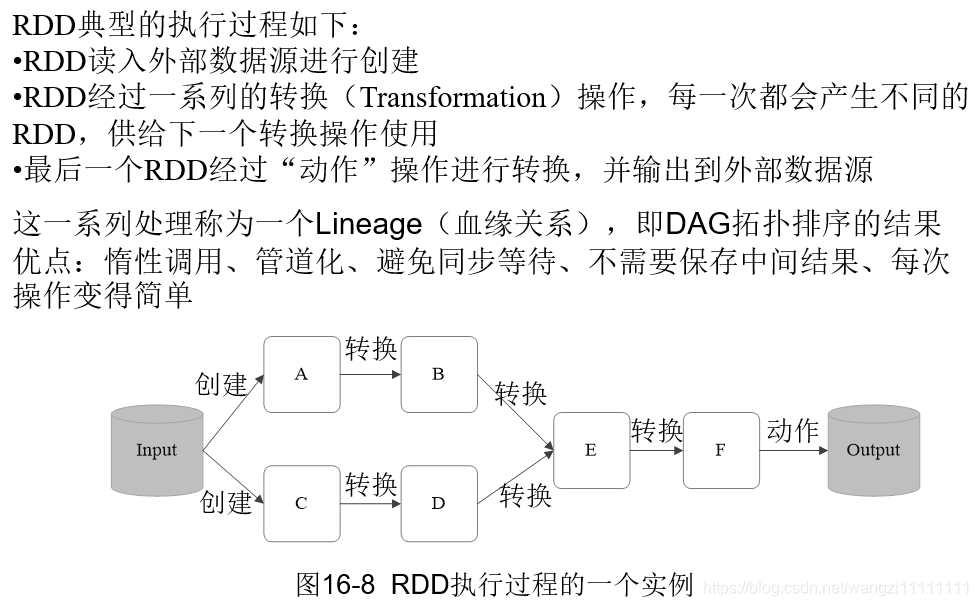

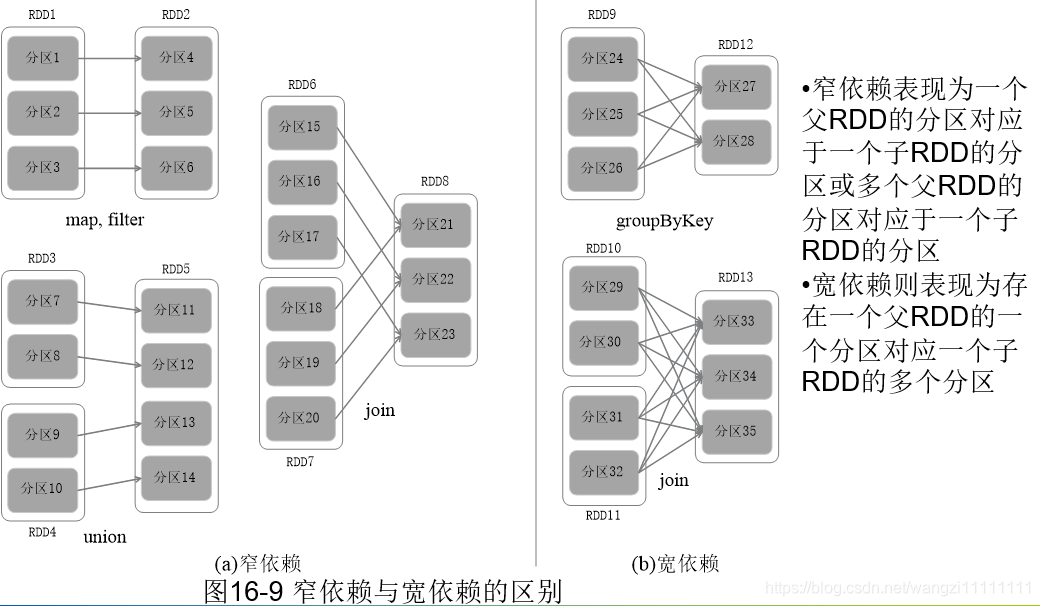
3.5.3 RDD之间的依赖关系
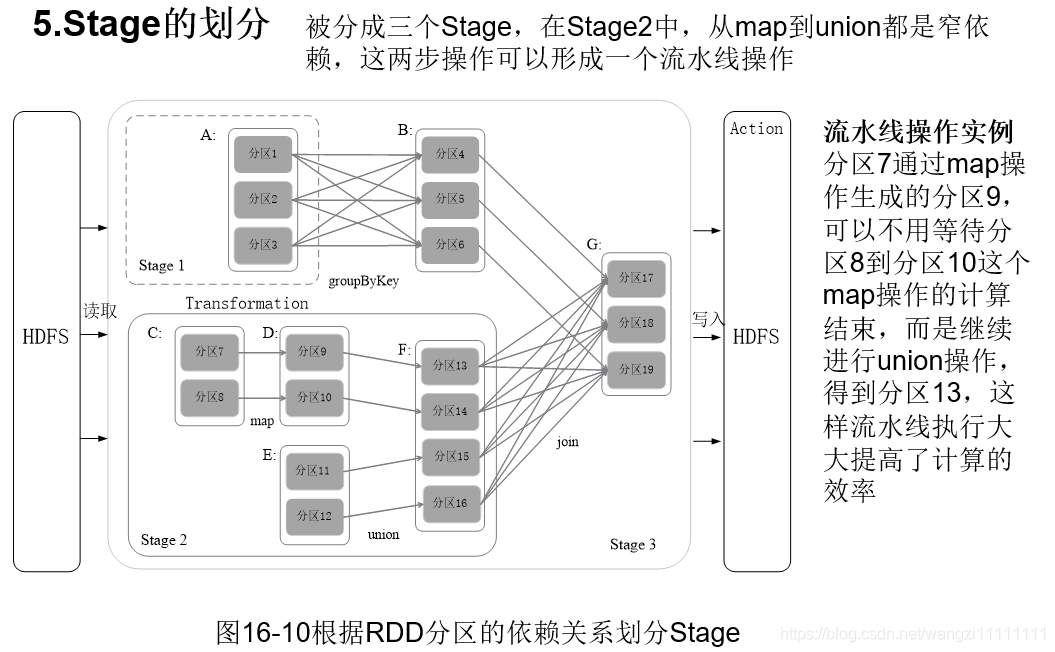
3.5.4 stage的划分


3.5.5 RDD的运行过程

4.spark SQL
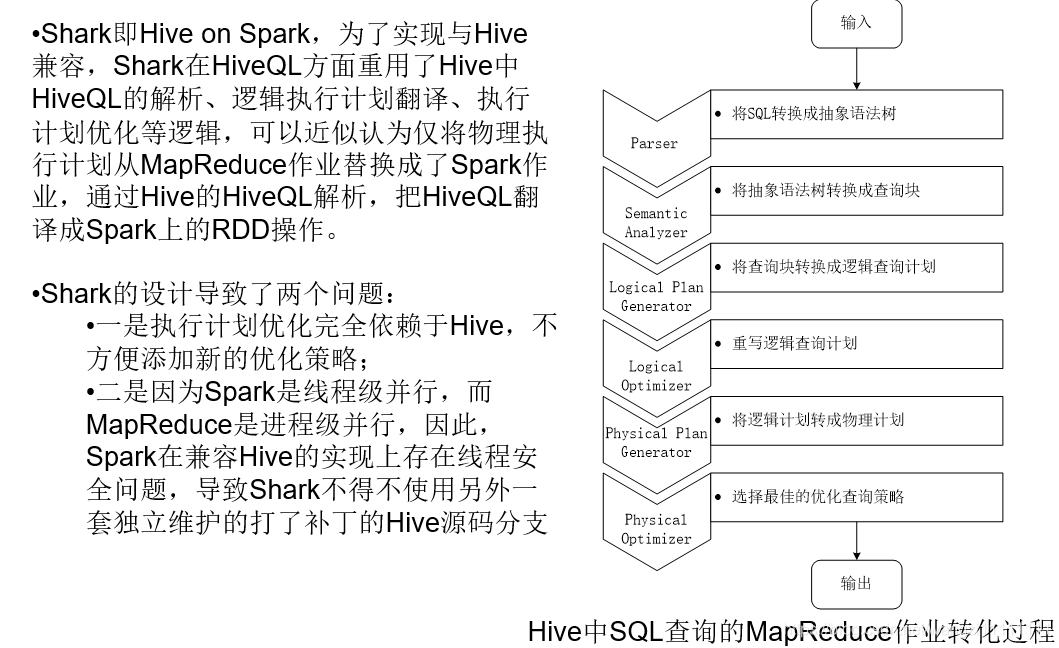
4.1 shark的介绍
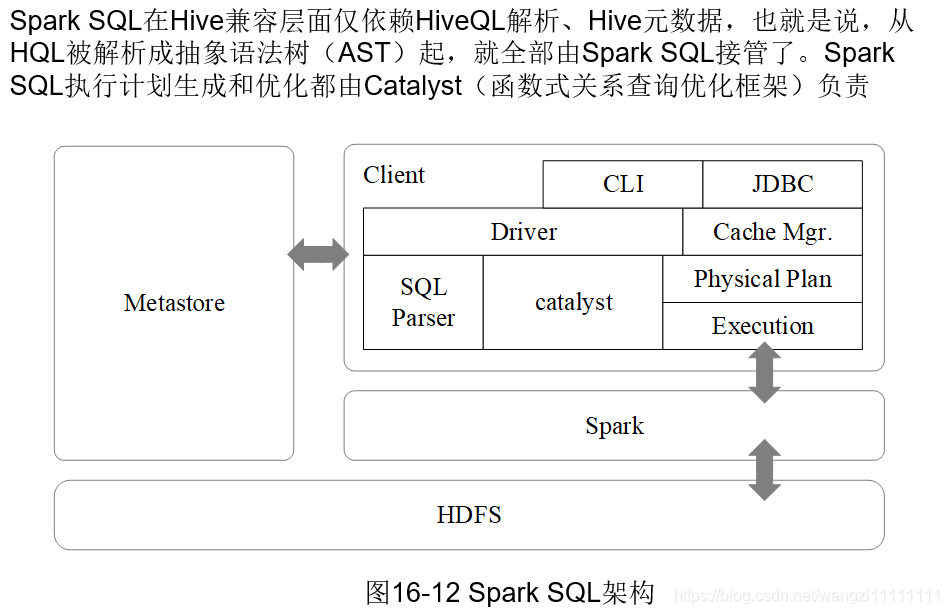
4.2 spark SQL的介绍

5.spark的部署和运行
5.1 三种部署方式

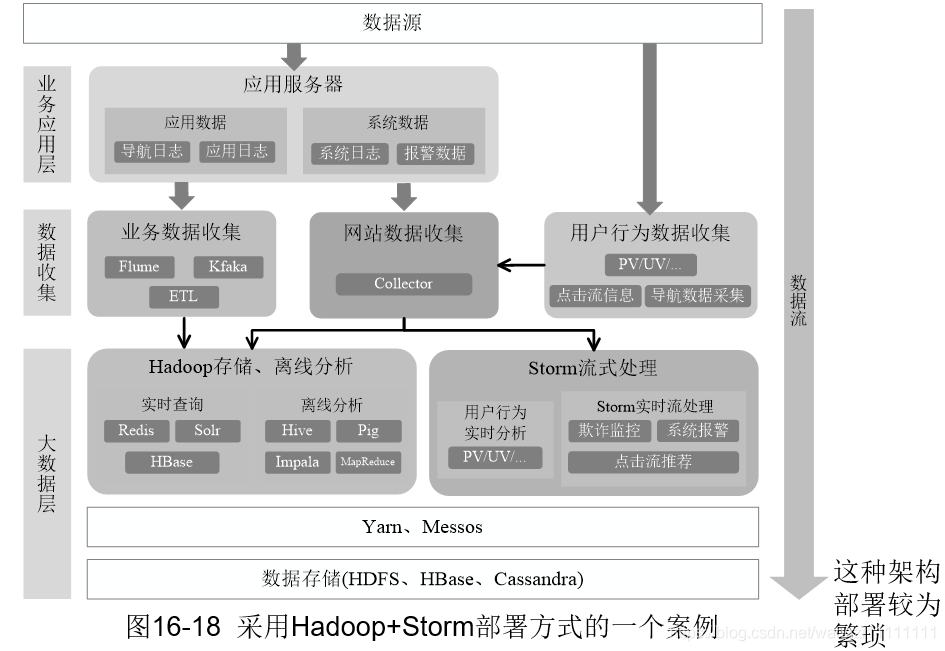
5.2 从Hadoop+Strom 架构转向spark架构

5.3 Hadoop 和spark的统一部署

6.spark编程实践
6.1 spark安装


6.2 启动spark shell

6.3 spark RDD的操作




6.4 spark应用程序



