Hadoop
基础
一个 Hadoop job 通常都是这样的:
- 从 HDFS 读取输入数据;
- 在 Map 阶段使用用户定义的 mapper function, 然后把结果写入磁盘;
- 在 Reduce 阶段,从各个处于 Map 阶段的机器中读取 Map 计算的中间结果,使用用户定义的 reduce function, 通常最后把结果写回 HDFS;
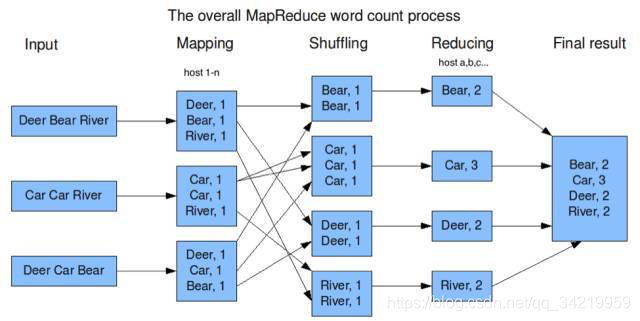
很多计算,就比如我们刚才的例子,都可以拆分成Map, Shuffle, Reduce三个阶段: - Map阶段中,每台机器先处理本机上的数据,像图1中各个机器计算本机的文件中关键字的个数。
- 各个机器处理完自己的数据后,我们再把他们的结果汇总,这就是Shuffle阶段,像刚才的例子,机器A, B, C, D…从1-n所有机器上取出Map的结果,并按关键字组合。
- 最后,进行最后一步处理,这就是Reduce,我们刚才的例子中就是对每一个搜索关键字统计出现总次数。
运行整个Hadoop Job的流程中,很多工作对于所有算法都是需要的,不同的算法只是Mapper Function和Reducer Function. 换句话说,Hadoop实现了通用的功能,开发人员只需要告诉Hadoop需要执行的Mapper, Reducer Function,就可以完成想要的计算,而不需要开发所有步骤
内核
- JobTracker
Hadoop 提供了一个叫做 JobTracker 的 component, 去等待用户提交的Hadoop 任务,用户告诉 JobTracker 要运行什么 mapper function 和 reducer function - Mapper 和 Reducer
我们用 Java 举例:用户需要用一个 class 实现 Hadoop 定义的 Mapper 接口,用户在这个 class 里提供 mapper function 的具体实现(当然 Hadoop 也支持别的语言),同样的 reducer function 也是用户实现 Reducer 接口的 class。
既然是 java, 这两个 class 就会存在 jar 中,所以用户要告诉 JobTracker 这个 jar 的路径是什么,也要告诉这个 jar 里,哪个 class 是 mapper, 哪个是 reducer. 只有这样,JobTracker 才能帮助用户把 mapper function 和 reducer function 部署到要运行的机器上。
除此之外,用户还要告诉 JobTracker 要处理的数据在哪里。实际上,数据存储使用的是 HDFS 文件系统。特别的是,HDFS 为了扩大容量,把文件存在很多台机器上,但用户不需要知道分布的具体细节:只要告诉 HDFS 我要哪个目录下的文件,HDFS 就会很神奇的找到相应的机器为用户读取数据(这就是分布式文件系统的特点)
同样的,用户也要告诉 JobTracker 这个 Hadoop 任务的输出在哪里,通常也是一个HDFS上的目录。
JobTracker 是以一个进程的形式运行的,一直等待用户提交的任务。一个 Hadoop cluster 里只有一个 JobTracker - JobTracker 接收了用户提交的任务后做什么
它要挑选机器来执行 mapper / reducer function
Hadoop为每一台机器定义 N 个 slot, 就是能同时运行 N 个 mapper function 或者 reducer function, 用几个 slot 被占用评断机器忙不忙.一个机器有几个 slot 是机器管理员根据机器 cpu 和内存情况设定的,在用户提交任务以前就定义好了。Jobtracker 通过追踪每一台机器上还有几个 slot可以用来判断机器的繁忙程度。 - TaskTracker and Slots
TaskTracker 是运行在每一台机器上的一个 daemon. 它的首要任务就是 keep track of 本台机器有哪些 slot
TaskTracker 有一个 heartbeat 机制,就是每隔几秒钟或者几分钟向 JobTracker 发一个信息,告之当前机器还有几个 free slot. 这样,JobTracker 就知道所有 Hadoop 机器资源使用情况。那么下次 JobTracker 收到用户提交的任务时,就有足够的信息决定向哪个机器分配 mapper 或 reducer 任务。
那么当 JobTracker 决定了给机器 a, c, e, f (out of 机器 a-h) 分配任务之后,JobTracker 就向每一台机器发消息,告诉它你要执行的 mapper 或者 reducer function 是什么.如果分配的是 mapper function, JobTracker 还要告诉 TaskTracker mapper 要处理的数据路径。我们之前提到了 JobTracker 会尽可能把 mapper 分配到数据所在的机器,这样 mapper 可以从本地文件读取数据了。当 TaskTracker 得知所有这些信息之后,就可以运行 mapper/reducer.
mapper function 和 reducer function 运行结束以后,TaskTracker 会报告给 JobTracker 运行结果。当所有 mapper 和 reducer 运行结束后,整个 Job 就完成了.
局限
一个 Hadoop job 进行了多次磁盘读写,比如写入机器本地磁盘,或是写入分布式文件系统中(这个过程包含磁盘的读写以及网络传输)。考虑到磁盘读取比内存读取慢了几个数量级,所以像 Hadoop 这样高度依赖磁盘读写的架构就一定会有性能瓶颈。
随着业界对大数据使用越来越深入,大家都呼唤一个更强大的处理框架,能够真正解决更多复杂的大数据问题
HDFS
架构
- HDFS Client
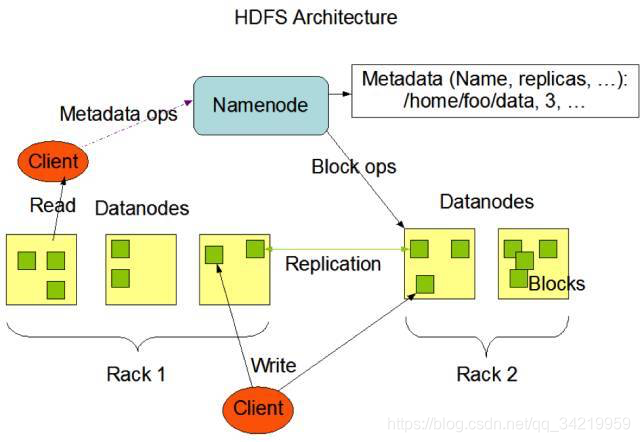
向 Hadoop cluster 提交任务是通过 Hadoop client 进行的。同样,我们和 HDFS 打交道也是通过一个 client library. 无论读取一个文件或者写一个文件,我们都是把数据交给 HDFS client,它负责和 Name nodes 以及 Data nodes 联系并传输数据。 - Name Nodes
在 HDFS 里, Name node 保存了整个文件系统信息,包括文件和文件夹的结构。其实和 linux 上的真的很像, HDFS 也是把文件和文件夹表示为 inode, 每个 inode 有自己的所有者,权限,创建和修改时间等等。HDFS 可以存很大的文件,所以每个文件都被分成一些 data block,存在不同机器上, name node 就负责记录一个文件有哪些 data block,以及这些 data block 分别存放在哪些机器上。
当我们通过 HDFS client 向 HDFS 读取或者写文件时,所有的读写请求都是先发给 Name nodes, 它负责创建或者查询一个文件,然后再让 HDFS client 和 Data nodes 联系具体的数据传输。 - Data Nodes
存储 data block 的机器叫做 Data nodes. 在读写过程中,Data nodes 负责直接把用户读取的文件 block 传给 client,也负责直接接收用户写的文件。
当我们读取一个文件时:
- HDFS client 联系 Name nodes,获取文件的 data blocks 组成、以及每个 data block 所在的机器以及具体存放位置;
- HDFS client 联系 Data nodes, 进行具体的读写操作
数据备份
数据备份,说白了就是多存几份。那究竟多存几份呢?这是一个可以配置的参数,从1到很大;如果我们不去配置,HDFS 默认3份。
- 备份的读写选择
问题来了:如果 HDFS 为每一个 block 存三份,那 client 如何来写呢?同时向三个 data node 写吗?
不是的。当 client 写文件创建新 block 的时后,Name nodes 会为这个 block 创建一个整个 HDFS cluster 里独有的 block ID,并且决定哪些 Data nodes l来存储这个 block 的所有备份。这些被选择的 Data nodes 组成一个队列,client 向队列的第一个 Data node 写,那么第一个 Data node 除了把数据存在自己的硬盘上以外,还要把数据传给队列里的下一个 data node,如此这般,直到最后一个 data node 接到数据完毕。
同样的,当 HDFS client 读取一个文件时,它首先从 Name nodes 获得这个文件所有 blocks 和每个 block 的所有备份所在机器位置。当 client 开始读取 block 时,client 会选择从“最近”的一台机器读取备份(“最近”指的是网络延迟最短),如果第一个备份出现问题,比如网络突然中断,或者硬盘出故障,那 client 就从第二个备份读,以此类推。
Spark
Spark 没有像 Hadoop 一样使用磁盘读写,而转用性能高得多的内存存储输入数据、处理中间结果、和存储最终结果。在大数据的场景中,很多计算都有循环往复的特点,像 Spark 这样允许在内存中缓存输入输出,上一个 job 的结果马上可以被下一个使用,性能自然要比 Hadoop MapReduce 好得多。
同样重要的是,Spark 提供了更多灵活可用的数据操作,比如 filter, union, join, 以及各种对 key value pair 的方便操作。
此外,Spark 本身作为平台也开发了 streaming 处理框架 spark streaming, SQL 处理框架 Dataframe, 机器学习库 MLlib, 和图处理库 GraphX。
- 思考:为何不把 Hadoop 的 MapReduce 转为基于内存的架构
MapReduce 定死了 Map 和 Reduce 两种运算以及之间 shuffle 的数据搬运工作。就是 Hadoop 运算无论多么灵活,你都要走 map -> shuffle -> reduce 这条路。要支持各类不同的运算,以及优化性能,还真不是改个存储介质这么简单。AMPLab 为此做了精心设计,让各种数据处理都能得心应手。
关键概念
Spark 的关键就是引入了 RDD (Resilient Distributed Datasets)的概念。其实没有太深奥,你可以把 RDD 想象成一组数据。
Spark 把要处理的数据,处理中间结果,和输出结果都定义成 RDD. 这样一个常见的 Spark job 就类似于:
-
从数据源读取数据,把输入生成一个 RDD;
-
通过运算把输入 RDD 转换成另一个RDD;
-
再通过运算把生成的 RDD 转换成另一个RDD,重复需要进行的 RDD 转换操作 (此处省略一千遍);
-
最后运算成结果 RDD,处理结果;
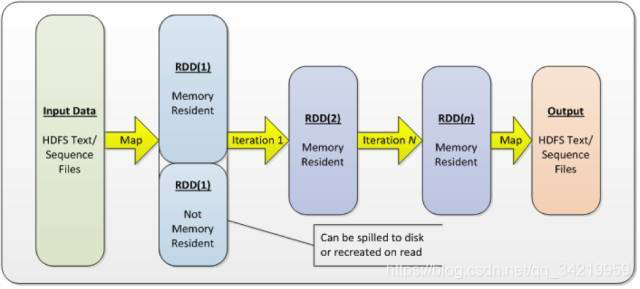
为了处理大量数据,还是把要处理的数据进行分区,分散到多台机器上,以便之后并行处理,这个和 Hadoop 的理念一致。不过,RDD 默认被存到内存中,只有当数据大于 Spark 被允许使用的内存大小时才被 spill 到磁盘
RDD的接口
考虑到 RDD 是连接 Spark 数据操作的核心,RDD 的接口自然是重中之重。简单说,这套接口告诉你:为了生成这个 RDD,它的上一个 RDD 是谁,以及生成过程使用的运算是什么。
你有一堆数据 A,被分成了 A1,A2 两个分区,你为每个分区使用了运算 F 把它们转换成另一堆数据 B1,B2,合起来就是B。那么当我们问,你如何得到 B2 时,你怎么回答?我们需要数据 A2,并且需要运算 F. 同样的,你如何得到 B1 ?我们需要数据 A1, 并且需要运算 F. 就是这么简单。
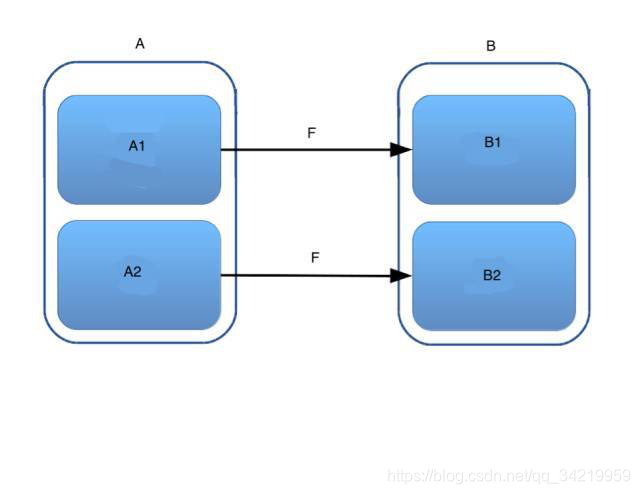
-
Map
其实我们上面的例子就是 map:一个 RDD 的分区分别转换成下一个 RDD 的分区,各个分区之间互不影响。那每个 RDD 分区的 “爸爸“ 就是上一个 RDD 对应的分区。运算就是用户定义的map function. -
Filter
还是用上面的例子:只不过这个 F 变成“这条数据是否该留下来”,在这种情况下这样 A1 >= B1. -
GroupbyKey
这个复杂一些,它里面的数据不是单个的,而是 key-value pair. 联系我们之前 Hadoop 的例子,RDD B 里的分区中的数据有可能是 A1,也有可能是A2 里的,那我们就清清楚楚地告诉 B,你的每个分区的 “爸爸” 都是 A 里面所有的分区。运算呢?就是合并所有 Key 一样的 key value pair,组成一个 set.
Spark RDD 支持的运算很多很多,但是本质都是用 RDD 的接口灵活的定义出不同运算。用户也可以根据自己需要创作新的运算。这样 Spark 允许用户用不同种类的运算实现了复杂的企业逻辑,甚至是 SQL 的处理和机器学习。这看似简单的设计恰恰是 Spark 强大的基础。
RDD的构建
每一个 Spark Job 就是定义了由输入 RDD,如何把它转化成下一个状态,再下一个状态 …… 直到转化成我们的输出。这些转化就是对 RDD 里每一个 data record 的操作。用个高大上点的语言,一个 Spark job 就是一系列的 RDD 以及他们之间的转换关系。那么用户如何才能定义 RDD 和转换关系呢?
用java举例:
用户需要定义一个包含主函数的 Java (main) 类。在这个 main 函数中,无论业务逻辑多么复杂,无论你需要使用多少 Java 类,如果从 Spark 的角度简化你的程序,那么其实就是:
-
首先生成 JavaSparkContext 类的对象.
-
从 JavaSparkContext 类的对象里产生第一个输入RDD. 以读取 HDFS 作为数据源为例,调用 JavaSparkContext.textFile() 就生成第一个 RDD.
-
每个 RDD 都定义了一些标准的常用的变化,比如我们上面提到的 map, filter, reduceByKey …… 这些变化在 Spark 里叫做 transformation.
-
之后可以按照业务逻辑,调用这些函数。这些函数返回的也是 RDD, 然后继续调用,产生新的RDD …… 循环往复,构建你的 RDD 关系图。
-
注意 RDD 还定义了其他一些函数,比如 collect, count, saveAsTextFile 等等,他们的返回值不是 RDD. 这些函数在 Spark 里叫做 actions, 他们通常作为 job 的结尾处理。
-
用户调用 actions 产生输出结果,Job 结束。
action介绍
Action 都是类似于 “数数这个 RDD 里有几个 data record”, 或者 ”把这个 RDD 存入一个文件” 等等。想想他们作为结尾其实非常合理:我们使用 Spark 总是来实现业务逻辑的吧?处理得出的结果自然需要写入文件,或者存入数据库,或者数数有多少元素,或者其他一些统计什么的。所以 Spark 要求只有用户使用了一个 action,一个 job 才算结束。当然,一个 job 可以有多个 action,比如我们的数据既要存入文件,我们又期望知道有多少个元素。
这些 RDD 组成的关系在 Spark 里叫做 DAG,就是有向无循环图,图论里的一个概念,大家有兴趣可以专门翻翻这个概念。可以发现,实践中绝大部分业务逻辑都可以用 DAG 表示,所以 spark 把 job 定义成 DAG 也就不足为奇了。
RDD的两种变化
我们上面刚刚介绍了 transformation 的概念。在 Spark 眼中,transformation 被分成 narrow transformation 和 wide transformation. 这是什么东西呢?
上文提到过 RDD 被分成几个分区,分散在多台机器上。当我们把一个 RDD A 转化成下一个 RDD B 时,这里有两种情况:
-
有时候只需要一个 A 里面的一个分区,就可以产生 B 里的一个分区了,比如 map 的例子:A 和 B 之间每个分区是一一对应的关系,这就是 narrow transofmration.
-
还有一类 transformation,可能需要 A 里面所有的分区,才能产生 B 里的一个分区,比如 reduceByKey的例子,这就是 wide transformation.
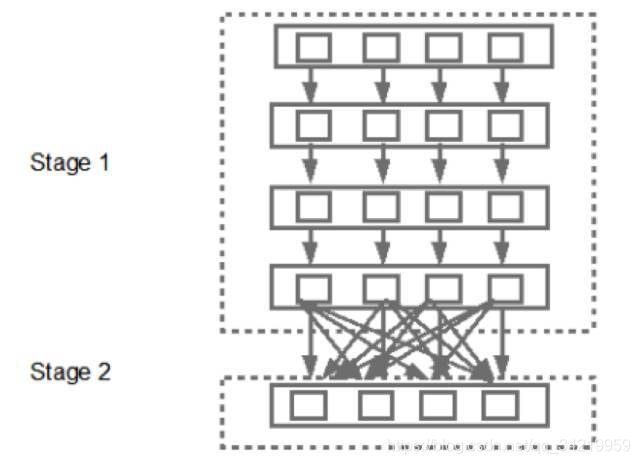
Narrow 或者 Wide 的关系
一个 Spark job 中可能需要连续地调用 transformation, 比如先 map,后 filter,然后再 map …… 那这些 RDD 的变化用图表示就是:
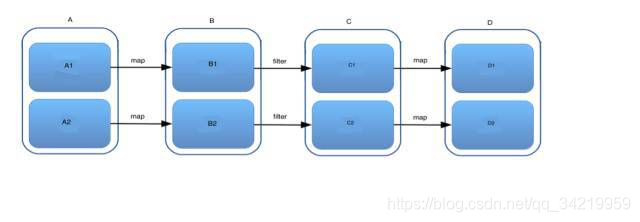
把多个操作合并到一起,在数据上一口气运行的方法在 Spark 里叫 pipeline (其实 pipeline 被广泛应用的很多领域,比如 CPU)。这时候不同就出现了:只有 narrow transformation 才可以进行 pipleline 操作。对于 wide transformation, RDD 转换需要很多分区运算,包括数据在机器间搬动,所以失去了 pipeline 的前提。
RDD 的执行
当用户调用 actions 函数时,Spark 会在后台创建出一个 DAG. 就是说 Spark 不仅用 DAG 建模,而且真正地创建出一个 DAG, 然后执行它。
Spark 会把这个 DAG 交给一个叫 DAG scheduler 的模块,DAG scheduler 会优先使用 pipeline 方法,把 RDD 的 transformation 压缩;当我们遇到 wide transformation 时,由于之前的 narrow transformation 无法和 wide transformation pipeline, 那 DAG scheduler 会把前面的 transformation 定义成一个 stage.
重要的事情说三遍:DAG scheduler 会分析 Spark Job 所有的 transformation, 用 wide transformation 作为边界,把所有 transformation 分成若干个stages. 一个 stage 里的一个分区就被 Spark 叫做一个task. 所以一个 task 是一个分区的数据和数据上面的操作,这些操作可能包括一个 transformation,也可能是多个,但一定是 narrow transformation.
DAG scheduler 工作的结果就是产生一组 stages. 这组 stages 被传到 Spark 的另一个组件 task scheduler, task scheduler 会使用集群管理器依次执行 task, 当所有的 task 执行完毕,一个 stage 标记完成;再运行下一个 stage …… 直到整个 Spark job 完成。