一,下载lib和dll
可以从这里 http://code.google.com/p/tesseract-ocr/downloads/list 下载
| tesseract-ocr-setup-3.02.02.exe | Windows installer of tesseract-ocr 3.02.02 (including English language data) Featured |
然后进行安装,如此可以方便地省去好多配置细节:如修改环境变量【如果不采用环境变量方式,则需要对于每个工程目录建立tessdata文件夹,并且里面放置所需要的chi_sim.traineddata等语言包】,也不再需要下载tesseract-3.02.02-win32-lib-include-dirs.zip, 更方便以后 训练出自己的 traineddata 文件
需要注意的是,安装目录下lib里面 libtesseract302d.dll 是针对VS2008的,需要用一个vs2010编译出的替换下来才可以在VS2010下正常使用。
另外还需要将 liblept168.dll 和 liblept168d.dll两个文件一并下载放到lib里面。 (我的资源库有这几个文件)
二,修改环境变量Path
在环境变量Path中增加指向 安装目录下lib的路径,比如C:\Program Files\Tesseract-OCR\lib ,以便exe运行时能找到所需要的dll
三,工程中属性中增加路径
在自己的工程属性中VC++目录下增加包含目录和库目录,以便VS2010查找文件。例如
包含目录 下新增:C:\Program Files\Tesseract-OCR\include\tesseract
库目录 下新增: C:\Program Files\Tesseract-OCR\lib
四,增加语言训练包
直接将语言训练包放置在 安装目录 tessdata文件夹 下就好,比如将tesseract-ocr-3.02.chi_sim.tar.gz中的chi_sim.traineddata 文件直接抽取出来放在 C:\Program Files\Tesseract-OCR\tessdata 下面,就可以支持中文简体字符的识别啦。当然,自己训练出来的 traineddata 文件也是要放在这里的才生效。
测试代码:
-
#include "stdafx.h"
-
#pragma comment(lib, "libtesseract302.lib")
-
#pragma comment(lib, "liblept.lib")
-
#include "tesseract\baseapi.h"
-
#include "tesseract\strngs.h"
-
-
-
int _tmain(
int argc, _TCHAR* argv[])
-
{
-
const
char * image =
"image.jpg";
-
-
tesseract::TessBaseAPI api;
-
api.Init(
NULL,
"eng", tesseract::OEM_DEFAULT);
-
api.SetVariable(
"tessedit_char_whitelist",
"0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" );
-
-
STRING text_out;
-
if (!api.ProcessPages(image,
NULL,
0, &text_out))
-
{
-
return
0;
-
}
-
-
printf(text_out.
string());
-
-
return
0;
-
}
测试图片
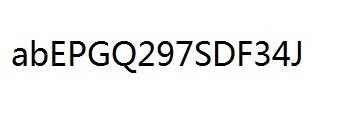
测试结果
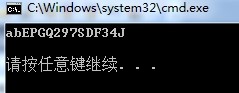
-
#pragma comment(lib, "libtesseract302.lib")
-
#pragma comment(lib, "liblept.lib")