Tesseract安装
Tesseract是常用的开源OCR识别引擎,后续的图片文字识别项目我们将会调用该库进行识别,本文针对Tesseract的安装配置进行相关说明。
一、Tesseract下载
下载地址:Tesseract
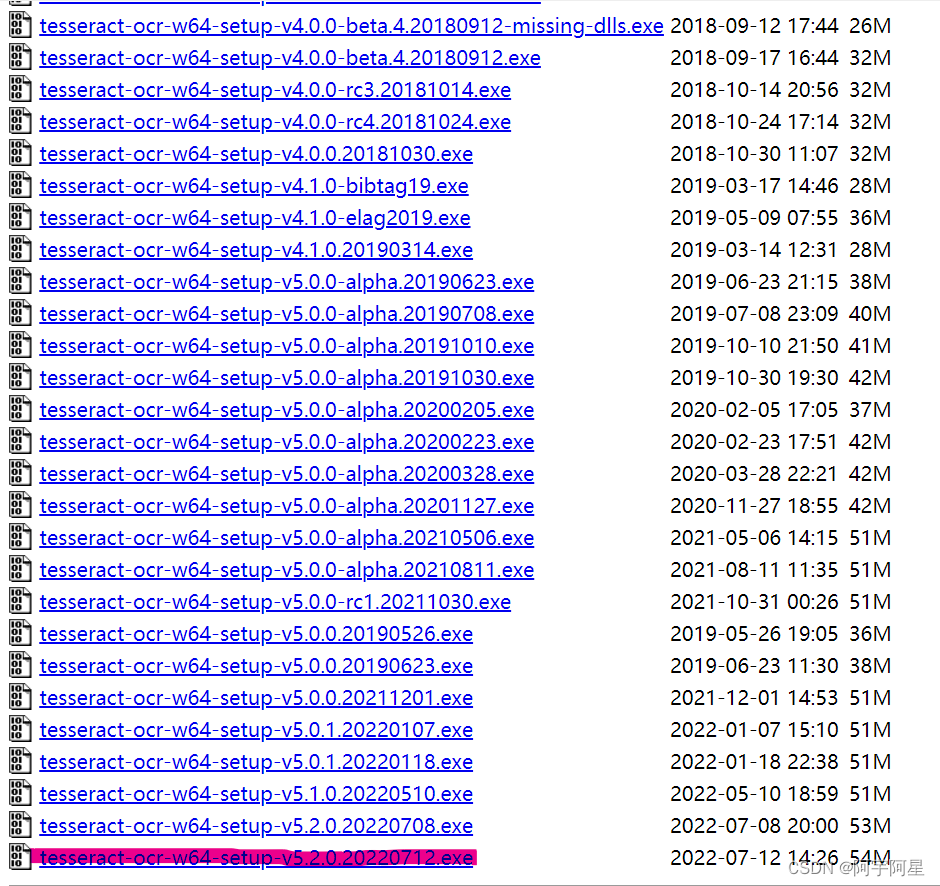
选择最新的版本进行下载,下载完成后,解压安装在自己设定的安装路径,一直选择next即可完成安装。
二、添加环境变量
打开系统属性页面,然后点击高级,最后选择环境变量。

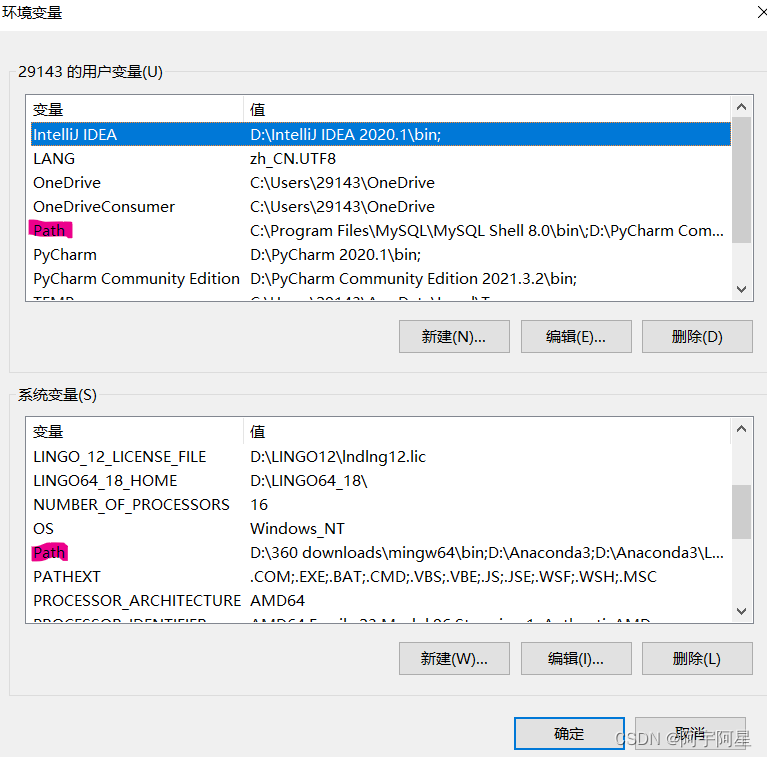
在环境变量页面,将Tesseract安装路径添加到用户变量和系统变量的Path,为验证添加环境变量是否成功,打开cmd窗口,输入命令:
tesseract -v
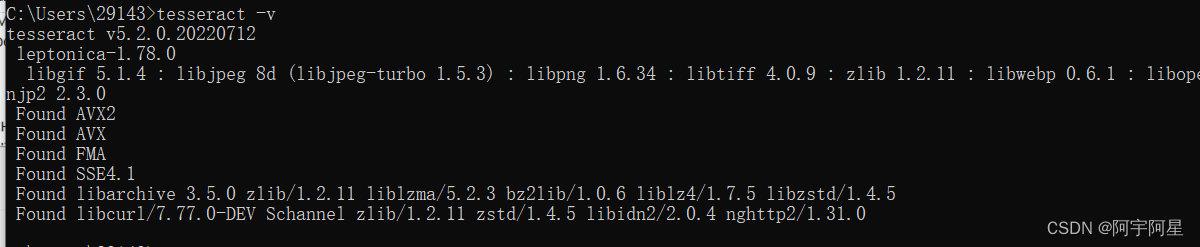
如果弹出tesseract的版本信息,则说明环境变量配置成功,否则说明配置失败,需要读者仔细研读上述步骤进行重新配置。
使用tesseract --list-langs来查看Tesseract-OCR支持语言。

三、配置Tesseract中文识别语言包
下载路径:chi_sim
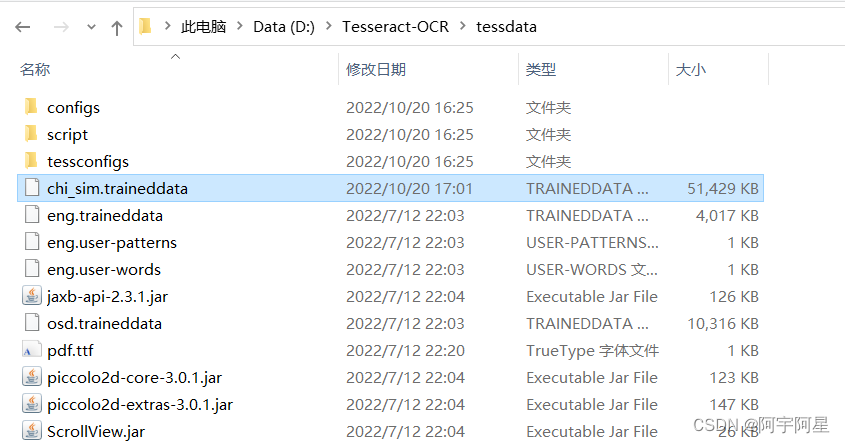
将下载的chi_sim.traineddata文件复制到安装路径下的tessdata文件夹,如图所示:
四、下载相关库
pip install pytesseract
pip install Pillow
五、示例程序
1.待识别图片

2.识别程序
import pytesseract
from PIL import Image
path="D:\\code\\python\\opencv\\图像处理\\test.png"
image=Image.open(path)
text=pytesseract.image_to_string(image,lang='chi_sim')
print(text)#打印输出识别文字
3.识别结果
