0 第零关
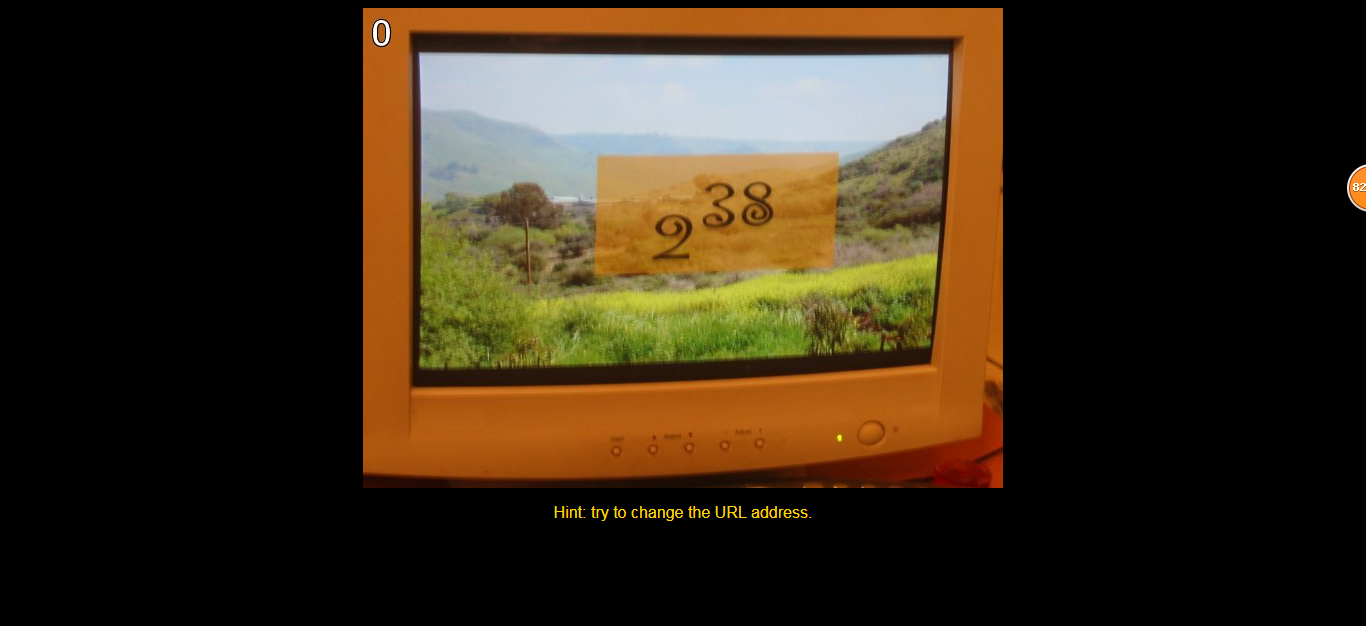
2**38 = 274877906944
下一关的url:http://www.pythonchallenge.com/pc/def/274877906944.html
1 第一关

移位计算,可以看出来是移动2位
def trans_str(s): inword = 'abcdefghijklmnopqrstuvwxyz' outword = 'cdefghijklmnopqrstuvwxyzab' transtab = str.maketrans(inword, outword) new_str = s.translate(transtab) return new_str if __name__ == '__main__': s = "g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q ufw " \ "rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj" print(trans_str(s)) s1 = 'map' print(trans_str(s1))
得到答案:
i hope you didnt translate it by hand. thats what computers are for. doing it in by hand is inefficient and that's why this text is so long. using string.maketrans() is recommended. now apply on the url ocr
第二关url:http://www.pythonchallenge.com/pc/def/ocr.html
2 第二关

识别字符,也许他可能在书中,也可能在页面源码中。
打开页面源代码,发现提示:
在下面混乱的字符中找到比较少的字符
new_list = [] for i in s: if i not in new_list: new_list.append(i) new_dict = {} for j in new_list: new_dict[j] = s.count(j) print(new_dict)
得到结果:
{'%': 6104, '$': 6046, '@': 6157, '_': 6112, '^': 6030, '#': 6115, ')': 6186, '&': 6043, '!': 6079, '+': 6066, ']': 6152, '*': 6034, '}': 6105, '[': 6108, '(': 6154, '{': 6046, '\n': 1219, 'e': 1, 'q': 1, 'u': 1, 'a': 1, 'l': 1, 'i': 1, 't': 1, 'y': 1}
发现出现一次的字符为:equality
则第三关的url为:http://www.pythonchallenge.com/pc/def/equality.html
3 第三关

待续。。。