版权声明:转载请注明! https://blog.csdn.net/linfeng886/article/details/82262383
第五关
第四关的密码与第三关一样,都是30以内的数字
步骤
- 我们先登陆网址,然后随便输入一个用户名和密码,看看post请求里带有哪些参数
- post请求带了五个参数,
csf,username,password,captcha_0和captcha_1,captcha_0是上一次验证码的uuid,captcha_1是你输入的验证码 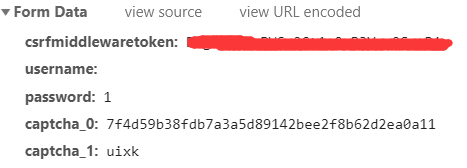
- 然后我们在第三关的基础上,增加获取验证码的操作
- 我们发现验证码的链接不是固定的
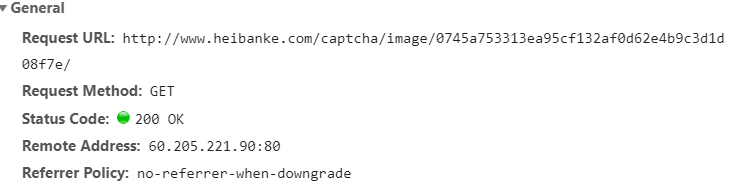
- 所以我们需要从当前页面把它的链接抓取出来,查看网页代码,发现链接藏在这里
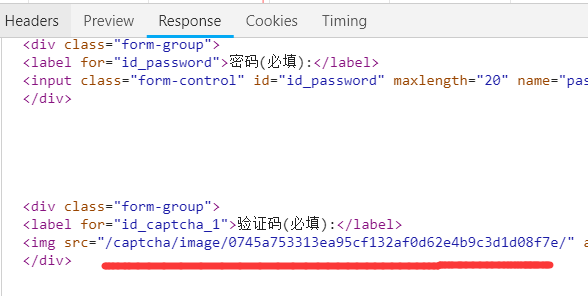
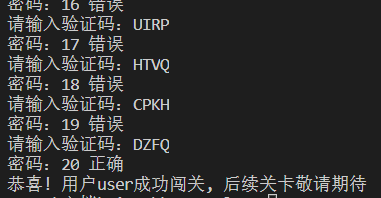
- 然后我们就可以获取验证码,然后保存到本地去手动输入啦
- 当然你也可以选择用打码平台或者机器学习的方法去自动识别
代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import requests
from lxml import etree
class Login(object):
def __init__(self):
self.session = requests.Session()
self.url_login = 'http://www.heibanke.com/accounts/login'
self.url_test = 'http://www.heibanke.com/lesson/crawler_ex04/'
self.headers = {
'Host': 'www.heibanke.com',
'User-Agent': 'Mozilla/5.0 (iPad; CPU OS 12_0 like Mac OS X) AppleWebKit/604.1.34 (KHTML, like Gecko) CriOS/68.0.3440.83 Mobile/16A5345f Safari/604.1'
}
self.data_login = {
'csrfmiddlewaretoken': '',
'username': '你的账号',
'password': '你的密码'
}
self.data_test = {
'csrfmiddlewaretoken': '',
'username': 'user',
'password': '',
'captcha_0': '',
'captcha_1': ''
}
# 获取Cookies
def get_cookies(self):
res = self.session.get(url=self.url_login, headers=self.headers)
self.data_login['csrfmiddlewaretoken'] = res.cookies['csrftoken']
# 进行账号登陆
def login(self):
req= self.session.post(url=self.url_login, data=self.data_login, headers=self.headers)
html = etree.HTML(req.text)
#用xpath取得登陆后的关键字
result = html.xpath('//body/div//h5/text()')
#如果登陆成功就会提示'欢迎xxx访问我们站点'
if result:
print(result[0])
self.data_test['csrfmiddlewaretoken'] = req.cookies['csrftoken']
else:
print('登陆失败')
# 取得验证码
def get_captchat(self):
res = self.session.get(url=self.url_test, headers=self.headers)
self.data_test['csrfmiddlewaretoken'] = res.cookies['csrftoken']
html = etree.HTML(res.text)
# 取得验证码图片的地址
uuid = html.xpath('//img/@src')[0].split('/')[3]
self.data_test['captcha_0'] = uuid
url_captcha = 'http://www.heibanke.com/captcha/image/' + uuid
# 保存到本地
res = self.session.get(url=url_captcha, headers=self.headers)
with open('1.png', 'wb') as pic:
pic.write(res.content)
self.data_test['captcha_1'] = input('请输入验证码:')
# 模拟登陆
def post_page(self):
self.get_captchat()
res = self.session.post(url=self.url_test, data=self.data_test, headers=self.headers)
html = etree.HTML(res.text)
content = html.xpath('//h3/text()')[0]
return content
def main(self):
self.get_cookies()
self.login()
for x in range(0,31):
self.data_test['password'] = str(x)
content = self.post_page()
if '成功闯关' in content:
print('密码:%s 正确' %x)
print(content)
break
else:
print('密码:%s 错误' %x)
if __name__ == "__main__":
login = Login()
login.main()结语:
源码: 点我
欢迎关注我的公众号
疯子的Python笔记
