目录
1. SNE原理
基本原理: 是通放射变换 将数据点映射到概率分布上,分为两个步骤:
- 构建高维对象之间的概率分布,使得相似的对象有更高的概率被选择,而不相似的对象有更低的概率。
- SNE 在低维空间中构建这两个分布,使得两个概率分布尽可能相似。
t-SNE是非监督的降维,跟kmeans 等不同,他不能通过训练得到一些东西后再用于其他数据(kmeans 可以通过训练得到k个点,再用于其他数据集,而t-SNE 只能单独多数据做操作。
原理推导: SNE 是先将欧几里得距离转化为条件概率来表达点与点之间的相似度,具体来说,给定N个高 维的数据,(N 不是维度)。首先是计算概率pij,正比于xi和xj 之间的相似度,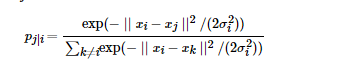
这里的参数![]() 对于不同的xi的取值不一样,后续讨论如何设置,此外设置px|x =0,因为我们关注的是两两之间的相似度,对于低维度下的yi,可以指定高斯分布方差为
对于不同的xi的取值不一样,后续讨论如何设置,此外设置px|x =0,因为我们关注的是两两之间的相似度,对于低维度下的yi,可以指定高斯分布方差为![]() ,因此相似度为
,因此相似度为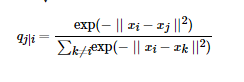
同样qi|i=0。
如果降维效果比较好,局部特征保留完整,那么![]() ,因此我们优化两个分布之间的KL散度。目标函数如下:
,因此我们优化两个分布之间的KL散度。目标函数如下:
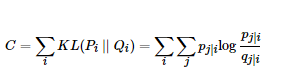 ,这里的·Pi表示了给定点xi下,其他所有数据点的条件概率分布。
,这里的·Pi表示了给定点xi下,其他所有数据点的条件概率分布。
KL 散度具有不对称性,在低维映射中不同距离对应的惩罚权重是不同的。具体来说是: 距离较远的两个点来表达距离较近的两个点会产生更大的cost,距离较近的两个点来表达距离较远的两个点产生的cost 相对较小。例如![]() 来建模 cost=
来建模 cost=
![]() ,用同样较大的
,用同样较大的![]() 来建模
来建模![]()
![]() ,因此,SNE 倾向与保留数据中的局部特征。
,因此,SNE 倾向与保留数据中的局部特征。
2 t-SNE
SNE 很难优化,存在Crowing 问题 (拥挤) 不同点: 使用对称的SNE,简化梯度公式,低维空间下,使用更重长尾分布的t 分布替代高斯分布代表两点之间的相似度。来避免拥挤问题。
2.1 Symmetric SNE
优化pi|j 和qi|j 的KL散度的替换思路是使用联合概率分布来替换条件概率分布,即P是高维空间中各个点的联合概率分布,Q是低维空间下的,目标函数为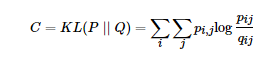
这里1的pii和qii都为0,这种SNE称为symmetric SNE,因为他假设了对于任意i,pij =pji,qij=qji,因此概率分布可以改写为:
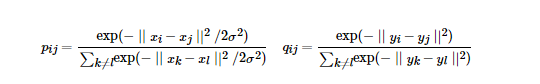
这种方法会引入异常值的问题,比如xi 是异常值,那么||xi-xj||2 会很大,对应的所有的j,pij 都会很小,导致低维映射下yi对cost的影响很小。为了解决这个问题,会将联合概率分布做一个修正。
2.2 Crowing 问题
各个簇聚在一起,无法区分,比如高维数据在降维到10维下,会有很好的表达,但是降维到2维后,无法得到可信映射。
如何解决: 用sight repulsion的方法
2.3 t-SNE
对称SNE时间上在高维度下,另一种减轻拥挤问题的方法: 在高维空间下使用高斯分布将距离转换为概率分布,在低维空间下,使用t 分布将距离转换为概率分布,使得高维度下中低等的距离在映射后能够有个较大的距离。
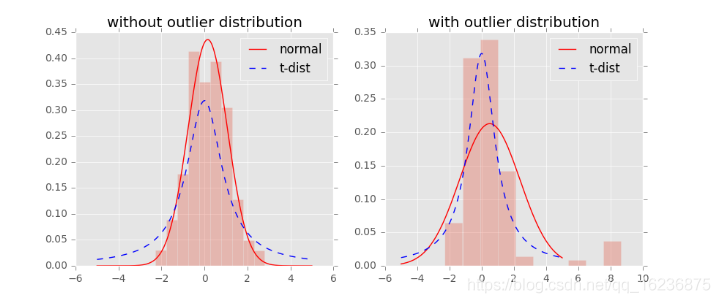
t 分布受异常值影响更小,拟合介个更为合理,较好的捕获了数据的整体特征。
t-SNE 的梯度更新有两大优势:
对于不相似的点,用一个较小的距离会产生较大的梯度来让这些点排斥开来。
这种排斥又不会无限大(梯度中分母) ,避免不相似的点距离太远。
2.4 算法过程
Data: X=x1,....xn
计算cost function 的参数
优化参数: 设置迭代次数T,学习速率n,动量![]()
目标结果是低维数据表示,YT=y1,...,yn
开始优化:
计算给定Perp 下的条件概率,pj|i
令pij=(pj|i +pi|j)/2n
用N(0,10-4I) 随机初始化Y
迭代,从t=1 到T,做如下的操作:
计算低维度下的qij ,计算梯度,更新Yt
结束
2.5 不足
1 主要用于可视化,
2 倾向与保存局部特征
3 没有唯一最优解
4 训练很慢