只选了一个股票,做了特征的重要性以及预测值和实际值对比的图,后面附实现代码。尚未做GridSearchCV。
(参数和代码部分还没优化,万里长征只迈出0.1步)。
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use(‘TkAgg’)
import matplotlib.pyplot as plt
import sklearn
from sklearn.model_selection import TimeSeriesSplit
from FeaturesUtil import *
from sklearn.ensemble import ExtraTreesRegressor
import tushare as ts
import MySQLdb as mdb
import csv
from sklearn.metrics import r2_score
pro=ts.pro_api()
con = mdb.connect(host=‘localhost’,user=‘root’,db=‘lqj’,passwd=‘123456’,use_unicode=True,
charset=‘utf8’)
sql = ‘select ts_code as code from lectr’
code = pd.read_sql(sql,con)
print(code[:2])
print(len(code))
for i in range(1):
#获得日交易价格
price = pro.daily(ts_code = code['code'][i],start_date = '20160101',end_date = '20190101')
result = pd.DataFrame(index = price.index)
result[['close','open','high','low']] = price['close'].shift(1)
result['close']=result['close'].replace(np.nan,0)
#计算feature值
indicators1 = [('KAMA',KAMA),('CCI',CCI),('ROC',ROC),('EVM',EVM),('ForceIndex',ForceIndex),('SMA',SMA),('EMA',EMA)]
for indicator,f in indicators1:
result[indicator] = f(result,5)
result['ADL'] = ADL(result)
ce = CE(result,5)
for col in (ce.columns):
result[col] = ce[col]
aroon = Aroon(price,5)
for col in (aroon.columns):
result[col] = aroon[col]
result = result.replace(np.nan,0.001)
#获得训练的X和Y数据集
X = result
y = price['close']
print(len(X))
print(len(y))
#划分训练集和预测集
tscv = TimeSeriesSplit(n_splits=5)
data=tscv.split(X)
a=[]
for train_index,test_index in data:
a.append((train_index,test_index))
forest = ExtraTreesRegressor(n_estimators=250,random_state=0)
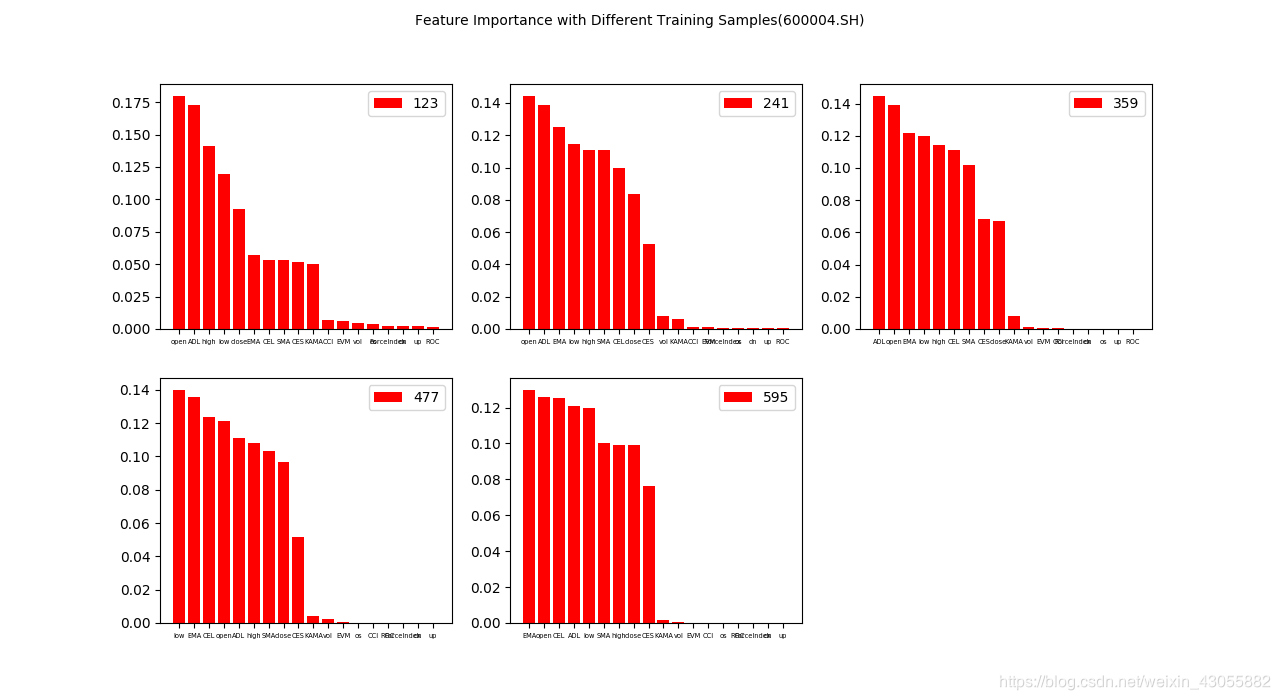
#计算importance并作图:
for i,index in enumerate(a):
X_train,y_train = X.iloc[index[0]],y.iloc[index[0]]
forest.fit(X_train,y_train)
importances = forest.feature_importances_
imp = pd.DataFrame(importances,index = result.columns)
imp = imp.sort_values(by=0)[::-1]
index = imp.index
values = imp.values.flatten()
plt.subplot(2,3,i+1)
plt.bar(index,values,label = len(X_train),color = ‘red’)
plt.xticks(fontsize = 4.8)
plt.legend(loc = 0)
plt.suptitle(“Feature Importance with Different Training Samples(600004.SH)”,fontsize=10)
plt.show()
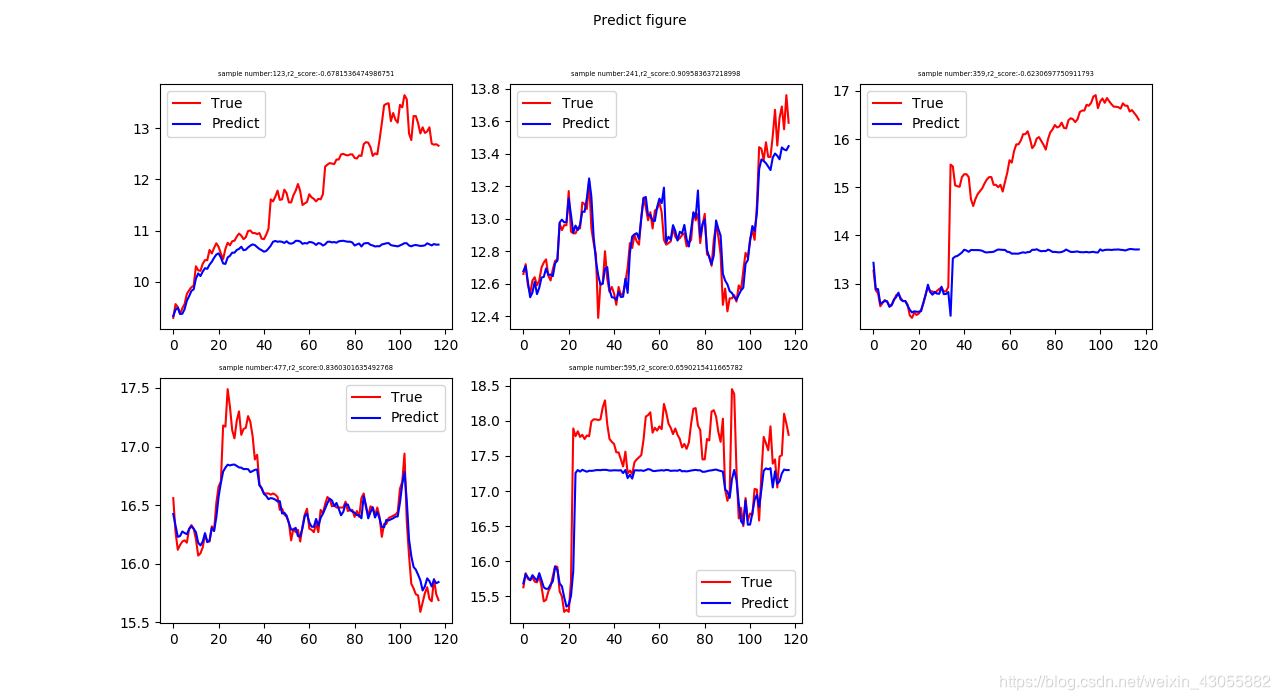
#predict并作图:
for i,index in enumerate(a):
X_train,y_train = X.iloc[index[0]],y.iloc[index[0]]
X_test,y_test = X.iloc[index[1]],y.iloc[index[1]]
forest = ExtraTreesRegressor(n_estimators=250,random_state=0)
forest.fit(X_train,y_train)
y_pred = forest.predict(X_test)
error = y_test - y_pred
d = r2_score(y_test,y_pred)
plt.subplot(2,3,i+1)
plt.plot(np.arange(len(y_test)),y_test,‘r’,label = ‘True’)
plt.plot(np.arange(len(y_test)),y_pred,‘b’,label = ‘Predict’)
plt.title(‘sample number:%s,r2_score:%s’ % (len(X_train),d),fontsize = 4.8)
plt.legend(loc = 0)
plt.suptitle(“Predict figure”,fontsize=10)
plt.show()