因为有很多事情耽搁了,今天终于完成了Transformer的完整学习,接下来,将分为三篇文章来进行记录:
3. 相关代码解读
其实,最重要的就是这篇代码解读,只是看懂了论文,其实并不是真的懂了,对于我这码农,最重要的还是要能把论文变成代码,还好,伟大的github上,果然有我需要的代码,所以我赶紧下载下来,开始研读。github链接
比较不幸运的是,github作者在前阵子刚更新了代码,所以其github上的代码会与我接下来讲的内容会有些出入。
一. 文件结构
hyperparams.py 包含所需的所有参数prepro.py为源和目标创建词汇表文件data_load.py包含有关加载和批处理数据的函数modules.py具有用于编码器/解码器网络的所有构建块train.py模型整体架构eval.py用于测试
二. 模型结构
看了好久的代码,整理了一段不短地时间,终于把模型的架构,以及重要的代码块都理解了。一下是整理出来的模型结构。

三. 部分代码解读
1. position: 由于Attention没有像RNN那样有前后关系这一特性,所以加入位置编码来获取字词在居中的位置。
这一部分的代码就比较简单了,就是将论文中的公式复现。
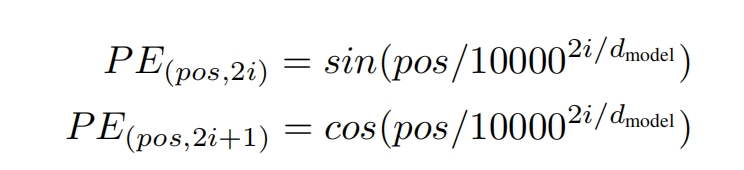
position_ind = tf.tile(tf.expand_dims(tf.range(T), 0), [N, 1])
# First part of the PE function: sin and cos argument
position_enc = np.array([
[pos / np.power(10000, 2. * i / num_units) for i in range(num_units)]
for pos in range(T)])
# Second part, apply the cosine to even columns and sin to odds
position_enc[:, 0::2] = np.sin(position_enc[:, 0::2]) # dim 2i
position_enc[:, 1::2] = np.cos(position_enc[:, 1::2]) # dim 2i + 1其中,T表示的是句子的词数(实际长度为hp.maxlen)。
2. key_masks:
key_masks = tf.expand_dims(tf.sign(tf.reduce_sum(tf.abs(self.enc), axis=-1)), -1)这个key_masks的作用我并不是很缺人,目前认为,其是为了增强有词的部分和弱化没有<padding>的部分
3. feedward
with tf.variable_scope(scope, reuse=reuse):
# Inner layer
params = {"inputs": inputs, "filters": num_units[0], "kernel_size": 1,
"activation": tf.nn.relu, "use_bias": True}
outputs = tf.layers.conv1d(**params)
# Readout layer
params = {"inputs": outputs, "filters": num_units[1], "kernel_size": 1,
"activation": None, "use_bias": True}
outputs = tf.layers.conv1d(**params)
# Residual connection
outputs += inputs
# Normalize
outputs = normalize(outputs)feedforward层是有两层卷积层拼接而成的,进行进一步的特征提取,其中第一层,将每个特征值变成四个特征值,然后第二层再将这些得到的四个特征值们拼接起来,再提取成1个特征值。这里就不具体介绍卷积相关的知识了。
4. multihead_Attention -- encoder
# Linear projections
Q = tf.layers.dense(queries, num_units, activation=tf.nn.relu) # (N, T_q, C)
K = tf.layers.dense(keys, num_units, activation=tf.nn.relu) # (N, T_k, C)
V = tf.layers.dense(keys, num_units, activation=tf.nn.relu) # (N, T_k, C)
# Split and concat
Q_ = tf.concat(tf.split(Q, num_heads, axis=2), axis=0) # (h*N, T_q, C/h)
K_ = tf.concat(tf.split(K, num_heads, axis=2), axis=0) # (h*N, T_k, C/h)
V_ = tf.concat(tf.split(V, num_heads, axis=2), axis=0) # (h*N, T_k, C/h)
# Multiplication
outputs = tf.matmul(Q_, tf.transpose(K_, [0, 2, 1])) # (h*N, T_q, T_k)
# Scale
outputs = outputs / (K_.get_shape().as_list()[-1] ** 0.5)
# key Masking
key_masks = tf.sign(tf.reduce_sum(tf.abs(keys), axis=-1)) # (N, T_k)
key_masks = tf.tile(key_masks, [num_heads, 1]) # (h*N, T_k)
key_masks = tf.tile(tf.expand_dims(key_masks, 1), [1, tf.shape(queries)[1], 1]) # (h*N, T_q, T_k)
paddings = tf.ones_like(outputs) * (-2 ** 32 + 1)
outputs = tf.where(tf.equal(key_masks, 0), paddings, outputs) # (h*N, T_q, T_k)
# Causality = Future blinding
if causality:
diag_vals = tf.ones_like(outputs[0, :, :]) # (T_q, T_k)
tril = tf.linalg.LinearOperatorLowerTriangular(diag_vals).to_dense() # (T_q, T_k)
masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(outputs)[0], 1, 1]) # (h*N, T_q, T_k)
paddings = tf.ones_like(masks) * (-2 ** 32 + 1)
outputs = tf.where(tf.equal(masks, 0), paddings, outputs) # (h*N, T_q, T_k)
# Activation
outputs = tf.nn.softmax(outputs) # (h*N, T_q, T_k)
# Query Masking
query_masks = tf.sign(tf.reduce_sum(tf.abs(queries), axis=-1)) # (N, T_q)
query_masks = tf.tile(query_masks, [num_heads, 1]) # (h*N, T_q)
query_masks = tf.tile(tf.expand_dims(query_masks, -1), [1, 1, tf.shape(keys)[1]]) # (h*N, T_q, T_k)
outputs *= query_masks # broadcasting (N, T_q, C)
# Dropouts
outputs = tf.layers.dropout(outputs, rate=dropout_rate, training=tf.convert_to_tensor(is_training))
# Weighted sum
outputs = tf.matmul(outputs, V_) # (h*N, T_q, C/h)
# Restore shape
outputs = tf.concat(tf.split(outputs, num_heads, axis=0), axis=2) # (N, T_q, C)
# Residual connection
outputs += queries
# Normalize
outputs = normalize(outputs) # (N, T_q, C)这里的第一个key_masks, query_masks是为了防止<pad>词加入到前向运算中,这是因为无论你的<pad>是否有可用的词编码,经过mask矩阵后,这个词编码都会被抛弃掉,置为0,那么这就不会参与到实际的运算中。但是,反向传播仍然会更新<pad>的词向量。
其中的大部分运算时参照公式:
5.multihead_Attention -- decoder
# Causality = Future blinding
if causality:
diag_vals = tf.ones_like(outputs[0, :, :]) # (T_q, T_k)
tril = tf.linalg.LinearOperatorLowerTriangular(diag_vals).to_dense() # (T_q, T_k)
masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(outputs)[0], 1, 1]) # (h*N, T_q, T_k)
paddings = tf.ones_like(masks) * (-2 ** 32 + 1)
outputs = tf.where(tf.equal(masks, 0), paddings, outputs) # (h*N, T_q, T_k)接下来的这部分代码,可以说是seq2seq中最重要的部分了,这段代码使得Attention在计算中,前面的词不会考虑后面的词,这是怎么做到的呢? 首先,这次的mask矩阵的样子跟其他的不同,他是一个只有左下角和对角线全是1,其他都是0的矩阵,这样就能保证前面的词与后面的词运算的结果被遮掉。读者可以直接拿上一个向量[a, b, c], 以及对应的mask矩阵进行尝试。最后就会发现,结果的第一行,只有a,第二行只有a,b。
四. 总结
终于写完啦,妥了两个星期,中间多了很多事情,终于有一点点空余时间让我来把这些事情给做完。真好