前言
众所周知,在存储系统中,为了保障数据的高可用性,我们会通过保存多个副本来防止因为机器物理故障导致数据丢失的现象。在一个集群(数据中心)内,我们会设定多个副本。甚至我们做的时候做的更完善一些,还做到异地数据的同步,这可能是完全集群的数据同步了。当然企业将数据做到异地多活本身初衷没用问题,但是成本开销一定还是有的,这意味着副本数据其实又进行了double。这里面的成本效益其实是不低的。本文笔者结合最近在看的一篇关于分级副本的理论,来聊聊这个话题。
传统三副本模式是否从根本上解决数据丢失问题
在阐述本文主题前,我们先来探讨一个关键问题:传统三副本模式是否从根本上解决数据丢失问题?有人会说了,我将数据做了3份冗余,应该会是很安全了吧。其实问题并没有那么简单,我们继续往下看。
数据的丢失起因在这里我们姑且把它归为节点的故障,宕机。那么节点的故障又可以分为以下两类:
- 单一节点故障(independent node failures),故障原因可能是机器硬件老化,突发故障等等。
- 相关节点故障(correlated node failures),故障原因可能是任务跑满了节点资源,OOM,电源断电,等等。此类型牵扯到的节点数据就可能会比较多。
那么针对相关节点故障的极大不确定性,传统固定模式的3副本显然也就不是绝对稳妥安全的了。
另外一方面,当副本设置的足够多的情况下,后面多余的副本有时只是为了提高冗余性,其实它很少被访问到(因为系统每次总会返回前面的副本数据给客户端),除非前面的副本因为故障导致数据需要恢复时。因此我们说,单独以线性扩展方式提高副本数,看起来并不是一种理想的兼具成本性和提高数据容错性的方案。这里面还有一个重要的控制因素:数据分布策略。
Copyset数据分布策略
这里我们要引入一个叫Copyset,它指的是一组存储了所有副本数据的存储节点集合。我们将系统节点在逻辑上进行集合划分,然后选择集合进行副本放置。如果说,我们能保证这些Copyset集合节点只有极小概率情况同时会挂,那么对于其上的数据丢失率也会变得很低。所以Copyset的划分就显得很关键了,我们可对Copyset做一些约束标签,比如保证每个Copyset里的节点由不同的电源所控制。这样当data center想要关掉一部分设施时,数据还是能够得到保障。
下面是一组Copyset的集合划分样例,

当然,我们也可以将副本放置在多个不同的Copyset里,这里我们保证每个Copyset的划分都是不重复的。
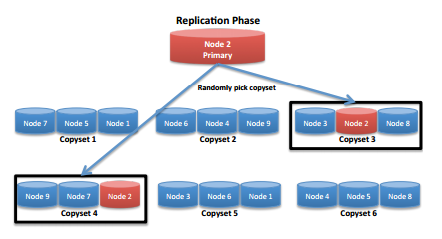
Copyset的选择存储要比纯Random模式的replication在数据丢失率上会提升很多,但它还不是最完美的。比如它还是没有彻底解决异地数据的灾备问题,这种模式下,我们还是得进行full-cluster的replication。
分级存储
在最近的一篇paper,介绍了一种更具成本效益的geo-replication,来解决数据异地双活的问题。相比较于传统整个集群进行同步备份的模式(以来防止data center级别的故障情况),分级存储是从副本级别进行处理的,比方说我们还是有3个副本,我们设定副本1,副本2位primary replica,它位于主数据中心内的集群上,而第三个副本我们把它放到remoter site。这样就构成了一个tier的关系。
因为第三个副本只有在2个primary replica同时坏掉时,才会被访问到,所以平时的访问率是比较低的。而且由于第三个副本的特殊性,我们可以采用写性能较好,读性能一般的介质来存储这样的数据。而且因为副本是across site/data center的,所以一定程度上做到了异地的保障。所以相比较于Full Cluster Geo-replication方案,Tier replciation更具成本效益。
引用
[1].https://web.stanford.edu/~skatti/pubs/usenix13-copysets.pdf
[2].https://www.usenix.org/system/files/conference/atc15/atc15-paper-cidon.pdf