目录
一、ListDataset类基本概念和原理
ListDataset类是一个用于处理和操作图像数据集的类,它允许以列表的形式组织图像和标签,从而实现更高效的数据加载。ListDataset基于PyTorch的Dataset类,通过使用ListDataset,我们可以轻松地处理大规模数据集,并利用PyTorch的DataLoader实现并行加载和批量处理。
Dataset类是PyTorch中用于表示数据集的抽象类。数据集是一个包含输入数据和对应标签的集合,可以用于训练、验证或测试机器学习模型。Dataset类提供了一个框架,使得我们可以自定义数据集,并对数据集进行各种操作,如添加、删除、排序等。
Dataset类的核心方法是__getitem__和__len__。__getitem__方法用于获取数据集中的一个样本,__len__方法则返回数据集中样本的数量。此外,Dataset类还提供了一些其他方法,如__add__、__getslice__等,用于对数据集进行操作。
创建Dataset类的实例通常需要提供一些数据,以及对该数据的描述,如每个样本的维度、标签等。例如,我们可以创建一个自定义的Dataset类,用于加载和处理图像数据集。在该Dataset类中,我们可以定义__getitem__方法来获取图像和对应的标签,并对其进行预处理。我们还可以定义__len__方法来返回数据集中样本的数量。通过使用Dataset类,我们可以更方便地管理和处理图像数据集,并将其用于深度学习模型的训练和测试。
二、ListDataset类的构建及使用
1、类的初始化
首先,需要定义一个类的初始化函数,用于创建对象时初始化该对象的属性。
def __init__(self, list_path, img_size=416, augment=True, multiscale=True, normalized_labels=True):
with open(list_path, "r") as file:
self.img_files = file.readlines()
self.label_files = [
path.replace("images", "labels").replace(".png", ".txt").replace(".jpg", ".txt")
for path in self.img_files
] #找到图片对应的label文件路径
self.img_size = img_size
self.max_objects = 100
self.augment = augment #数据增强
self.multiscale = multiscale
self.normalized_labels = normalized_labels
self.min_size = self.img_size - 3 * 32
self.max_size = self.img_size + 3 * 32
self.batch_count = 0
其中,下列是部分参数详解:
def __init__(self, list_path, img_size=416, augment=True, multiscale=True, normalized_labels=True):定义该函数接受五个参数,分别是list_path(图像文件和标签文件的路径列表)、img_size(图像大小)、augment(是否进行数据增强)、multiscale(是否进行多尺度训练)和normalized_labels(是否对标签进行归一化)。self.img_files = file.readlines():将文件中的所有行读取到一个列表中,并将该列表赋值给对象的img_files属性。self.augment = augment:将传入的augment赋值给对象的augment属性,表示是否进行数据增强。self.multiscale = multiscale:将传入的multiscale赋值给对象的multiscale属性,表示是否进行多尺度训练。self.normalized_labels = normalized_labels:将传入的normalized_labels赋值给对象的normalized_labels属性,表示是否对标签进行归一化。self.batch_count = 0:将0赋值给对象的batch_count属性,表示当前批次计数。
注:list_path可以为训练文件或者测试文件的路径,而在Yolo中一般将数据集相关信息放置在.data文件中,具体信息如下图所示:
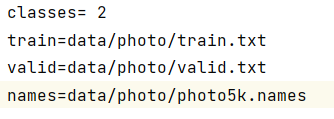
在训练YOLO模型时,需要使用.data文件来加载训练集数据,以便模型能够学习从图像中检测目标对象。.data文件通常由人类标注人员创建和维护,其中包含了每个图像的标注信息。具体来说,.data文件通常包含以下信息:
- 图像文件的路径:每个图像的路径都被记录在
.data文件中,以便模型在训练时可以访问这些图像。 - 类别标签:每个目标对象分配一个类别标签,例如"人"、"车辆"、"动物"等。这些类别标签也会存储在
.data文件中。 - 类的种数:类别标签的种数,如本次分类共有“苹果”和”橙子“两种,则在.data文件中记录类别标签的种数为2。
- 其他信息:根据实际需要,还可以在
.data文件中存储其他相关信息,例如图像的标签、训练集的划分等。
.data文件是YOLO配置文件中的重要组成部分,它提供了模型训练所需的数据集信息,以确保模型能够正确地检测目标对象。
2、数据加载
在进行初始化后,我们需要从一个图像数据集中获取一个特定的图像及其对应的标签。
def __getitem__(self, index):
img_path = self.img_files[index % len(self.img_files)].rstrip()
img_path = r'D:\shujia\yolo1\PyTorch-YOLOv3\data\photo' + img_path#图像路径
#print (img_path)
# Extract image as PyTorch tensor
img = transforms.ToTensor()(Image.open(img_path).convert('RGB'))
# Handle images with less than three channels
if len(img.shape) != 3:
img = img.unsqueeze(0)
img = img.expand((3, img.shape[1:]))
_, h, w = img.shape
h_factor, w_factor = (h, w) if self.normalized_labels else (1, 1)
# 当尺寸并不是标准的正方形,进行填充0。
img, pad = pad_to_square(img, 0)
_, padded_h, padded_w = img.shape
label_path = self.label_files[index % len(self.img_files)].rstrip()
label_path = r'D:\shujia\yolo1\PyTorch-YOLOv3\data\photo' + label_path#标签路径下列为部分参数详细解释:
img_path和label_path:从self.img_files和self.label_files中根据索引提取的文件路径。这里使用index % len(self.img_files)是为了实现循环使用文件列表。- h,w:图像的高度和宽度。如果
self.normalized_labels为True,那么h_factor和w_factor被设为实际的高度和宽度,否则设为1。 pad_to_square(img, 0):如果图像尺寸不是标准的正方形,那么通过在图像的右侧和底部填充0像素将其调整为正方形。
上述代码从一个图像数据集中获取一个特定的图像及其对应的标签。图像和标签文件的名字都储存在self.img_files和self.label_files中,这两个列表根据输入的索引(index)来选择对应的文件。
3、图像数据及标签数据预处理
在将图像的数据加载之后,还需要对其及标签数据进行相关处理,以便后续的目标检测或物体定位任务使用。
targets = None
if os.path.exists(label_path):
boxes = torch.from_numpy(np.loadtxt(label_path).reshape(-1, 5))
# Extract coordinates for unpadded + unscaled image,
# COCO数据集中的.txt文件每个字段的含义:
# class_num:类别编号,从1开始。
# box_cx:归一化后的中心横坐标,即像素坐标的cx除以图像宽度的结果。
# box_cy:归一化后的中心纵坐标,即像素坐标的cy除以图像高度的结果。
# box_w:归一化后的标注框宽度,即标注框宽度除以图像宽度的结果。
# box_h:归一化后的标注框高度,即标注框高度除以图像高度的结果。
x1 = w_factor * (boxes[:, 1] - boxes[:, 3] / 2)
y1 = h_factor * (boxes[:, 2] - boxes[:, 4] / 2)
x2 = w_factor * (boxes[:, 1] + boxes[:, 3] / 2)
y2 = h_factor * (boxes[:, 2] + boxes[:, 4] / 2)
# Adjust for added padding
x1 += pad[0]
y1 += pad[2]
x2 += pad[1]
y2 += pad[3]
# Returns (x, y, w, h)
boxes[:, 1] = ((x1 + x2) / 2) / padded_w
boxes[:, 2] = ((y1 + y2) / 2) / padded_h
boxes[:, 3] *= w_factor / padded_w
boxes[:, 4] *= h_factor / padded_h
targets = torch.zeros((len(boxes), 6))
targets[:, 1:] = boxes
# Apply augmentations图像增强
if self.augment:
if np.random.random() < 0.5:
img, targets = horisontal_flip(img, targets)
return img_path, img, targets
下面是相关参数详解:
boxes: 这是一个torch张量,从label_path中读取的包含目标框信息的numpy数组转化而来。它的每一行对应一个目标框,每个目标框包含5个信息:类别编号、中心横坐标、中心纵坐标、宽度、高度。pad: 这是一个包含四个元素的列表,表示在图像周围添加的填充像素值。padded_w和padded_h: 这两个变量表示经过填充后图像的宽度和高度。
总的来说,此处作用主要是从给定的标签文件中读取目标框信息,然后对目标框进行一些坐标转换和处理,最后应用图像增强。这种处理在计算机视觉的任务中很常见,例如在物体检测或图像分类任务中。
三、总结
ListDataset类提供了一种方便的方式来加载和处理图像数据集,适用于各种机器学习任务中使用图像数据的情况。