版权声明:转载请注明出处--mosterRan https://blog.csdn.net/qq_35975685/article/details/84261854
Hadoop简介
Hadoop 的作者 Doug cutting, Google 在2003年-2004年公开了部分 GFS 和 Mapreduce 思想的细节,以此为基础 Doug Cutting 等人用了2年业余时间实现了 DFS 和 Maperduce机制,一个微缩版:Nutch。在2005年秋天作为 Lucene 的子项目 Nutch的一部分正式引入 Apache 基金会。2006年3月份,Map-Reduce 和 Nutch Distributed File System(NDFS)分别被纳入为 Hadoop 的项目。
Hadoop由三个核心部分组成
- 分布式存储系统HDFS(Hadoop Distributed File System)
- 分布式式存储系统
- 提供了高可靠性、高扩展性和高吞吐率的数据存储服务
- 分布式计算框架MapReduce
- 分布式计算框架(计算向数据移动)
- 具有 易于编程、高容错性和高扩展性等优点
- 分布式资源管理框架YARN(Yet Another Resource Management)
- 负责集群资源的管理和调度
Hadoop-HDFS 存储模型
想一下我们正常存储一个文件,如果它很小如1KB或1MB或1GB这都可以在我们目前的电脑或者服务器存下,但是如果是一个很大很大的文件,我们该怎么办如每人的电脑硬盘1T,但是这个文件大小为10T,我们可以将10T分成10份然后存在10个人的电脑当中即可。同样的HDFS也是这个思想,将一个大文件进行线性切割成快(Block)然后存放在不同的服务器上,但很快你又会提出一个问题,如果一个字比如“存”在UTF-8当中占3个字节,而恰巧一个服务器存了1个字节而另外的2个字节存到了别的服务器上,这会出现我们使用的时候出现乱码,这个问题呢HDFS也帮我们解决了。后面会提到副本,相当于把文件克隆然后会进行一个修复操作。然后不同的文件分布到了不同的服务器上,所以是只允许写一次可以多次读取,那么HDFS存储模型的特点也就明显了。
- 文件线性切割成块(Block):偏移量 offset (byte)
- Block分散存储在集群节点中
- 单一文件Block大小一致,文件与 文件可以不一致
- Block可以设置副本数,副本分散在不同节点中
- 副本数不要超过节点数量(超过多余的副本会重复将浪费空间)
- 文件上传可以设置Block大小和副本数
- 已上传的文件Block副本数可以调整,大小不变
- 只支持一次写入多次读取,同一时刻只有一个写入者(避免修改后要变动后面所有节点的偏移量)
- 可以append追加数据
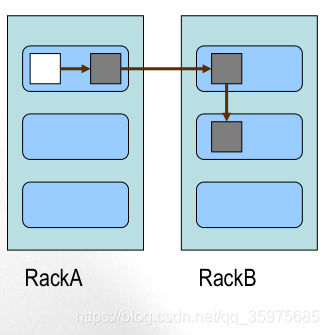
Block的副本放置策略
- 第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
- 第二个副本:放置在于第一个副本不同的 机架的节点上。
- 第三个副本:与第二个副本相同机架的节点。
更多副本:随机节点
架构模型
- 文件元数据MetaData,文件数据
- 元数据
- 数据本身
- (主)NameNode节点保存文件元数据:单节点 posix
- (从)DataNode节点保存文件Block数据:多节点
- DataNode与NameNode保持心跳,提交Block列表
- HdfsClient与NameNode交互元数据信息
- HdfsClient与DataNode交互文件Block数据
NameNode相当于管理者记录DataNode的Block信息