2018-12-14
关键词: Zookeeper入门介绍 、 Zookeeper是什么、Zookeeper架构解析、Zookeeper应用场景、Zookeeper有什么用
本篇文章系笔者依据当前所掌握的知识对 Zookeeper 作出的一个启蒙式介绍,不对文章的绝对、完全正确性负责。
Zookeeper 对于大数据开发来说实在是太重要了! Zookeeper 是由雅虎研究院开发,现如今是 apache 基金会的一个顶级项目。本篇文章不会涉及太多专业知识,主要是想以聊天的方式向读者介绍一下笔者眼中的 Zookeeper 。
1、启蒙篇
1.1、Zookeeper 是什么?
官网上对于 Zookeeper 的一句话介绍是:一款支持高可用的分布式协调框架。这个介绍一看就显得它很高大上,不过对于很多初学者来说,可能就会一头雾水了。不仅官话很晦涩难懂,连市面上绝大多数教材在关于 Zookeeper 的介绍上都是狂甩那些让人懵圈的专业名词,什么配置维护啦,命名服务啦巴啦巴啦的。我就不喜欢这些一板一眼的东西。
说人话: Zookeeper 是一款用于在多台电脑之间同步消息用的。这话看起来就舒服多了吧!在分布式系统中,由于涉及到设备的物理隔离,各设备之间的消息传递、状态监控就变得极其重要且棘手。而 Zookeeper 就是为了解决这个问题而产生的。
那,Zookeeper 一般都在分布式系统中同步些什么消息呢?
a) 设备的状态信息
分布式系统中,我们非常关心其它机器当前的上/下线等状态。通常每一台机器上线后都会在 Zookeeper 上注册自己的信息以供集群中其它机器可以知晓自己上线了,同时自己也可以通过 Zookeeper 得知当前还有哪些机器在线。
b) 关键信息同步
这个 “关键信息” 其实就说的很模糊了。其实本质上任何信息都可以被称之为是关键信息,都可以被保存在 Zookeeper 上,但是由于 Zookeeper 每个节点的容量非常小,只有 1MB ,因此,只能将一些至关重要的信息保存在 Zookeeper 上。比如,HBase 会将至关重要的 meta 表的存储位置保存在 Zookeeper 上,任何有权限的客户端都可以通过 Zookeeper 得到存储地址后去访问 meta 信息。你看,即使 meta 表于 HBase 是至关重要的,但在 Zookeeper 上也仅仅是保存着其存储位置而非内容信息,由此,相信我们也大概知晓该将什么信息放在 Zookeeper 上了吧。当然这里仅仅是举个小例子,其实只要你考虑到它每个节点仅 1MB 的容量以后,你就可以根据你的业务需求在 Zookeeper 上存储任何数据。
好,我们来总结一下: Zookeeper 是一个在分布式系统之中分享消息用的开源软件框架。

zookeeper logo
1.2、Zookeeper 的应用场景
Zookeeper 一般在哪些场景下有应用呢?
这个问题真的不好回答。想象一下如果有人问你:“螺丝在哪些场景下有应用?” 你该如何回答?上至已经飞出太阳系的 “旅行者 1 号”,下及汽车手机甚至生物骨骼接驳,到处都能见到螺丝的应用场景。我猜,关于这个问题你很大可能是沉吟一会后给出回答:“哪里需要螺丝,螺丝就在哪里有应用” 。是的, Zookeeper 也是!
我们知道螺丝它的作用就是连接两个物理隔离物体,那么当我们需要将某两个物理隔离的物体连接起来的时候,就会要用到螺丝了。而 Zookeeper 嘛,前面已经说到它是用于在多台电脑之间分享消息用的,所以当我们的某个场景正好有这个需求时,那它就能有应用啦。比如,大名鼎鼎的 HBase 就是指望 Zookeeper 而活的。
一句话总结:Zookeeper 一般应用于有同步消息的分布式系统场景中。
这里额外探讨一个重要知识点:Zookeeper 的功能一般是如何来使用的?
我们一直在说 Zookeeper 是一个给分布式应用提供消息同步服务的框架,那分布式应用平时都是如何来使用它提供的服务的呢?从设计模式的角度来看,Zookeeper 是一个基于 “观察者模式” 而设计的框架。应用一般会通过向 Zookeeper “注册监听” 的方式来实时监听我们所感兴趣的数据。通常,一台机器在上线后,会主动连接配置好的 Zookeeper 集群,并向指定地址注册自己的信息或者请求消息监听,当监听的数据发生变化时,Zookeeper 就会主动向注册者发送回调消息。
1.3、Zookeeper 的架构与结构
Zookeeper 是比较 “小巧” 的框架,它的内部只有两种角色: 1. Leader; 2. Follower 。同时它还可以划分为: 1. 服务端; 2. 客户端。 其架构图直接盗用官网的图片展示如下

zookeeper 架构
什么是 “服务端” 与 “客户端” ?
在官网及其它教材上 Zookeeper 经常会被介绍为是一款为分布式应用提供协调服务的框架。所以它本质上也是提供服务用的。因此 “服务端” 是描述 Zookeeper 作为服务提供者的特性。一般我们说 Zookeeper ,都是在说它的服务端功能。
至于客户端,就是开放给人使用的了,我们一般会通过自带的客户端程序来查看当前服务端的状态及其存储的信息等。
关于 Leader 和 Follower
Leader 和 Follower 都是在服务端才有的角色划分。Zookeeper 在生产环境中都是以集群的状态来提供服务的。既然涉及到集群,那就必须得有一个人是 “说了算” 的。一个 Zookeeper 集群中,有且仅有一个 Leader 角色,其余的都是 Follower 。Zookeeper 本身是提供消息服务的,对于消息的基础操作莫过于 读和写 了。集群中所有成员都具有 读权限 。但只有 Leader 才具备 写权限 。
仅对 Leader 开放写权限的目的就是为了实现其 “数据一致性” 的。从上面架构图中可以看到,虽然客户端可以与任意一个 Follower 建立通信,但是客户端能与 Follower 直接通信的也仅有读取数据而已。如果客户端向某 Follower 发起 写请求 ,该 Follower 在接收到这个写请求后还是会将写请求操作转发给 Leader ,让 Leader 来实现真正的数据写入操作,不过这一过程对客户端而言是透明的。正如上面架构图所示,Leader 和 Follower 之间也会有很紧密的交互联系,这些联系一部分是数据同步,另一部分可能就是来自客户端的写请求了。值得一提的是,Zookeeper 会将数据完整地复制到所有机器上,这样才能实现客户端可以通过任意机器读取数据的功能。
关于 Zookeeper 的数据结构
Zookeeper 的数据结构和 Linux 文件系统结构是一样的。都是通过一个以 “ / ” 为根目录的目录树形结构。其结构图如下图所示
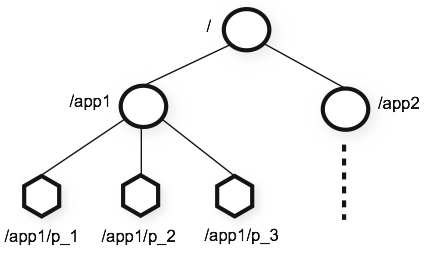
zk 目录树
不过 Zookeeper 的目录树与 Linux 的文件系统的目录树还有一个不同:Zookeeper 的目录名称本身是可以存储数据的。 以上图为例,在 Linux 文件系统中, app1 这个节点只能是作为 “目录” 存在,因为它内部还有子节点,app1 本身不能保存数据。而在 Zookeeper 中 app1 除了能有子节点以外,本身还能再保存数据。
在 Zookeeper 中,根节点 “ / ” 是默认存在的,并且在根目录内默认还有一个名称为 “zookeeper” 的子节点。每个节点都被称为 “znode” ,它既能再扩展子节点,也能保存一段数据,默认每个 znode 能存储 1MB 的数据。
Zookeeper 中的操作几乎都是发生在 znode 中的。znode 可分为两种类型:
1. 临时节点
又可分为普通节点和序列化节点。
2. 持久节点
又可分为普通节点和序列化节点。
关于临时节点和持久节点想必不用解释了吧。临时节点在会话结束后即会被销毁。序列化节点则是在你提供的节点名称后面自动加上一个用于标识当前节点在本路径下的序号,一般是用于防止因节点重名而建立失败的情况。不过序列化节点的用途可远不止于此,只是这里笔者为避免将知识点复杂化就不罗列了。
每个 znode 节点还会有一些描述该节点的基本信息,如下图所示,下图中 cZxid ~ numChildren 即为节点的属性信息
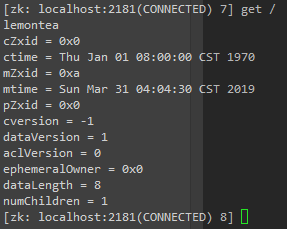
节点属性信息
不过笔者认为,对于初次接触的同学来说,不需要去纠结这些属性信息是什么。只需要知道有这么个东西就差不多了。
2、 实战篇
本来想着在这里贴出一篇使用 Java 写的示例程序以演示一下 Zookeeper 在分布式应用中的使用方式的。但似乎示例程序也过于简单,却又比较占篇幅,就算了。只在这里简单提一下吧,有兴趣的同学自己随便摸索一下都能写出来的。
通过前面我们知道临时节点的特性就是当会话断掉后即会被删除,而且节点还支持被各客户端注册状态改变的监听。利用这一特性就能很好地实现集群主机状态监控功能。因此,通常一台主机上线后,会立即在 Zookeeper 中注册一个自己并获取其它主机的节点信息。当某台主机宕机或断开连接后,其对应的节点信息就会被删除,并通知到其它节点主机中。主机之间需要同步什么信息,也是直接向事先约定的好路径写入数据即可。
2019-04-07 修改