目录
《Elasticsearch In Action》学习笔记。
熟悉SQL的用户一定对聚合不会陌生,简单说任何应用于group by的查询都会执行一个聚合操作。ES的聚合(aggregation)加载和搜索相匹配的文档,并且完成各种统计型的计算。
ES聚合分为两个主要类别:度量型和桶型。度量型(metric)聚合是指一组文档的统计分析,可以得到诸如最小值、最大值、标准差等度量值。桶(bucket)聚合将匹配的文档切分为一个或多个容器(桶),然后返回每个桶里的文档数量。桶聚合功能上实际就相当于SQL里的group by,SQL中叫组,ES中叫桶。有了桶聚合,可以嵌套其它的聚合,让子聚合在上层聚合所产生的每个文档桶上运行。ES这种所谓的嵌套聚合可以类比于SQL中的group by后面跟多个字段,但更为灵活。看图1的例子。
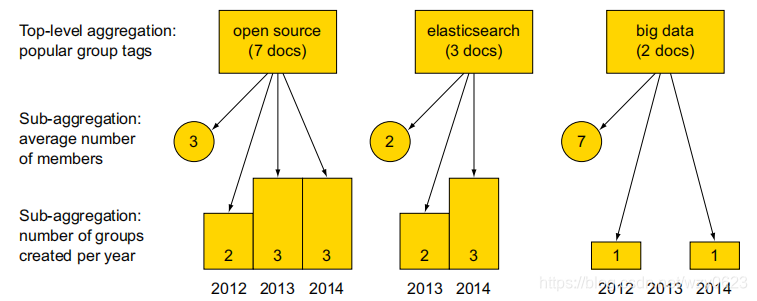
自上而下看图1,如果使用terms聚合获得最为流行的分组标签,同样可以获得每个标签分组的平均成员数量,还可以让ES提供每个标签每年创建的分组数量。用SQL不得不写两个查询来实现:
select tags, count(*), avg(members) from get-togather group by tags;
select tags, year, count(*) from get-togather group by tags, year;一、聚合的结构
所有聚合都遵从以下语法规则:
- 查询的JSON中定义它们,使用键aggregation或aggs标记。需要给每个聚合命名,指定它的类型以及该类型相关的选项。
- 聚合运行在查询的结果之上。和查询不匹配的文档不会计算在内,除非使用global聚合将不匹配的文档囊括其中。
- 以进一步过滤查询的结果,而不影响聚合。
(1)聚合请求的结构
下面的代码执行一个terms聚合,获得get-together中最频繁的标签。
curl '172.16.1.127:9200/get-together/_doc/_search?pretty' -H 'Content-Type: application/json' -d'
{
"aggs": { # 键aggs表明,这是该请求的聚合部分
"top_aggs": { # 聚合名称
"terms": { # 聚合类型为词条
"field": "tags.verbatim" # 未经分析verbatim字段,用于关键字完全匹配,而不是分词匹配
}
}
}
}'tags字段的映射为:
"tags" : {
"type" : "text",
"fields" : {
"verbatim" : {
"type" : "keyword"
}
}
}查询返回结果的聚合部分如下:
...
"aggregations" : {
"top_aggs" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 6,
"buckets" : [ # 每个唯一的词条都是桶里的一个项目
{
"key" : "big data", # 对于每个词条,可以看到它出现了多少次
"doc_count" : 3
},
{
"key" : "open source",
"doc_count" : 3
},
...
{
"key" : "data visualization",
"doc_count" : 1
}
]
}
}这个查询没有指定任何匹配条件,它执行match_all查询,所以聚合是在所有文档上进行的。
(2)运行在查询结果上的聚合
curl '172.16.1.127:9200/get-together/_doc/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query": {
"match": {
"location_group": "Denver"
}
},
"aggs": {
"top_aggs": {
"terms": {
"field": "tags.verbatim"
}
}
}
}'这个查询带了一个匹配条件。聚合总是在所有和查询匹配的结果上执行,因此查询中的from和size参数对于聚合没有影响。
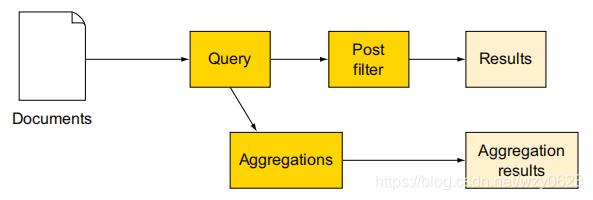
(3)过滤器和聚合
聚合只会在与过滤器查询匹配的文档上运行。
curl '172.16.1.127:9200/get-together/_doc/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"filter": {
"term": {
"location_group": "denver"
}
}
}
},
"aggs": {
"top_aggs": {
"terms": {
"field": "tags.verbatim"
}
}
}
}'过滤器上聚合的流程如图2所示。

还有另一种运行过滤器的方法:使用后过滤器(post filter),该过滤器是在查询结果之后运行,和聚合操作相独立。
curl '172.16.1.127:9200/get-together/_doc/_search?pretty' -H 'Content-Type: application/json' -d'
{
"post_filter": {
"term": {
"location_group": "denver"
}
},
"aggs": {
"top_aggs": {
"terms": {
"field": "tags.verbatim"
}
}
}
}'过滤器上聚合的流程如图3所示。
后过滤器和filtered查询中的过滤器有两点不同:
- 性能:后过滤器是在查询之后运行,确保查询在所有文档上运行。而过滤器只在和查询匹配的文档上运行,整体的请求通常比对等的filtered查询执行更慢,因为filtered查询中过滤器是先运行的,减少了聚合执行时处理的文档数量。
- 聚合处理的文档集合:如果一篇文档和后过滤器不匹配,它仍然会被聚合操作计算在内。
二、度量集合
度量聚合从不同文档的分组中提取统计数据,这些统计数据通常来自数值型字段。
(1)统计数据
通常来说,使用ES查询可以构建一个script字段,在其中放入一小段代码,为每篇文档返回一个数组。在下面的代码中,用脚本计算参与者数量,数值是参与者数组的元素数量。
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0, # 只关心聚合,返回任何查询结果
"aggs": {
"attendees_stats": {
"stats": {
"script": "doc['"'attendees'"'].values.length" # 生成参与者数量的脚本
}
}
}
}'返回结果如下:
...
"aggregations" : {
"attendees_stats" : {
"count" : 20,
"min" : 0.0,
"max" : 5.0,
"avg" : 2.9,
"sum" : 58.0
}
}
}聚合类型为统计,通过脚本为每篇文档生成一个参与者数量,统计结果包括参与者的最小值、最大值、求和以及平均值,还可以获知这些统计值是从多少文档计算而来的。
如果只需要这些统计值的其中一项,可以单独请求。
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"attendees_avg": {
"avg": {
"script": "doc['"'attendees'"'].values.length"
}
}
}
}'(2)高级统计
除了使用stats聚合收集统计数据,还可以通过运行extended_stats聚合来获取数值字段的平方值、方差和标准差。
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"attendees_extended_stats": {
"extended_stats": {
"script": "doc['"'attendees'"'].values.length"
}
}
}
}'返回结果如下:
...
"aggregations" : {
"attendees_extended_stats" : {
"count" : 20,
"min" : 0.0,
"max" : 5.0,
"avg" : 2.9,
"sum" : 58.0,
"sum_of_squares" : 230.0,
"variance" : 3.0900000000000007,
"std_deviation" : 1.7578395831246947,
"std_deviation_bounds" : {
"upper" : 6.415679166249389,
"lower" : -0.6156791662493895
}
}
}
}查询生成了和其匹配的文档集合,而所有统计数据都是通过该文档集合中的数值计算而来,所以总是具有100%的准确性。
(3)近似统计
某些统计可以通过查看文档中的某些数值,良好地进行计算,尽管不是100%准确,这将会减少执行的时间和内存消耗。下面的代码计算参与者的80百分位和99百分位。
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"attendees_percentiles": {
"percentiles": {
"script": "doc['"'attendees'"'].values.length",
"percents": [80, 99]
}
}
}
}'返回结果如下:
...
"aggregations" : {
"attendees_percentiles" : {
"values" : {
"80.0" : 4.0, # 80%的值不超过4
"99.0" : 5.0 # 99%的值不超过5
}
}
}
}还有一个percentile_ranks聚合,允许指定一组值,获得相应的文档百分比,而这些文档拥有所指定的值。
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"attendees_percentile_ranks": {
"percentile_ranks": {
"script": "doc['"'attendees'"'].values.length",
"values": [4, 5]
}
}
}
}'返回结果如下:
...
"aggregations" : {
"attendees_percentile_ranks" : {
"values" : {
"4.0" : 85.0,
"5.0" : 100.0
}
}
}
}基数(cardinality)是某个字段中唯一值的数量。下面的代码获得去重后的会员数量。
curl -X PUT "172.16.1.127:9200/get-together/_mapping/_doc?pretty" -H 'Content-Type: application/json' -d'
{
"properties": {
"members": {
"type": "text",
"fielddata": true
}
}
}'
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"members_cardinality": {
"cardinality": {
"field": "members"
}
}
}
}'返回结果如下:
...
"aggregations" : {
"members_cardinality" : {
"value" : 8
}
}
}cardinality聚合是近似的,其内存使用量是一个常数,可以通过precision_threshold参数配置。阈值越高,结果越精确,但是消耗的内存越多。很多情况下,默认的precision_threshold就能很好的运作,因为它提供了内存使用量的准确率之间一个良好的均衡,并且它会根据桶的数量自我调节。
三、桶型聚合
度量型聚合是获取所有的文档,并且生成一个或多个描述它们的数值。桶型聚合是将文档放入不同的桶中(类似SQL中的group by),对于每个桶,获得一个或多个数值来描述这个桶。用户可以将匹配查询的文档作为一个大桶。
(1)terms聚合
terms聚合统计的是每个词条,而不是整个字段,因此通常需要在一个非分析型的字段上运行这种聚合。默认情况下,词条的顺序是由词频决定的,并且降序排列。也可以按照词频升序或词条本身排序。下面代码中使用order属性,将标签按字母顺序排列。
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"tags": {
"terms": {
"field": "tags.verbatim",
"order": {
"_term": "asc"
}
}
}
}
}'返回结果如下:
...
"aggregations" : {
"tags" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 10,
"buckets" : [
{
"key" : "apache lucene",
"doc_count" : 1
},
{
"key" : "big data",
"doc_count" : 3
},
...
{
"key" : "hadoop",
"doc_count" : 1
}
]
}
}默认地,terms聚合会返回按序排列的前10个词条。可以通过size参数来修改这个数量。将size设置为0,将获得全部词条,但对于基数很高的字段,这样做是非常危险的,因为返回一个巨大的结果集要消耗大量CPU资源来排序,而且还可能阻塞网络。
为了得到前10个词条(或者是通过size所配置的数量),ES从每个分片获取一定数量的词条(可以通过shard_size配置)并且将这些结果聚集起来,整个过程如图4所示。为清楚起见,shard_size和size都设置为2。
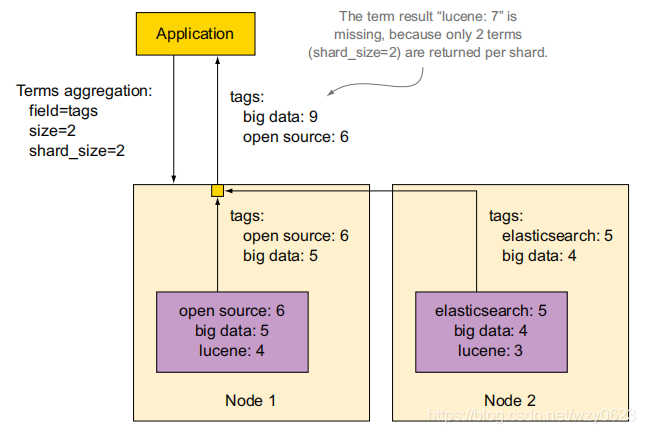
这种处理机制逻辑上是有明显缺陷的,对于某些未能在单个分片上名列前茅的词条(如图4中的lucene:7),很可能得不到正确的结果。通过加大shared_size的值,可以获得更准确的结果,如图5所示。但这样做使得聚集操作更为昂贵(尤其是在将它们嵌套起来时),因为内存中需要保存更多的桶。

聚合返回头部的值可以用来判断结果的准确性。
"tags" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 10,第一个数值是最坏情况下,错误的上限。例如,如果一个分片返回的词条最小词频为5,那么分片中出现4次的词条可能就会被遗漏。如果词条应该出现在最终结果中,那么最坏情况下的错误为4。所有分片的这些数值之和组成了doc_count_error_upper_bound。将show_term_doc_count_error设置为true,就可以获得每个词条的doc_count_error_upper_bound值。这会统计每个词条最坏情况下的错误。
第二个数值是未能排名靠前的词条之总数量。
可以使用include和exclude选项,在结果中包含特定的词,或者将特定的词从结果中剔除。单独使用include选项,只会包含匹配某个模式的词条;单独使用exclude选项,只会包含那些不匹配的词条。同时使用两者,exclude会有优先权:包含的词条会匹配include选项设置的模式,但是不会匹配exclude选项设置的模式。下面代码展示了如何只返回“search”的标签计数器。
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"tags": {
"terms": {
"field": "tags.verbatim",
"include": ".*search.*"
}
}
}
}'返回结果如下:
...
"aggregations" : {
"tags" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "elasticsearch",
"doc_count" : 2
},
{
"key" : "enterprise search",
"doc_count" : 1
}
]
}
}(2)significant_terms聚合
significant_terms聚合同terms聚合类似,也会统计词频。但是结果桶按照某个分数来排序,该分数代表了前台文档与背景文档之间的百分比差异。前台文档是那些与查询匹配的文档,而背景文档是当前索引中所有的文档。
下面的代码将发现哪些get-together的用户,和Lee有着类似的活动品味。为了实现这一点,将查询Lee所参加的活动(前台文档),然后使用significant_terms聚合来看看和整体所参加的活动(背景文档)相比,这些活动(前台文档)中哪些参与者出现得更频繁。
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"query": {
"match": {
"attendees": "lee" # 前台文档是Lee所参与的活动
}
},
"aggs": {
"significant_attendees": {
"significant_terms": { # 需要在这些活动中,相对于整体而言出现更频繁的参与者
"field": "attendees",
"min_doc_count": 2, # 只考虑至少参加2个活动的参与者
"exclude": "lee" # 排除Lee本身
}
}
}
}'返回结果如下:
...
"aggregations" : {
"significant_attendees" : {
"doc_count" : 5, # 所有Lee参加的活动数量是5
"bg_count" : 20, # 总活动数是20
"buckets" : [
{
"key" : "greg", # Greg参与了3个活动,全部和Lee一起参与
"doc_count" : 3,
"score" : 1.7999999999999998,
"bg_count" : 3
},
{
"key" : "mike", # Mike参与了两个活动,全部和Lee一起参与
"doc_count" : 2,
"score" : 1.2000000000000002,
"bg_count" : 2
},
{
"key" : "daniel", # Daniel参与了两个活动,其中有两个和Lee一起参与
"doc_count" : 2,
"score" : 0.6666666666666667,
"bg_count" : 3
}
]
}
}significant_terms聚合用SQL实现会相当复杂,而且很难保证性能。
(3)range聚合
下面的代码统计参与者少于4个、至少4个但少于6个、至少6个这三种情况的文档数量。注意范围是个左闭右开的区间,即桶包含了键from的值,但不包含键to的值。范围不必是连续的,它们可以是分离的或者重叠的。
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"attendees_breakdown": {
"range": {
"script": "doc['"'attendees'"'].values.length",
"ranges": [
{ "to": 4 },
{ "from": 4, "to": 6 },
{ "from": 6 }
]
}
}
}
}'返回结果如下:
...
"aggregations" : {
"attendees_breakdown" : {
"buckets" : [
{
"key" : "*-4.0",
"to" : 4.0,
"doc_count" : 9
},
{
"key" : "4.0-6.0",
"from" : 4.0,
"to" : 6.0,
"doc_count" : 11
},
{
"key" : "6.0-*",
"from" : 6.0,
"doc_count" : 0
}
]
}
}类似的SQL可能是下面这样:
select case when c < 4 then 1 else 0 end c4,
case when c >=4 and c < 6 then 1 else 0 end c4_6,
case when c > 6 then 1 else 0 end c6
from (select count(attendees) c, event_id
from get-together
group by event_id) t1; (4)date_range聚合
date_range聚合与range聚合一样运作,除了放在范围定义中的是日期字符串。下面代码将活动分为两个分类,即2013年7月之前和之后开始的。
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"dates_breakdown": {
"date_range": {
"field": "date",
"format": "YYYY.MM", # 定义日期格式
"ranges": [
{ "to": "2013.07" },
{ "from": "2013.07" }
]
}
}
}
}'返回结果如下:
...
"aggregations" : {
"dates_breakdown" : {
"buckets" : [
{
"key" : "*-2013.07",
"to" : 1.3726368E12,
"to_as_string" : "2013.07",
"doc_count" : 8 # 返回每个范围的文档数量
},
{
"key" : "2013.07-*",
"from" : 1.3726368E12,
"from_as_string" : "2013.07",
"doc_count" : 7
}
]
}
}(5)histogram聚合
histogram聚合不用手动定义每个范围,而是定义一个固定的距离,ES会自动构建多个范围。
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"attendees_histogram": {
"histogram": {
"script": "doc['"'attendees'"'].values.length",
"interval": 1 # 用于构建范围的间距
}
}
}
}'返回结果如下:
...
"aggregations" : {
"attendees_histogram" : {
"buckets" : [
{
"key" : 0.0, # key显示了范围的起始值。终止值是起始值加上间距值
"doc_count" : 5
},
{
"key" : 1.0, # 下一个起始值就是前一个的终止值
"doc_count" : 0
},
{
"key" : 2.0,
"doc_count" : 0
},
{
"key" : 3.0,
"doc_count" : 4
},
{
"key" : 4.0,
"doc_count" : 9
},
{
"key" : 5.0,
"doc_count" : 2
}
]
}
}(6)date_histogram聚合
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"event_dates": {
"date_histogram": {
"field": "date",
"interval": "1M" # 间距被指定为日期字符串
}
}
}
}'返回结果如下:
...
"aggregations" : {
"event_dates" : {
"buckets" : [
{
"key_as_string" : "2013-02-01T00:00",
"key" : 1359676800000,
"doc_count" : 1
},
{
"key_as_string" : "2013-03-01T00:00",
"key" : 1362096000000,
"doc_count" : 1
},
{
"key_as_string" : "2013-04-01T00:00",
"key" : 1364774400000,
"doc_count" : 2
},
{
"key_as_string" : "2013-05-01T00:00",
"key" : 1367366400000,
"doc_count" : 1
},
{
"key_as_string" : "2013-06-01T00:00",
"key" : 1370044800000,
"doc_count" : 3
},
{
"key_as_string" : "2013-07-01T00:00",
"key" : 1372636800000,
"doc_count" : 5
},
{
"key_as_string" : "2013-08-01T00:00",
"key" : 1375315200000,
"doc_count" : 0
},
{
"key_as_string" : "2013-09-01T00:00",
"key" : 1377993600000,
"doc_count" : 2
}
]
}
}四、嵌套聚合
1. 多桶聚合
图6所示的例子中,terms聚合允许用户展示get-together的热门标签,这意味着将每个标签创建一个文档桶。然后使用子聚合统计对于每个标签,每个月创建了多少文档。
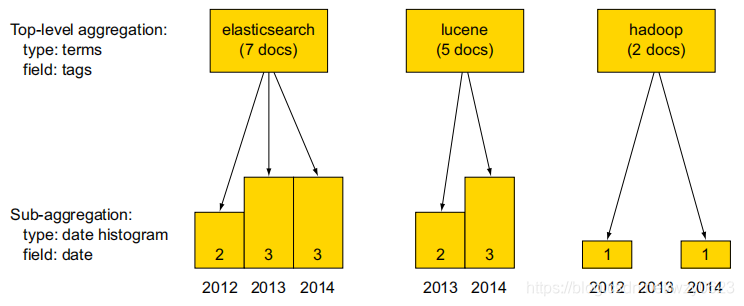
下面的代码是一个三层嵌套聚合的例子。
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": { # 词条聚合,获取标签
"top_tags": {
"terms": {
"field": "tags.verbatim"
},
"aggs": { # 对每个标签运行一次日期直方图子聚合
"groups_per_month": {
"date_histogram": {
"field": "created_on",
"interval": "1M"
},
"aggs": { # 对于标签 + 月份的桶,运行范围聚合
"number_of_members": {
"range": {
"script": "doc['"'attendees'"'].values.length",
"ranges": [
{
"to": 3
},
{
"from": 3
}
]
}
}
}
}
}
}
}
}'返回结果如下:
...
"aggregations" : {
"top_tags" : {
"buckets" : [ {
"key" : "big data", # big data包含3篇文档
"doc_count" : 3,
"groups_per_month" : {
"buckets" : [ { # 根据big data文档创建月份产生的桶
"key_as_string" : "2010-04-01",
"key" : 1270080000000,
"doc_count" : 1, # 这篇文档是2010年4月创建的
"number_of_members" : {
"buckets" : [
{
"key" : "*-3.0",
"to" : 3.0,
"to_as_string" : "3.0",
"doc_count" : 1 # 这篇文档包含的参与者少于3
},
{
"key" : "3.0-*",
"from" : 3.0,
"from_as_string" : "3.0",
"doc_count" : 0
} ]
}
},
{
"key_as_string" : "2012-08-01", # big data下一个桶创建的是2012年8月的
[...]类似的SQL可能是下面这样:
select count(1),tags,ym,case when ac < 3 then 0 else 1 end
from (select tags,
year(created_on) * 100 + month(created_on) ym,
length() - length(replace(attendees, ',', '')) ac
from together) t1
group by tags , ym , case when ac < 3 then 0 else 1 end下面的代码在attendees字段上运行了terms聚合,并在其中嵌套了top_hits聚合。它将展示最为活跃的参与者所参加的活动。
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"frequent_attendees": {
"terms": { # 词条聚合返回参与活动最多的两个用户
"field": "attendees",
"size": 2
},
"aggs": {
"recent_events": {
"top_hits": { # top_hits聚合返回实际的活动
"sort": {
"date": "desc" # 最近的活动排在前面
},
"_source": {
"include": [ # 选择要包含的字段
"title"
]
},
"size": 1 # 限制每个桶的结果数量
}
}
}
}
}
}'返回结果如下:
...
"aggregations" : {
"frequent_attendees" : {
"doc_count_error_upper_bound" : 1,
"sum_other_doc_count" : 50,
"buckets" : [
{
"key" : "lee", # Lee是最活跃的会员,参加了5个活动
"doc_count" : 5,
"recent_events" : {
"hits" : {
"total" : 5,
"max_score" : null,
"hits" : [
{
"_index" : "get-together",
"_type" : "_doc",
"_id" : "100",
"_score" : null,
"_routing" : "1",
"_source" : {
"title" : "Liberator and Immutant"
},
"sort" : [
1378404000000
]
}
]
}
}
},
{
"key" : "andy",
"doc_count" : 3,
"recent_events" : {
"hits" : {
"total" : 3,
"max_score" : null,
"hits" : [
{
"_index" : "get-together",
"_type" : "_doc",
"_id" : "110",
"_score" : null,
"_routing" : "4",
"_source" : {
"title" : "Big Data and the cloud at Microsoft"
},
"sort" : [
1375293600000
]
}
]
}
}
}
]
}
}类似的SQL可能是下面这样:
select attendees, id, titile
from (select t1.attendees,
t1.id,
t1.titile,
row_number() over (partition by t1.attendees order by t1.date1 desc) r
from get-together t1,
(select *
from (select attendees, count(*) c
from get-together
group by attendees
order by count(*) desc)
where rownum <=2) t2
where t1.attendees=t2.attendees
order by t2.c desc)
where r=1;2. 单桶聚合
默认情况下,ES在查询结果上运行聚合。如果想要改变这种默认行为,将要使用单桶聚合。
(1)global聚合
聚合创建一个桶,包含索引中的全部文档。当用户希望无论何种查询,都在所有文档上运行聚合时,这一点非常有用。如图7所示,想看整体的标签,并且和用户搜索无关。
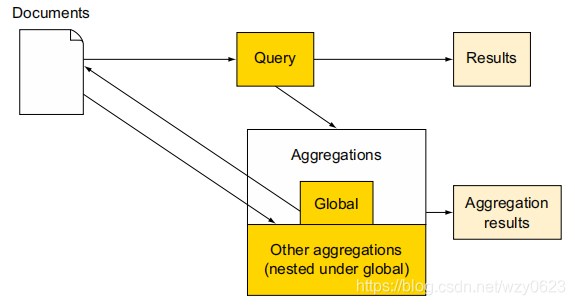
下面的代码中,将terms聚合嵌套在global聚合里,以此获得所有文档中的标签,即使查询只是查找了标题里含有“elasticsearch”字样的文档。
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"query": {
"match": {
"name": "elasticsearch"
}
},
"aggs": {
"all_documents": {
"global": {}, # 全局聚合是父聚合
"aggs": {
"top_tags": {
"terms": { # 词条聚合嵌套其中,将会运行在所有的数据上
"field": "tags.verbatim"
}
}
}
}
}
}'返回结果如下:
{
"took" : 24,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 2, # 查询返回两篇文档,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"all_documents" : {
"doc_count" : 20, # 聚合运行在所有20篇文档上
"top_tags" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 6,
"buckets" : [
{
"key" : "big data",
"doc_count" : 3
},
{
"key" : "open source",
"doc_count" : 3
},
{
"key" : "denver",
"doc_count" : 2
},
{
"key" : "elasticsearch",
"doc_count" : 2
},
{
"key" : "lucene",
"doc_count" : 2
},
{
"key" : "solr",
"doc_count" : 2
},
{
"key" : "apache lucene",
"doc_count" : 1
},
{
"key" : "clojure",
"doc_count" : 1
},
{
"key" : "cloud computing",
"doc_count" : 1
},
{
"key" : "data visualization",
"doc_count" : 1
}
]
}
}
}
}(2)filter聚合
filter聚合限制了聚合所统计的文档,而不影响查询结果,如图8所示。
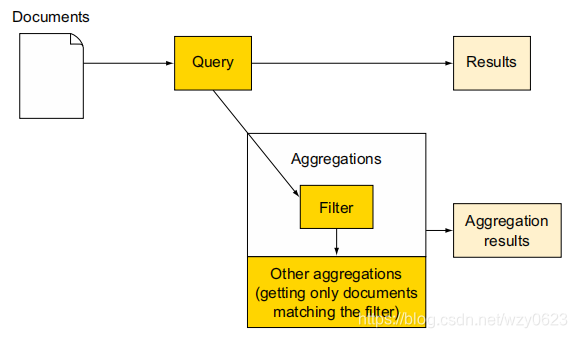
为了实现这一点,下面代码运行了一个查询,并加上了聚合。首先拥有一个filter聚合,将文档集合限制在7月1日之后,然后在其中嵌套了terms聚合。
curl -X PUT "172.16.1.127:9200/get-together/_mapping/_doc?pretty" -H 'Content-Type: application/json' -d'
{
"properties": {
"description": {
"term_vector": "with_positions_offsets",
"type": "text",
"fielddata": true
}
}
}'
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"query": {
"match": {
"title": "elasticsearch"
}
},
"aggs": {
"since_july": {
"filter": { # 过滤器查询定义了一个桶,子聚合将在这个桶上运行
"range": {
"date": {
"gt": "2013-07-01T00:00"
}
}
},
"aggs": {
"description_cloud": {
"terms": {
"field": "description"
}
}
}
}
}
}'返回结果如下:
{
"took" : 42,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 7, # 查询返回了7条文档
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"since_july" : {
"meta" : { },
"doc_count" : 2, # 而description_cloud过滤器只在和过滤器匹配的两个结果上运行
"description_cloud" : {
"doc_count_error_upper_bound" : 1,
"sum_other_doc_count" : 16,
"buckets" : [
{
"key" : "we",
"doc_count" : 2
},
{
"key" : "with",
"doc_count" : 2
},
{
"key" : "a",
"doc_count" : 1
},
{
"key" : "about",
"doc_count" : 1
},
{
"key" : "and",
"doc_count" : 1
},
{
"key" : "at",
"doc_count" : 1
},
{
"key" : "big",
"doc_count" : 1
},
{
"key" : "can",
"doc_count" : 1
},
{
"key" : "crunching",
"doc_count" : 1
},
{
"key" : "data",
"doc_count" : 1
}
]
}
}
}
}(3)missing聚合
missing聚合创建的桶包含了那些缺乏某个特定字段的文档。举例来说,可能有一个运行在活动日期字段的date_histogram聚合,但是某些活动还没有日期。用户可以通过missing聚合来统计它们。
URI=172.16.1.127:9200/get-together/_doc/_search
curl "$URI?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"event_dates": {
"date_histogram": {
"field": "date",
"interval": "1M"
}
},
"missing_date": {
"missing": {
"field": "date"
}
}
}
}' 返回结果如下:
{
"took" : 20,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 20,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"event_dates" : {
"buckets" : [
{
"key_as_string" : "2013-02-01T00:00",
"key" : 1359676800000,
"doc_count" : 1
},
{
"key_as_string" : "2013-03-01T00:00",
"key" : 1362096000000,
"doc_count" : 1
},
{
"key_as_string" : "2013-04-01T00:00",
"key" : 1364774400000,
"doc_count" : 2
},
{
"key_as_string" : "2013-05-01T00:00",
"key" : 1367366400000,
"doc_count" : 1
},
{
"key_as_string" : "2013-06-01T00:00",
"key" : 1370044800000,
"doc_count" : 3
},
{
"key_as_string" : "2013-07-01T00:00",
"key" : 1372636800000,
"doc_count" : 5
},
{
"key_as_string" : "2013-08-01T00:00",
"key" : 1375315200000,
"doc_count" : 0
},
{
"key_as_string" : "2013-09-01T00:00",
"key" : 1377993600000,
"doc_count" : 2
}
]
},
"missing_date" : {
"doc_count" : 5
}
}
}