聚合分析:英文为Aggregation,是es除搜索功能外提供的针对es数据做统计分析的功能。
- 功能丰富:提供
Bucket、Metric、Pipeline等多种分析方式,可以满足大部分的分析需求 - 实时性高:所有的计算结果都是即时返回的,而hadoop等大数据系统一般都是T+1级别的
例如聚合分析可以回答如下问题:
- 请告诉我最近1周每天的订单成交量有多少?
- 请告诉我最近1个月每天的平均订单金额是多少?
- 请告诉我最近半年卖的最火的前5个商品有哪些?
聚合分析分类:为了便于理解,es将聚合分析主要分为如下4类:
Bucket:分桶类型,类似SQL中的GROUP BY语法Metric:指标分析类型,如计算最大值、最小值、平均值等等Pipeline:管道分析类型,基于上一级的聚合分析结果进行在分析Matrix:矩阵分析类型
Metric聚合分析
Metric聚合分析分为单值分析和多值分析两类:
单值分析,只输出一个分析结果
min,max,avg,sum cardinality多值分析,输出多个分析结果
stats,extended stats percentile,percentile rank top hits
min,max,avg,sum
返回数值字段的最小值:
GET myindex/_search
{
"size": 0, #不返回文档列表
"aggs": {
"min_age": {
"min": { #关键词
"field": "age"
}
}
}
}
注意我们将size设置成0,这样我们就可以只看到聚合结果了,而不会显示命中的结果
返回数值字段的最大值/平均值/求和只需要将关键词min替换对应的为max/avg/sum即可。
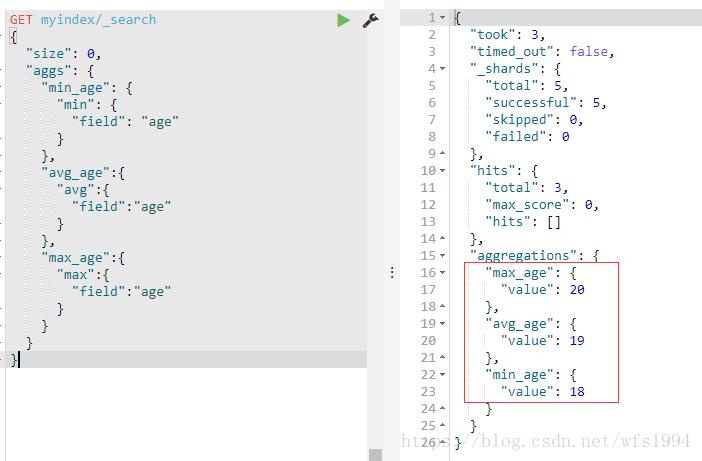
一次返回多个聚合结果 (并列关系,不是子聚合)
GET myindex/_search
{
"size": 0,
"aggs": {
"min_age": {
"min": {
"field": "age"
}
},
"avg_age":{
"avg":{
"field":"age"
}
},
"max_age":{
"max":{
"field":"age"
}
}
}
}
cardinality
cardinality:意为集合的势,或者基数,是指不同数值的个数,类似SQL中的distinct count概念。
例如查找性别(M|F)的基数,返回的结果为2
GET /bank/account/_search
{
"size":0,
"aggs":{
"count_of_genders":{
"cardinality": {
"field": "gender.keyword"
}
}
}
}
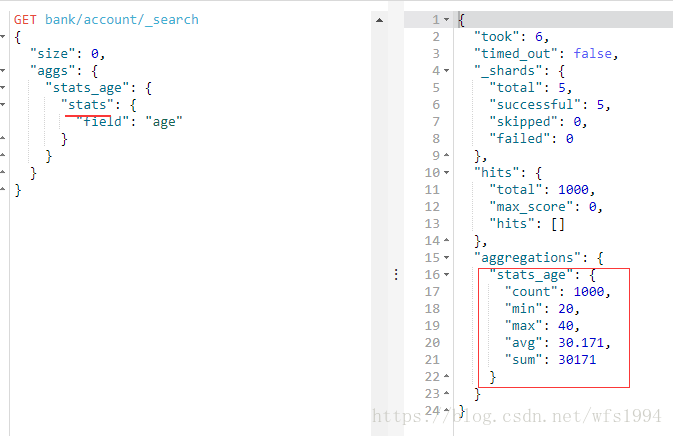
stats,extended stats
stats:返回一系列数值类型的统计值,包含min、max、avg、sum和count
GET bank/account/_search
{
"size": 0,
"aggs": {
"stats_age": {
"stats": {
"field": "age"
}
}
}
}
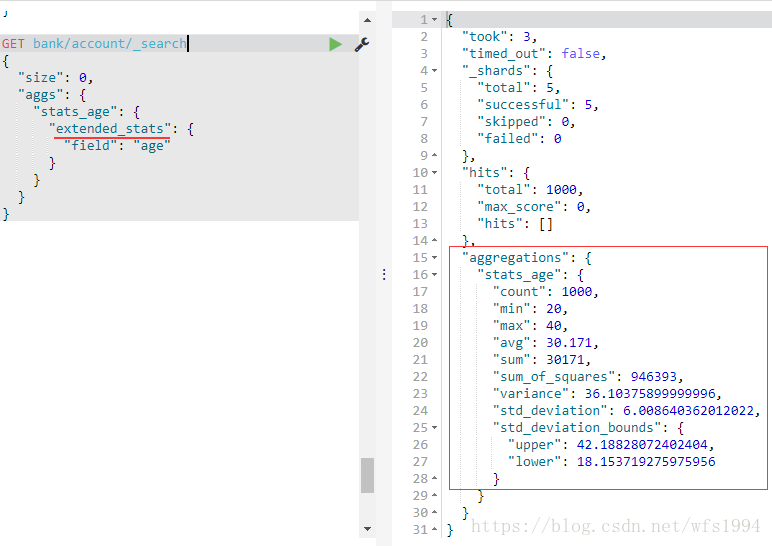
extended stats:对stats的扩展,包含了更多的统计数据,比如方差、标准差等
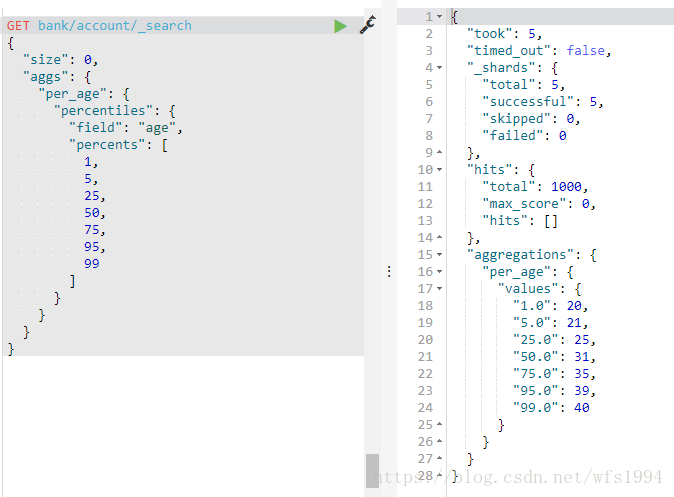
Percentile,Percentile Rank
Percentile: 百分位数统计
GET bank/account/_search
{
"size": 0,
"aggs": {
"per_age": {
"percentiles": {
"field": "age",
"percents": [
1,
5,
25,
50,
75,
95,
99
]
}
}
}
}
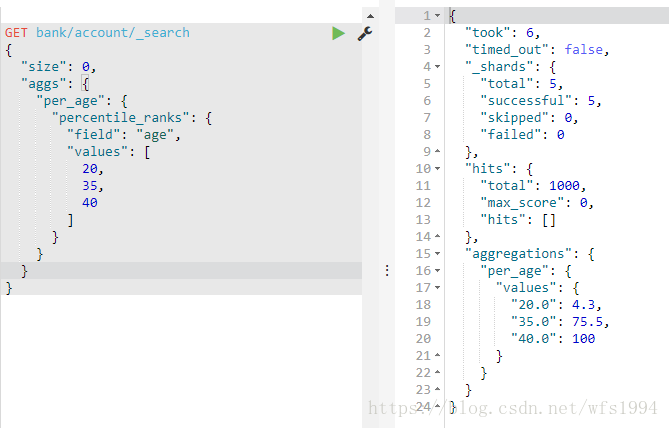
Percentile Rank: 百分位数统计
GET bank/account/_search
{
"size": 0,
"aggs": {
"per_age": {
"percentile_ranks": {
"field": "age",
"values": [
20,
35,
40
]
}
}
}
}
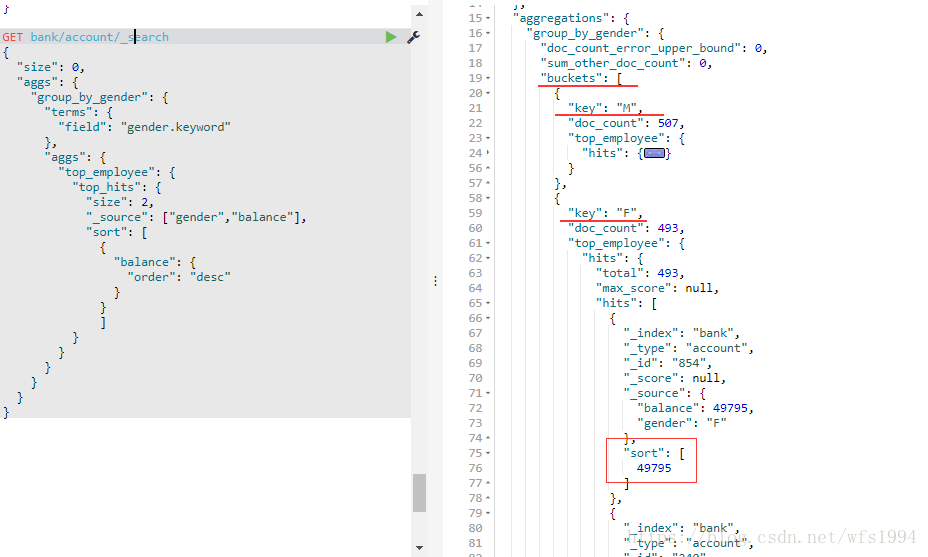
Top Hits
Top Hits: 一般用于分桶后获取该桶内匹配的顶部文档列表,即详情数据
例如,按照性别进行分组,并对每组中按照balance进行排序(子聚合)
GET bank/account/_search
{
"size": 0,
"aggs": {
"group_by_gender": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"top_employee": {
"top_hits": {
"size": 2,
"_source": ["gender","balance"],
"sort": [
{
"balance": {
"order": "desc"
}
}
]
}
}
}
}
}
}
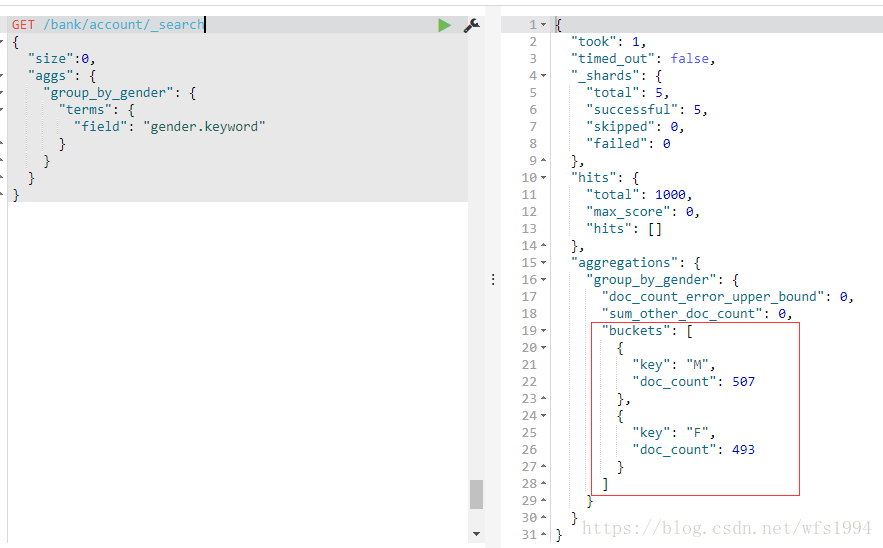
Bucket聚合分析
Bucket:意为桶,即按照一定的规则将文档分配到不同的桶中,达到分类分析的目的

按照Bucket的分桶策略,常见的Bucket聚合分析如下:
TermsRangeDate RangeHistogramDate Histogram
Terms
Terms: 最简单的分桶策略,直接按照term来分桶,如果是text类型,则按照分词后的结果分桶
GET /bank/account/_search
{
"size":0,
"aggs": {
"group_by_gender": {
"terms": {
"field": "gender.keyword"
}
}
}
}
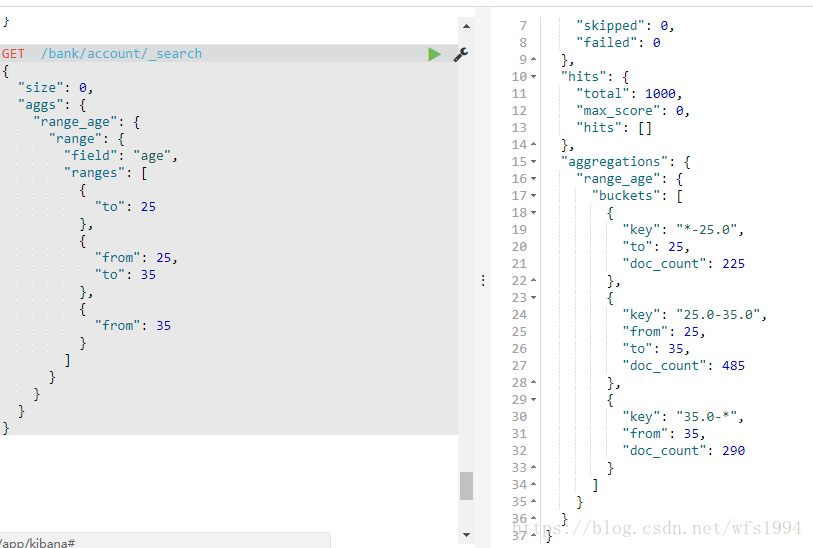
Range,Date Range
Range: 通过制定数值的范围来设定分桶规则
GET /bank/account/_search
{
"size": 0,
"aggs": {
"range_age": {
"range": {
"field": "age",
"ranges": [
{
"to": 25
},
{
"from": 25,
"to": 35
},
{
"from": 35
}
]
}
}
}
}
Date Range: 通过指定日期的范围来设定分桶规则
GET myindex/_search
{
"size": 0,
"aggs": {
"data_range": {
"date_range": {
"field": "",
"format": "MM-yyy",
"ranges": [
{
"from": "now-10d/d",
"to": "now"
}
]
}
}
}
}
Historgram,Date Histogram
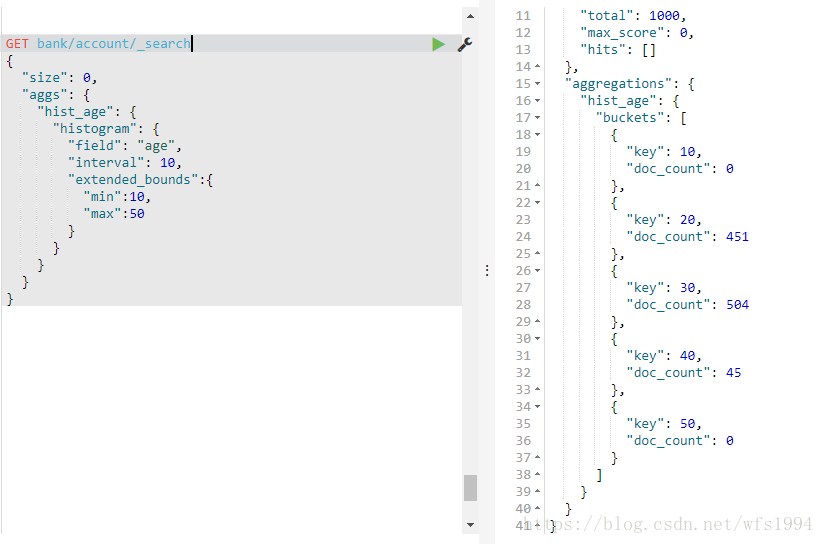
Historgram: 直方图,以固定间隔的策略来分割数据
GET bank/account/_search
{
"size": 0,
"aggs": {
"hist_age": {
"histogram": {
"field": "age",
"interval": 10,
"extended_bounds":{
"min":10,
"max":50
}
}
}
}
} 
Date Histogram: 针对日期的直方图或者柱状图,是时序分析中常用的聚合分析类型
GET myindex/_search
{
"size": 0,
"aggs": {
"by_year": {
"date_histogram": {
"field": "date",
"interval": "month"
, "format": "yyyy-MM-dd"
}
}
}
}
Bucket + Metric聚合分析
Bucket聚合分析允许通过子分析来进一步进行分析,该分析可以是Bucket也可以是Metric,这也使得es的聚合分析能力变得异常强大。
(1)分桶之后在分桶
GET /bank/account/_search
{
"size": 0,
"aggs": {
"group_by_gender": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"range_age": {
"range": {
"field": "age",
"ranges": [
{
"from": 20,
"to": 30
},
{
"from":30,
"to":40
}
]
}
}
}
}
}
}
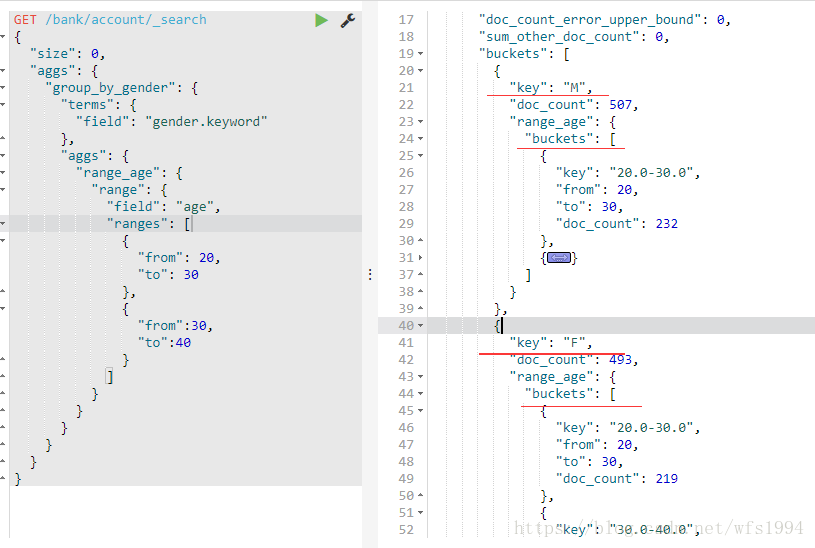
(2)分桶后进行数据分析
GET /bank/account/_search
{
"size":0,
"aggs": {
"group_by_gender": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"stats_age": {
"stats": {
"field": "age"
}
}
}
}
}
}
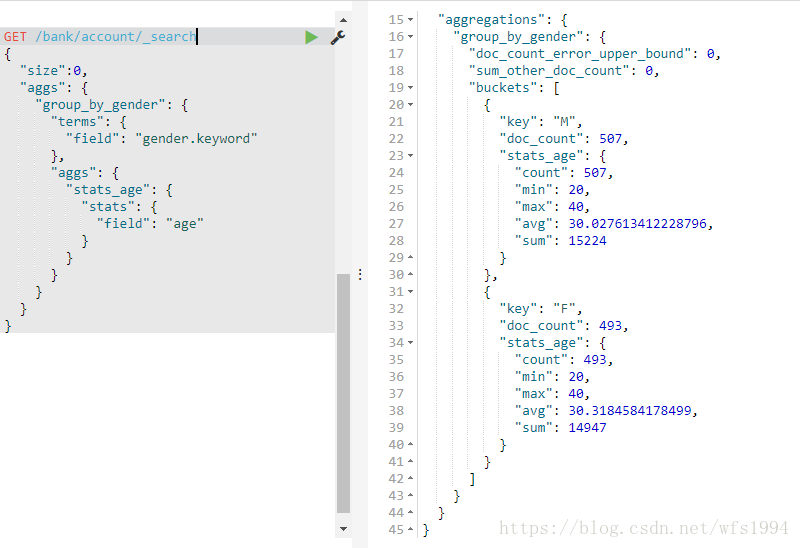
Pipeline 聚合分析
针对聚合分析的结果再次进行聚合分析,而且支持链式调用,可以回答如下问题:订单月平均销售额是多少?
Pipeline的分析结果会输出到原有结果汇总,根据输出位置的不同,分为以下两类:
Parent结果内嵌到现有聚合分析结果中Derivative 导数求导 Moving Average 移动平均 Cumulative Sum 累计求和Sibling结果与现有聚合分析结果同级Max/Min/Avg/Sum Bucket Stats/Extended Stats Bucket Percentiles Bucket
Sibling - Min Bucket
Sibling - Min Bucket : 找出所有bucket中值最小的bucket名称和值
GET /bank/account/_search
{
"size": 0,
"aggs": {
"group_by_stats": {
"terms": {
"field": "state.keyword"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
},
"min_avg_by_balance":{
"min_bucket": {
"buckets_path": "group_by_stats>average_balance"
}
}
}
}
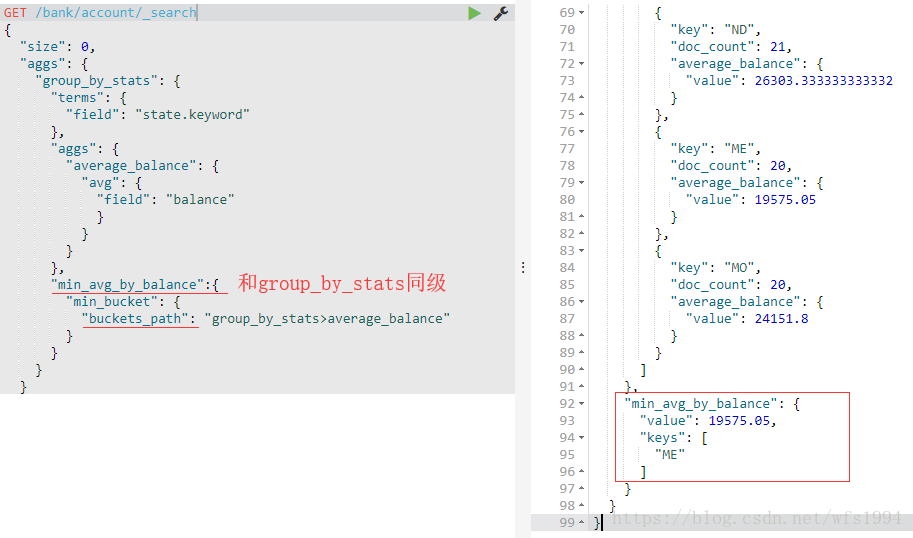
对应的还有:max_bucket/avg_bucket/sum_buctet/stats_bucket等等
Parent - Derivative
Parent - Derivative: 计算Bucket值的导数
“derivative aggregation [derivative_by_average_balance] must have a
histogram or date_histogramas parent”
GET bank/account/_search
{
"size":0,
"aggs": {
"hist_city": {
"histogram": {
"field": "age",
"interval": 5
},
"aggs":{
"avg_balance":{
"avg": {
"field": "balance"
}
},
"derivative_avg_balance":{
"derivative": {
"buckets_path": "avg_balance"
}
}
}
}
}
}
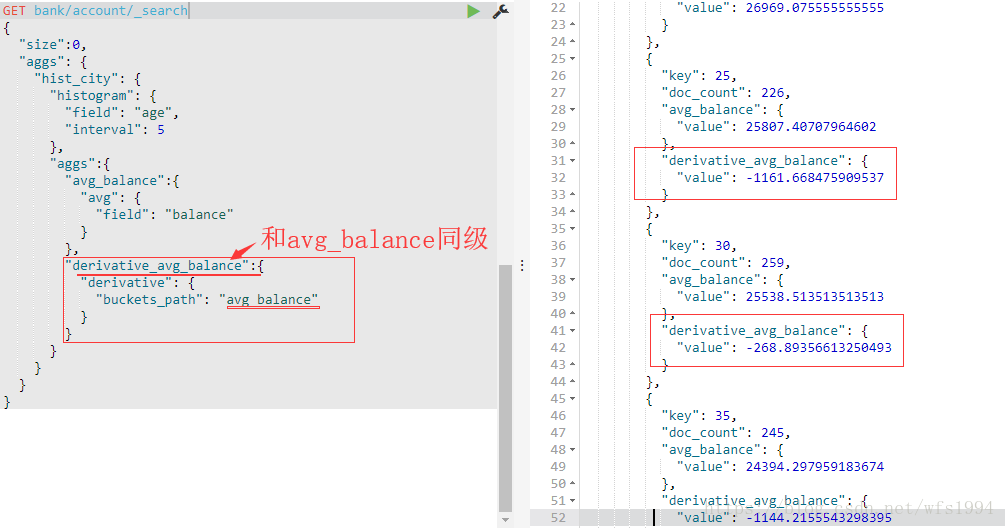
Moving Average移动平均(moving_avg)、Cumulative Sum累计求和(cumulative_sum)的用法同derivative
聚合分析作用范围
es聚合分析默认作业范围是query的结果集,可以通过如下的方式改变其作业范围:
filter: 为某个聚合分析设定过滤条件,从而在不更改整体query语句的情况下修改了作用范围Post_filter:作用于文档过滤,但在聚合分析后生效global:无视query过滤条件,基于全部文档进行分析
聚合分析中的排序
(一)可以使用自带的关键数据进行排序,比如:
_count文档数_key按照key值排序
GET bank/account/_search
{
"size":0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"size": 5,
"order": {
"_count": "desc"
}
}
}
}
}
(二)根据子聚合排序
GET /bank/account/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"size": 10,
"order": {
"avg_balance": "asc"
}
},
"aggs": {
"avg_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
GET /bank/account/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"size": 10,
"order": {
"stats_balance.avg": "asc"
}
},
"aggs": {
"stats_balance": {
"stats": {
"field": "balance"
}
}
}
}
}
}
聚合分析精准度问题
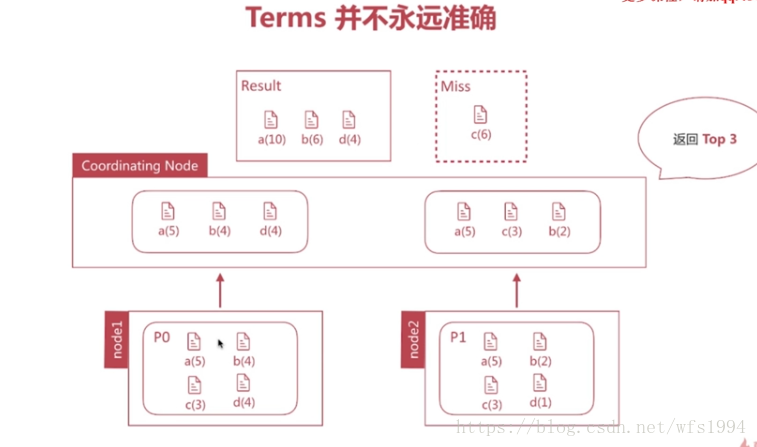
Terms不准确的解决方法:
- 设置
Shard数为1,消除数据分散的问题,但无法承载大数据量 - 合理设置
Shard_Size大小,即每次从Shard上额外多获取数据,以提升准确度
GET bank/account/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"size": 2,
"shard_size": 10
}
}
}
}
Shard_Size大小的设定方法:
terms聚合返回结果有如下两个统计值:
doc_count_error_upper_bound 被遗漏的term可能的最大值
sum_other_doc_count 返回结果bucket的term外其他term的文档总数
设定show_term_doc_count_error可以查看每个bucket误算的最大值:
GET bank/account/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"size": 2,
"show_term_doc_count_error": true
}
}
}
}
返回结果中"doc_count_error_upper_bound": 0 : 0表示计算准确
Shard_Size默认大小如下:
shard_size=(size*1.5)+10通过调整Shard_size的大小降低doc_count_error_upper_bound来提升准确度,增大了整体的计算量,从而降低了响应时间
近似统计算法:
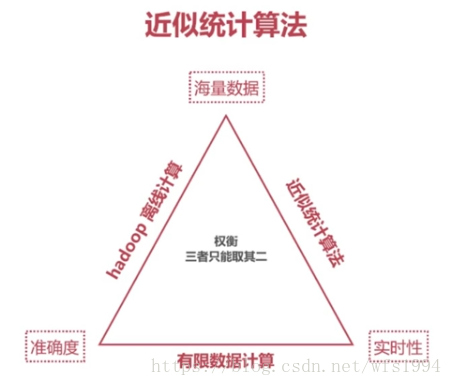
在es聚合分析中,Cardinality和Percentile分析使用的是近似统计算法:
- 结果是近似准确的,但不一定精准
- 可以通过参数的调整使其结果精准,但同时也意味着更多的计算时间和更大的性能消耗
执行聚合示例
聚合提供了分组并统计数据的能力。理解聚合的最简单的方式是将其粗略地等同为SQL的GROUP BY和SQL聚合函数。在Elasticsearch中,你可以在一个响应中同时返回命中的数据和聚合结果。你可以使用简单的API同时运行查询和多个聚合,并以一次返回,这避免了来回的网络通信,这是非常强大和高效的。
首先,本示例按状态对所有帐户进行分组,然后返回按降序(也是默认值)排序的前10个(默认)状态:
curl -H "Content-Type: application/json" -XPOST '192.168.20.60:9200/bank/_search?pretty' -d '
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
}
}
}
}' 在SQL中,上面的聚合在概念上类似于:
SELECT state, COUNT(*) FROM bank GROUP BY state ORDER BY COUNT(*) DESC部分结果显示:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1000,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"group_by_state" : {
"doc_count_error_upper_bound" : 20,
"sum_other_doc_count" : 770,
"buckets" : [
{
"key" : "ID",
"doc_count" : 27
},
{
"key" : "TX",
"doc_count" : 27
},
{
"key" : "AL",
"doc_count" : 25
},
{
"key" : "MD",
"doc_count" : 25
},
{
"key" : "TN",
"doc_count" : 23
}, 我们可以看到AL(abama)有25个账户,TX有27个账户,ID(daho)有27个账户
注意我们将size设置成0,这样我们就可以只看到聚合结果了,而不会显示命中的结果
在先前聚合的基础上,现在这个例子计算了每个州的账户的平均余额(还是按照账户数量倒序排序的前10个州):
curl -H "Content-Type: application/json" -XPOST '192.168.20.60:9200/bank/_search?pretty' -d '
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}'注意,我们把average_balance聚合嵌套在了group_by_state聚合之中。这是所有聚合的一个常用模式。你可以任意的聚合之中嵌套聚合,这样你就可以从你的数据中抽取出想要的概述。
基于前面的聚合,现在让我们按照平均余额进行排序:
curl -H "Content-Type: application/json" -XPOST '192.168.20.60:9200/bank/_search?pretty' -d '
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"order": {
"average_balance": "desc"
}
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}' 下面的例子显示了如何使用年龄段(20-29,30-39,40-49)分组,然后在用性别分组,然后为每一个年龄段的每一个性别计算平均账户余额:
curl -H "Content-Type: application/json" -XPOST '192.168.20.60:9200/bank/_search?pretty' -d '
{
"size": 0,
"aggs": {
"group_by_age": {
"range": {
"field": "age",
"ranges": [
{
"from": 20,
"to": 30
},
{
"from": 30,
"to": 40
},
{
"from": 40,
"to": 50
}
]
},
"aggs": {
"group_by_gender": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
}
}'