目录
《Elasticsearch In Action》学习笔记。
ES本身不支持SQL数据库的join操作,在ES中定义关系的方法有对象类型、嵌套文档、父子关系和反规范化。
一、文档间关系概览
1. 对象类型
允许将一个对象作为文档字段的值,主要用于处理一对一关系。如果用对象类型表示一对多关系,可能出现逻辑上的错误。例如,使用对象类型(object type)表示一个小组多个活动的关系:
{
"name": "Denver technology group"
"events": [
{
"date": "2014-12-22",
"title": "Introduction to Elasticsearch"
},
{
"date": "2014-06-20",
"title": "Introduction to Hadoop"
}
]
}如果希望搜索一个关于Elasticsearch的活动分组,可以在events.title字段里搜索。在系统内部,文档是像下面这样进行索引的:
{
"name": "Denver technology group",
"events.date": ["2014-12-22", "2014-06-20"],
"events.title": ["Introduction to Elasticsearch", "Introduction to Hadoop"]
}假设想过滤2014年12月主办过Hadoop会议的分组,查询可以是这样的:
"bool": {
"must": [
{
"term": {
"events.title": "Hadoop"
}
},
{
"range": {
"events.date": {
"from": "2014-12-01",
"to": "2014-12-31"
}
}
}
]
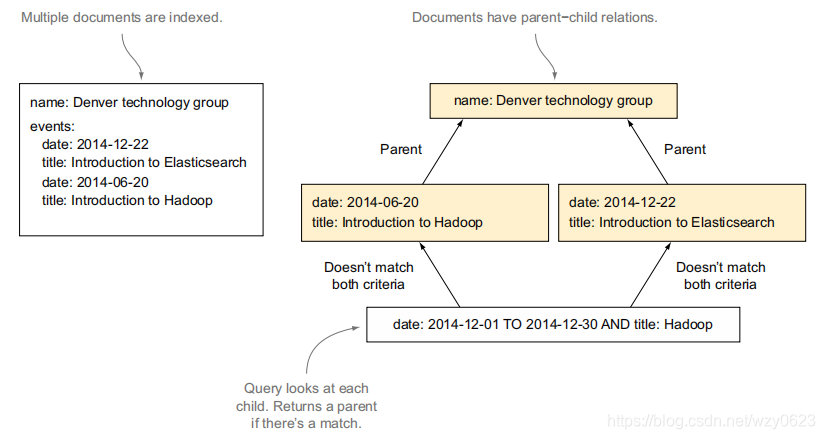
}这将匹配例中的那个文档,但显然错误的,Hadoop活动是在6月而不是12月。造成这种错误的原因是对象类型将所有数据都存储在一篇文档中,ES并不知道内部文档之间的边界,如图1所示。

如果处理的是一对一关系,则不会出现这样的逻辑错误,而且对象类型是最快、最便捷的关系处理方法。ES的关系类型类似Oracle中的嵌套表。
2. 嵌套类型
要避免跨对象匹配的发生,可以使用嵌套类型(nested type),它将活动索引到分隔的Lucene文档。对象与嵌套的区别在于映射,这会促使ES将嵌套的内部对象索引到邻近的位置,但是保持独立的Lucene文档,如图2所示。在搜索时,需要使用nested过滤器和查询,这些会在Lucene文档中搜索。

在某些用例中,像对象和嵌套类型那样,将所有数据存储在同一个ES文档中不见得是明智之举。拿分组和活动的例子来说:如果一个分组所有数据都放在同一篇文档中,那么在创建一项新的活动时,不得不为这个活动重新索引整篇文档。这可能会降低性能和并发性,取决于文档有多大,以及操作的频繁程度。
3. 父子关系
通过父子关系,可以使用完全不同的ES文档,并在映射中定义文档间的关系。在索引一个子文档时,可以将它指向其父文档,如图3所示。在搜索时,可以使用has_parent和has_child查询和过滤器处理父子关系。
4. 反规范化
对象、嵌套和父子关系可以用于处理一对一或一对多关系,而反规范化用于处理多对多关系。反规范化(denormalizing)意味着一篇文档将包含所有相关的数据,即使是同样的数据在其它文档中有复本。
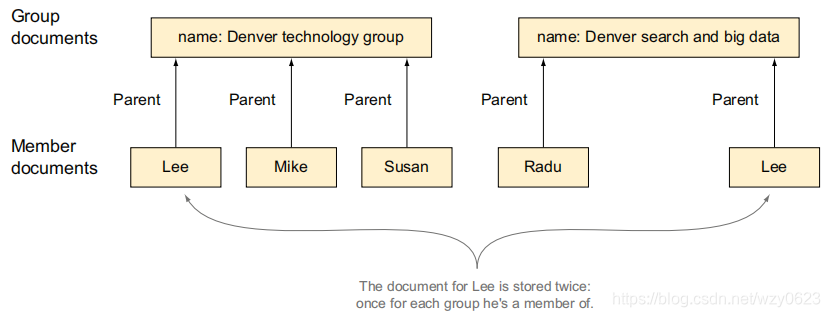
以分组和会员为例,一个分组可以拥有多个会员,一个用户也可以成为多个分组的会员。分组和会员都有它们自己的一组属性。为了表示这种关系,可以让分组成为会员的父辈。对于身为多个分组会员的用户而言,可以反规范化他们的数据:每次表示一个其所属的分组,如图4所示。反规范化实际上是一种典型的以空间(数据冗余)换时间的处理方式。
二、将对象最为字段值
通过对象,ES在内部将层级结构进行了扁平化,使用每个内部字段的全路径,将其放入Lucene内的独立字段。整个流程如图5所示。

1. 映射和索引对象
默认情况下,内部对象的映射是自动识别的。
# 自动创建索引
curl -XPOST '172.16.1.127:9200/event-object/_doc/1?pretty' -H 'Content-Type: application/json' -d'
{
"title": "Introduction to objects",
"location":
{
"name": "Elasticsearch in Action book",
"address": "chapter 8"
}
}'
# 查看索引映射
curl '172.16.1.127:9200/event-object/_mapping?pretty'结果返回:
{
"event-object" : {
"mappings" : {
"_doc" : {
"properties" : {
"location" : {
"properties" : { # 内部对象及其属性的映射是自动识别的
"address" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
}如果有多个这样的对象所构成的数组,单个内部对象的映射同样奏效。例如,如果索引了下面的文档,映射将会保持不变。
curl -XPOST '172.16.1.127:9200/event-object/_doc/2?pretty' -H 'Content-Type: application/json' -d'
{
"title": "Introduction to objects",
"location": [
{
"name": "Elasticsearch in Action book",
"address": "chapter 8"
},
{
"name": "Elasticsearch Guide",
"address": "elasticsearch/reference/current/mapping-object-type.html"
} ]
}'2. 搜索对象
默认情况下,需要设置所查找的字段路径,来引用内部对象。下面的代码指定location_event.name的全路径将其作为搜索的字段,从而搜索在办公室举办的活动。
EVENT_PATH="172.16.1.127:9200/get-together/"
curl "$EVENT_PATH/_search?q=location_event.name:office&pretty"下面的terms聚合返回了location.name字段中最为常用的单词。
curl "172.16.1.127:9200/get-together/_search?pretty" -H 'Content-Type: application/json' -d'
{
"aggs": {
"location_cloud": {
"terms": {
"field": "location.name"
}
}
}
}'再次强调,对象擅于处理一对一关系,而对于一对多关系的查询,可能出现逻辑错误。
三、嵌套类型
1. 映射并索引嵌套文档
嵌套映射和对象映射看上去差不多,不过期type不是object,而必须是nested。
# 定义索引映射
curl -XPUT "172.16.1.127:9200/group-nested?pretty" -H 'Content-Type: application/json' -d'
{
"mappings": {
"_doc": {
"properties": {
"name": {
"type": "text"
},
"members": {
"type": "nested", # 这里告诉ES将会员对象索引到同一个分块中的不同文档中
"properties": {
"first_name": {
"type": "text"
},
"last_name": {
"type": "text"
}
}
}
}
}
}
}'
# 增加一篇文档
curl -XPUT "172.16.1.127:9200/group-nested/_doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"name": "Elasticsearch News", # 这个属性将存入主文档
"members": [
{
"first_name": "Lee", # 这些对象存入自己的文档中,共同组成根文档中的一个分块
"last_name": "Hinman"
},
{
"first_name": "Radu",
"last_name": "Gheorghe"
}
]
}'与对象不同,嵌套查询和过滤器可以在文档的边界之内搜索。例如,可以搜索名为“Lee”且姓为“Hinman”的分组会员。缺省时,嵌套的查询不会进行跨多个对象的匹配,因此避免了名为“Lee”而姓为“Gheorghe”这样的意外匹配。
2. 搜索和聚合嵌套文档
使用nested在嵌套文档上运行搜索和聚合,使ES连接在同一个分块中的多个Lucene文档,并将连接后的结果数据看作普通的ES文档。
(1)Nested查询和过滤器
运行nested查询或过滤器时,需要指定path参数,告诉ES这些嵌套对象位于哪里的Lucene分块中。除夕之外,nested查询或者过滤器将会分别封装一个常规的查询或过滤器。下面的代码搜索名为“Lee”、姓为“Gheorghe”的会员。查询不会返回匹配的文档,因为没有会员的名字是Lee Gheorghe。
curl '172.16.1.127:9200/group-nested/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query": {
"nested": {
"path": "members", # 在members中查找嵌套的文档
"query": { # 通常在同一篇文档中的对象上运行查询
"bool": {
"must": [
{ "term": { "members.first_name": "lee" }},
{ "term": { "members.last_name": "gheorghe" }}
]
}
}
}
}
}'(2)在多个嵌套层级上搜索
ES支持多级嵌套。下面的代码创建两级嵌套的索引:会员(members)和他们的评论(comments)。
curl -XPUT "172.16.1.127:9200/group-multinested?pretty" -H 'Content-Type: application/json' -d'
{
"mappings": {
"_doc": {
"properties": {
"name": {
"type": "text"
},
"members": {
"type": "nested",
"properties": {
"first_name": {
"type": "text"
},
"last_name": {
"type": "text"
},
"comments": {
"type": "nested",
"include_in_parent": true,
"properties": {
"date": {
"type": "date",
"format": "dateOptionalTime"
},
"comment": {
"type": "text"
}
}
}
}
}
}
}
}
}'添加一个嵌套文档:
curl -XPUT "172.16.1.127:9200/group-multinested/_doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"name": "Elasticsearch News",
"members": {
"first_name": "Radu",
"last_name": "Gheorghe",
"comments": { # 多个会员对象嵌套于分组中,而多个评论对象又嵌套在会员对象中
"date": "2013-12-22",
"comment": "hello world"
}
}
}'为了在内嵌的评论文档中搜索,需要指定members.comments的路径:
curl '172.16.1.127:9200/group-multinested/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query": {
"nested": {
"path": "members.comments", # 查找位于members之中的comments字段
"query": {
"term": {
"members.comments.comment": "hello" # 查询仍然提供了字段的全部路径用于查找
}
}
}
}
}'(3)整合嵌套对象的得分
一个nested查询会计算得分。例如,根据查询条件的匹配程度,每个内部会员文档会得到自己的得分。但是来自应用的查询是为了查找分组文档,所以ES需要为整个分组文档给出一个得分。在这点上一共有4中选项,通过score_mode设置。
- avg:这是默认选项,系统获取所有匹配的内部文档之分数,并返回其平均分。
- total:系统获取所有匹配的内部文档之分数,将其求和并返回。
- max:返回匹配的内部文档之最大得分。
- none:考虑总文档得分的计算时,不保留、不统计嵌套文档的得分。
(4)获知哪些内部文档匹配上了
可以在嵌套查询或过滤器中添加一个inner_hits对象,来展示匹配上的嵌套文档。
curl '172.16.1.127:9200/group-nested/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query": {
"nested": {
"path": "members",
"query": {
"term": {
"members.first_name": "lee"
}
},
"inner_hits": {
"from": 0,
"size": 1
}
}
}
}'结果返回:
...
"inner_hits" : {
"members" : {
"hits" : {
"total" : 1,
"max_score" : 0.6931472,
"hits" : [
{
"_index" : "group-nested",
"_type" : "_doc",
"_id" : "1",
"_nested" : {
"field" : "members",
"offset" : 0
},
"_score" : 0.6931472,
"_source" : {
"first_name" : "Lee",
"last_name" : "Hinman"
}
}
]
}
}
}要识别子文档,可以查看_nested对象。其中field字段是嵌套对象的路径,而offset显示了嵌套文档在数组中的位置。上例中,Lee是查询结果中的第一个member。
(5)嵌套和逆向嵌套聚合
为了在嵌套类型的对象上进行聚合,需要使用nested聚合。这是一个单桶聚合,在其中可以指定包含所需字段的嵌套对象之路径。如图6所示,nested聚合促使ES进行了必要的连接,以确保其它聚合在指定的路径上能正常运行。

例如,为了获得参与分组最多的活跃用户,通常会在会员名字字段上运行一个terms聚合。如果这个name字段存储在嵌套类型的members对象中,那么需要将terms聚合封装在nested聚合中,并将聚合的路径path设置为会员members:
curl '172.16.1.127:9200/get-together/_search?pretty' -H 'Content-Type: application/json' -d'
{
"aggs": {
"members": {
"nested": {
"path": "members"
},
"aggs": {
"frequent_members": {
"terms": {
"field": "members.name"
}
}
}
}
}
}'有些情况下,需要反向访问父辈或者根文档。例如,希望针对活跃会员,展示他们参加最多的分组之tags。为了实现这一点,使用reverse_nested聚合,它会告诉ES在嵌套层级中向上返回查找:
curl -X PUT "172.16.1.127:9200/get-together/_mapping/_doc?pretty" -H 'Content-Type: application/json' -d'
{
"properties": {
"tags": {
"type": "text",
"fielddata": true
}
}
}'
curl '172.16.1.127:9200/get-together/_search?pretty' -H 'Content-Type: application/json' -d'
{
"aggs": {
"members": {
"nested": {
"path": "members"
},
"aggs": {
"frequent_members": {
"terms": {
"field": "member.name"
},
"aggs": {
"back_to_group": {
"reverse_nested": {},
"aggs": {
"tags_per_member": {
"terms": {
"field": "tags"
}
}
}
}
}
}
}
}
}
}'Nested和reverse_nested聚合可以快速告诉ES,在哪些Lucene文档中查找下一项聚合的字段。
四、父子关系
在嵌套的文档中,实际情况是所有内部的对象集中在同一个分块中的Lucene文档,这对于对象便捷地连接根文档而言,是非常有好处的。父子文档则是完全不同的ES文档,所以只能分别搜索它们,效率更低。
对于文档的索引、更新和删除而言,父子的方式就显得出类拔萃了。这是因为父辈和子辈文档都是独立的ES文档,各自管理。举例来说,如果一个分组有很多活动,要增加一个新活动,那么就是增加一篇新的活动文档。如果使用嵌套类型的方式,ES不得不重新索引分组文档,来囊括新的活动和全部已有活动,这个过程就会更慢。
1. 子文档的索引、更新和删除
(1)映射
在示例索引get-together的映射中定义了一对父子关系属性如下;
...
"relationship_type": { # 属性名称
"type": "join", # 类型为join
"relations" : { # 父子关系中group为父名称、event为子名称
"group": "event"
}
},
...(2)索引和检索
索引子文档时,需要在URI中放置routing值作为参数。routing字段向ES提供了散列的ID,即路由值,这使得ES将父子文档路由到相同的分片,搜索的时候能从中获益。ES会自动使用这个路由值来查询父辈的分片并获得其子辈,或者是查询子辈的分片来获得其父辈。
curl -X PUT "172.16.1.127:9200/get-together/_doc/1103?routing=2&refresh&pretty" -H 'Content-Type: application/json' -d'
{
"host": "Radu",
"title": "Yet another Elasticsearch intro in Denver",
"relationship_type": {
"name": "event", # 表示ID为1103的文档是子文档event
"parent": "2" # 其对应的父文档ID为2
}
}'routing参数是强制的,如果不加该参数,报错如下:
{
"error" : {
"root_cause" : [
{
"type" : "mapper_parsing_exception",
"reason" : "failed to parse"
}
],
"type" : "mapper_parsing_exception",
"reason" : "failed to parse",
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "[routing] is missing for join field [relationship_type]"
}
},
"status" : 400
}当索引子文档时,其父辈文档可能已经被索引,也可能尚未索引。这类似于关系数据库中的主子表之间没有强制的外键约束。在上例中,当索引event子文档1103时,其对应的group父文档2可以并不存在。
_routing字段是被存储的,因此可以检索其内容。同时,这个字段也是被索引的,这样可以通过条件来搜索其值。为了检索一篇活动文档,这里运行了一个普通的索引请求:
curl '172.16.1.127:9200/get-together/_doc/1103?routing=2&pretty'结果返回:
{
"_index" : "get-together",
"_type" : "_doc",
"_id" : "1103",
"_version" : 1,
"_routing" : "2",
"found" : true,
"_source" : {
"host" : "Radu",
"title" : "Yet another Elasticsearch intro in Denver",
"relationship_type" : {
"name" : "event",
"parent" : "2"
}
}
}如果请求中不加routing=2,查询会路由到1103的散列分片上去,而不是2的散列分片,最终导致查询不到相应的文档。再者,子文档ID,如1103在索引中并不唯一,只有parent ID和_id的组合才是唯一的。
(3)更新与删除
类似地,更新与删除子文档同样需要指定routing参数。
curl -X POST '172.16.1.127:9200/get-together/_doc/1103/_update?routing=2&pretty' -H 'Content-Type: application/json' -d '
{
"doc": {
"description": "Gives an overview of Elasticsearch"
}
}'
curl -X DELETE '172.16.1.127:9200/get-together/_doc/1103?routing=2&pretty'通过查询来进行的删除,不需要指定routing参数:
curl -X POST "172.16.1.127:9200/get-together/_delete_by_query?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"query_string": {
"fields": ["host"],
"query": "radu"
}
}
}'2. 在父文档和子文档中搜索
(1)has_child查询和过滤器
使用子辈的条件来搜索父辈的时候,如搜索Elasticsearch活动的分组,可以使用has_child查询或过滤器。
curl -X GET "172.16.1.127:9200/get-together/_doc/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"has_child" : {
"type" : "event",
"query" : {
"term" : {
"title" : "elasticsearch"
}
}
}
}
}'has_child查询和这个过滤器的运行方式差不多,不过它可以通过聚合子文档的得分,对每个父辈进行评分。可以将score_mode设置为max、sum、avg或none,和嵌套查询是一样的。例如,如下查询在返回分组时,按照举办的Elasticsearch活动之最高相关性排序:
curl -X GET "172.16.1.127:9200/get-together/_doc/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"has_child": {
"type": "event",
"score_mode": "max",
"query": {
"term": {
"title": "elasticsearch"
}
}
}
}
}'(2)在结果中获得子文档
默认情况下,has_child查询只会返回父文档,不会返回子文档。通过添加inner_hits选项可以获得子文档:
curl -X GET "172.16.1.127:9200/get-together/_doc/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"has_child": {
"type": "event",
"score_mode": "max",
"query": {
"term": {
"title": "elasticsearch"
}
},
"inner_hits": {}
}
}
}'(3)has_parent查询和过滤器
使用父辈的条件来搜索子辈的时候使用has_parent查询或过滤器。下面的代码展示了如何搜索关于Elasticsearch的活动,而且它们只在Denver举办。
curl -X GET "172.16.1.127:9200/get-together/_doc/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [ # 主查询包含两个必须满足的子查询
{
"term": {
"title": "elasticsearch" # 这个查询运行在活动上,确保标题中包含“elasticsearch”关键字
}
},
{
"has_parent": {
"parent_type": "group",
"query": {
"term": {
"location_group": "denver" # 这个查询运行在每个活动的分组上,确保活动在Denver举办
}
}
}
}
]
}
}
}'(4)子辈聚合
ES允许在子文档上嵌入聚合。假设已经通过词条聚合,获得了get-together分组中最流行的标签。对于这些标签,需要知道每个标签的分组中,谁是最积极的活动参与者。下面代码在标签的terms聚合下嵌套了children聚合,以此来发现这类会员。在children聚合中,又嵌套了另一个terms聚合来统计每个标签所对应的活动参与者。
curl "172.16.1.127:9200/get-together/_search?pretty" -H 'Content-Type: application/json' -d'
{
"aggs": {
"top-tags": { # 标签聚合为每个标签创建了一个分组的桶
"terms": {
"field": "tags.verbatim"
},
"aggs": {
"to-events": { # to-events为每个标签中的分组创建了一个活动的桶
"children": {
"type": "event"
},
"aggs": {
"frequent-attendees": { # frequent-attendees 统计了每个参与者的参与活动数
"terms": {
"field": "attendees"
}
}
}
}
}
}
}
}'五、反规范化
1. 反规范化使用案例
反规范化利用数据冗余,以空间换时间,查询时没有必要连接不同的文档。在分布式系统中这一点尤为重要,因为跨过网络来连接多个文档引入了很大的延时。ES中的反规范化主要用于处理多对多关系。与嵌套、父子的一对多实现不同,ES无法承诺让多对多关系保持在一个节点内。如图7所示,一个单独的关系可能会延伸到整个数据集。这种操作可能会非常昂贵,跨网络的连接无法避免。

图8展示了反规范化后,分组与会员之间的多对多关系。它将多对多关系的一端反规范化为许多一对多关系。

2. 索引、更新和删除反规范化的数据
(1)反规范化哪个方向
是将会员复制为分组的子文档呢。还是反过来将分组复制为会员的子文档?必须要理解数据是如何索引、更新、删除和查询的,才能做出选择。被反规范化的部分(也就是子文档)从各方面看都是难以管理的。
- 会多次索引这些文档,某文档在父辈中每出现一次,就会被索引一次。
- 更新时,必须更新这篇文档的所有实例。
- 删除时,必须删除所有实例。
- 当单独查询这些子文档时,将获得多个同样的内容,所以需要在应用端移除重复项。
基于这些假设,看上去让会员成为分组的子文档更合理一些。会员文档的规模更小,变动没那么频繁,查询频率也不像分组活动那么高。因此,管理复制后的会员文档要容易一些。同理也可应用于SQL数据库的反规范化。
(2)如何表示一对多关系
是选择父子关系还是嵌套文档呢?这里,最好按照分组和会员一起搜索并获取的频率来选择。嵌套查询比has_parent或has_child查询性能更佳。但如果会员更新频繁,父子结构性能更好,因为它们可以各自单独更新。
对于本例,假设一并搜索并获取分组和会员是很罕见的行为,而会员经常会加入或者退出分组,因此选择父子关系。
(3)索引
下面代码首先定义了一个包含分组-会员父子关系的新索引,然后添加了两个父文档,并在两个分组中分别添加了同一个子文档。
curl -X PUT "172.16.1.127:9200/my_index?pretty" -H 'Content-Type: application/json' -d'
{
"mappings": {
"_doc": {
"properties": {
"my_join_field": {
"type": "join",
"relations": {
"group": "member"
}
}
}
}
}
}'
curl -X PUT "172.16.1.127:9200/my_index/_doc/1?refresh&pretty" -H 'Content-Type: application/json' -d'
{
"my_join_field": {
"name": "group"
}
}'
curl -X PUT "172.16.1.127:9200/my_index/_doc/2?refresh&pretty" -H 'Content-Type: application/json' -d'
{
"my_join_field": {
"name": "group"
}
}'
curl -X PUT "172.16.1.127:9200/my_index/_doc/3?routing=1&refresh&pretty" -H 'Content-Type: application/json' -d'
{
"first_name": "Matthew",
"last_name": "Hinman",
"my_join_field": {
"name": "member",
"parent": "1"
}
}'
curl -X PUT "172.16.1.127:9200/my_index/_doc/3?routing=2&refresh&pretty" -H 'Content-Type: application/json' -d'
{
"first_name": "Matthew",
"last_name": "Hinman",
"my_join_field": {
"name": "member",
"parent": "2"
}
}'(4)更新
下面代码将搜索_id为3的全部文档,并将其更名为Lee。为同一会员使用同样的_id,对于会员所属的分组每组使用一次。这样通过会员的ID,快速并可靠地检索某位会员的全部实例。
curl '172.16.1.127:9200/my_index/_doc/_search?pretty' -H 'Content-Type: application/json' -d'
{
"_source": [
"my_join_field.parent" # 只需要每篇文档的parent字段,就能知道如何进行更新了
],
"query": {
"bool": {
"filter": {
"term": {
"_id": 3 # 搜索拥有同样ID的所有会员,这将返回此人的全部复制
}
}
}
}
}'
curl -X POST "172.16.1.127:9200/my_index/_doc/3/_update?routing=1&pretty" -H 'Content-Type: application/json' -d'
{
"doc": {
"first_name": "Lee"
}
}'
curl -X POST "172.16.1.127:9200/my_index/_doc/3/_update?routing=2&pretty" -H 'Content-Type: application/json' -d'
{
"doc": {
"first_name": "Lee"
}
}'(5)删除
curl -X DELETE '172.16.1.127:9200/my_index/_doc/3?routing=1&pretty'
curl -X DELETE '172.16.1.127:9200/my_index/_doc/3?routing=2&pretty'3. 查询反规范化的数据
下面的代码首先索引两个会员,然后在搜索的时候,将同时获得两者。
curl -X PUT "172.16.1.127:9200/my_index/_doc/4?routing=1&refresh&pretty" -H 'Content-Type: application/json' -d'
{
"first_name": "Radu",
"last_name": "Gheorghe",
"my_join_field": {
"name": "member",
"parent": "1"
}
}'
curl -X PUT "172.16.1.127:9200/my_index/_doc/4?routing=2&refresh&pretty" -H 'Content-Type: application/json' -d'
{
"first_name": "Radu",
"last_name": "Gheorghe",
"my_join_field": {
"name": "member",
"parent": "2"
}
}'
curl -X POST "172.16.1.127:9200/my_index/_refresh?pretty"
curl '172.16.1.127:9200/my_index/_doc/_search?pretty' -H 'Content-Type: application/json' -d'
{
"query": {
"term": {
"first_name": "radu"
}
}
}'对于多数索引和聚合,一种变通的方式是在独立的索引中维护所有会员的副本。