版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/kukubao207/article/details/88643810
一、概述
在本篇博客中,我将介绍数据索引的原理、实现。
InnoDB支持三种索引
- B+树索引
- 哈希索引
- 全文索引
B+树索引并不能直接找到给定键值的具体行,而是找到改行所在的数据页,再把该页加载到内存中,通过Page Directory(槽是按主键顺序存放的)进行二分查找得到的。
二、B+树索引
2.1 聚集索引(clustered index)
聚集索引特点
- 每张表只有一个聚集索引
- 聚集索引是一颗B+树
- 主键组织
- 非叶节点的索引页仅存放指向数据页的偏移量
- 叶子节点存放数据页
- 叶子节点由双向链表链接(逻辑连续而非物理连续)
聚集索引优点
- 主键的排序查找很快(因为本就是按主键顺序存放的)
- 主键的范围查找很快(通过上层中间节点可以得到页的范围)
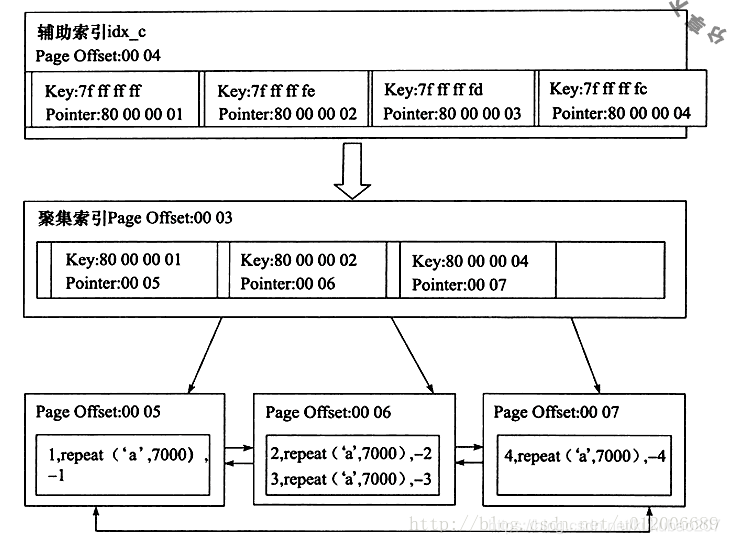
2.2 非聚集索引(secondary index)
非聚集索引特点
- 每张表可以有多个非聚集索引
- 一个非聚集索引对应一颗B+树
- 非主键组织
- 叶子节点存放的是相应行数据在聚集索引中的主键,查找时再根据主键查聚集索引
2.3 Cardinality值
该值表示某个表的字段是否具有高选择性,用来看是否应该创建索引。
比如性别这种,是低选择性的,取值范围只有2个,而记录有成千上万条,为性别创建索引是没有必要的。相反,如果取值范围很大,Cardinality很高,那么创建B+树索引就有必要了。
2.4 其他索引
联合索引:由多列组成的索引。
优点:
- 对于多条件查询可以用索引。
假设我们设置了(a,b)这个联合索引
select * from table where a=xxx and b=xxx,是可以用(a,b)这个联合索引的
select * from table where a=xxx 也可以用(a,b)这个联合索引
select * from table where b=xxx 是不能用这个联合索引的 - 已经对第二个键进行了排序
假设我们设置了(userid,buy_time)这个联合索引
select * from table where userid=‘xxx’ order by buy_time desc;
就可以用这个联合索引,先找到userid为xxx的记录,并且不需要对buy_time进行排序,减少了一次filesort。
覆盖索引:
指从辅助索引中就能获取到需要的记录,而不需要查找聚集索引中的记录。
优点:
- 辅助索引不包括一条记录的整行信息,所以数据量较聚集索引要少,可以减少大量io操作。
- 对于统计语句可以使用覆盖索引(select count(*) from table)
不使用索引的情况
如果范围查询的范围超过整个表的百分之20,那么优化器不会选择使用索引,因为虽然索引中数据是顺序存放的,但是通过主键再去查找聚集索引B+树的时候,查找的数据就是无序的了,这样磁盘IO就从顺序读变成了离散读,效率太低。
2.5 Multi-Range Read优化
为了减少磁盘的随机访问,转为顺序访问的一系列策略。
2.6 ICP优化
将WHERE的部分过滤操作放在了存储引擎层,优化部分查询效率
2.7 哈希算法
InnoDB用了哈希算法对字典进行查找,冲突用拉链法,哈希函数用除法散列法。
自适应哈希索引:
对于字典查找非常迅速,比如select * from table where a=‘xxxx’
对于范围查询是不能用自适应哈希索引的。
2.8 全文检索
倒排索引