转载地址:https://mp.weixin.qq.com/s/HNnzAgUtBoDhhJpsA0fjKQ
世界上只两件东西能震撼人们的心灵:一件是我们心中崇高的道德标准;另一件是我们头顶上灿烂的星空 ——[康德]
大家好,今天笔者为大家分享一些MySQL相关的知识,,希望这篇文章能给大家在工作上带来帮助。
在面试的时候,面试官常会问一些数据库优化的问题。比如:如何加快查询速度。通常一般都是这样回答的
-
加索引
-
修改sql,减少不必要的字段
-
limit
-
分库分表
-
等等
回答的很肤浅![]() 。既然索引能加快查询速度,那好,下面我们就聊聊MySQL InnoDB存储引擎下的B+索引。
。既然索引能加快查询速度,那好,下面我们就聊聊MySQL InnoDB存储引擎下的B+索引。
在MySQL的InnoDB引擎中,为了提高查询速度,可以在字段上添加索引,索引就像一本书的目录,通过目录来定位书中的内容在哪一页。
InnoDB支持的索引有如下几种:
-
B+树索引
-
全文索引
-
哈希索引
笔者这篇文章已经提到过,InnoDB的哈希索引是自适应的,用户无法对其进行干预,在此不再赘述,本文重点介绍B+树索引。
《MySQL InnoDB存储引擎体系架构 —— 内存管理》
https://blog.csdn.net/nuoWei_SenLin/article/details/83034832

01数据结构-B+树
相信大家在大学的数据结构的课程中都学过二分查找、二叉树和平衡二叉树。在一组有序的数据中,利用二分查找可以在log2N的复杂度中快速检索数据,平衡二叉树是在二叉查找树的基础上演变而来,解决了二叉查找树在极端情况下转化为单链表的问题。而B+树呢?让我们来看B+树的结构
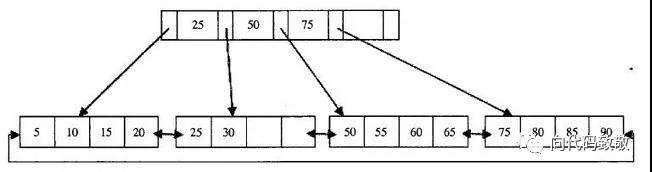
在B+树中,数据都是按照从下到大的顺序存放在叶子节点中,由上图的B+树可得出,这颗B+树的高度为2,每页可存储4条数据,扇出为5,第一层是索引页,第二层是数据页。数据库B+树索引的本质就是B+树在数据库中的实现,并且B+树的高度一般限制在2-4层,磁盘的IO操作只需要2-4次,所以在索引上查找数据,速度很快。
02B+树索引
a.聚集索引
在InnoDB引擎中,都有一个聚集索引,一般是primary key,若用户没有显示指定primary key,InnoDB会默认选择表的第一个not null的unique索引为主键,若没有,则会自动创建一个6字节大小的_rowid作为主键。
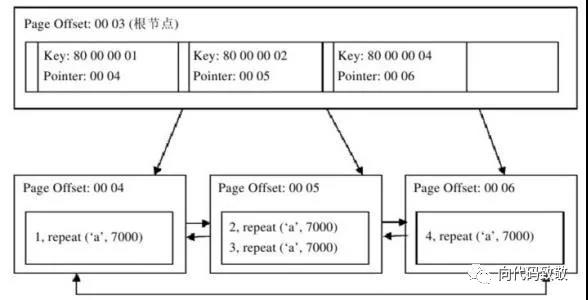
上图是一张聚集索引的示意图,由上图,我们可以看到,该树分为两层,同样第一层是索引页,第二层是数据页,实实在在存放数据的地方。我们还可以得出,索引页存放的并不是数据而是指向真实数据的一个偏移量,而真实数据存放在第二层的数据页,所以如果一条SQL语句命中索引,只是命中了索引页的数据,然后通过索引页找到真实数据所在的页。
思考:聚集索引的存储在物理上不是连续的,在逻辑上却是连续的,这是因为页与页是通过双向链表维护的,而每页中行记录也是通过双向链表维护。为什么要双向链表??
这是因为方便范围查询和排序,如过找到某个索引所在数据页的偏移量,直接遍历这个链表或者逆序遍历这个链表,便可以方便的进行范围查询和逆序排序。比如
select * from table where id>10 and id<1000;
b.辅助索引
InnoDB的另一种索引,辅助索引,也叫二级索引或非聚集索引。对于辅助索引,叶子并不包含行记录的全部数据,叶子节点除了包含键值外,还包含了一个被称作“书签”的东西,该书签用来告诉InnoDB到哪里可以找到所需的行的数据,所以书签实际存放的是聚集索引,所以如果SQL命中了辅助索引,查询流程分为两步:
1、找到索引页
2、通过索引页找到数据页,该数据页包含聚集索引的的值
3、通过聚集索引找到行记录
所以,辅助索引一般比聚集索引多一次IO。
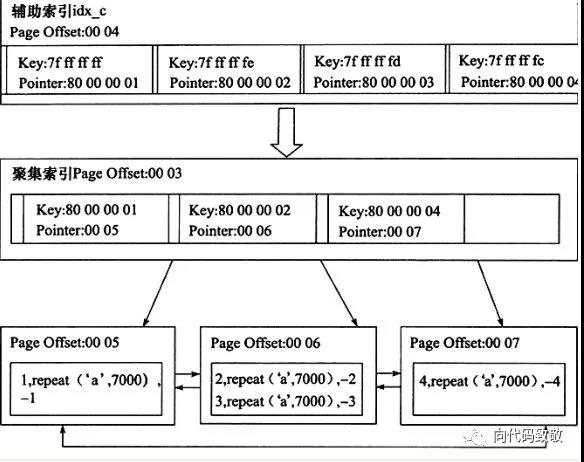
一个很容易被DBA忽略的问题:如果一条SQL语句命中索引,B+树索引不能找到一个给定查询条件的具体行,只能找到被查询数据行所在的页,然后将这个数据读入内存,然后再内存中遍历所有行找到数据。另外,每一页大小为16k,每一页会包含多行,行与行之间是通过双向链表组织的,所以范围查询或者顺序倒序排序查询时,只需遍历链表就可以了。
03 索引的管理
方便测试,我们创建一张表t,并添加索引
create table t( a int primary key, b varchar(500), c int ); alter table t add key idx_b (b(100)); alter table t add key idx_a_c (a,c); alter table t add key idx_c (c);
表t,a字段是主键,b字段是字符串长度500,在b字段创建索引,索引名是idx_b,并且只对b的前100个字符创建索引,联合s索引idx_a_c,和索引idx_c;
通过命令可以查看某张表索引的创建情况
show index from tG;
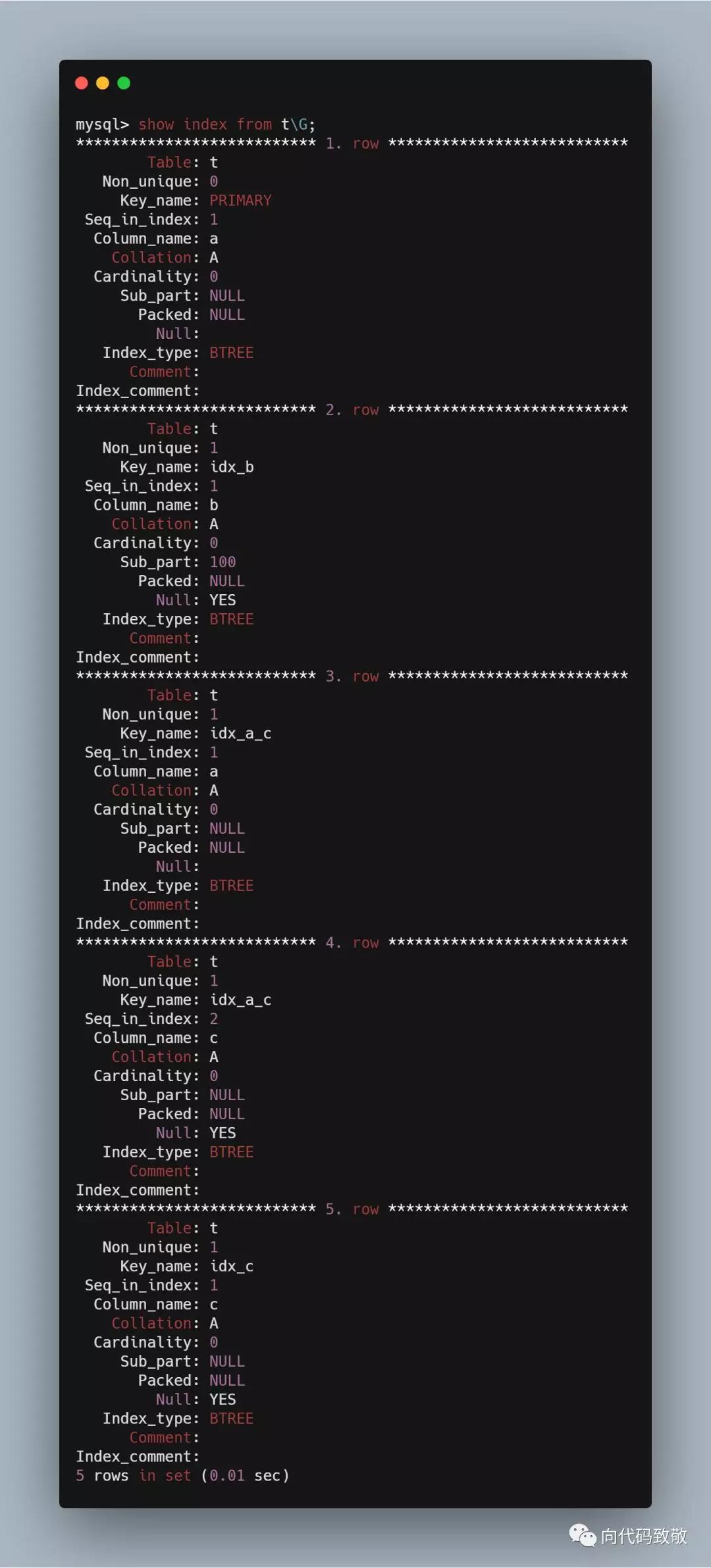

我们来分析返回的信息
-
table:索引所在的表名
-
Non_unique:非唯一索引,我们可以看到primary key是0,代表非唯一索引
-
Key_name:索引的名字
-
Seq_in_index:索引中该列的位置,可以看索引idx_a_c就比较直观
-
Column_name:字段名字
-
Collation:一般都是A,此字段不重要
-
Cardinality:非常关键的一个字段,在下面细讲
-
Sub_part:是否是列的部分被索引,b字段长度500,我们只在b的前100长度上创建索引
-
Packed:不重要
-
Null:索引的列是否包含Null值
-
Index_type:索引类型,都是BTREE
-
Comment:注释
-
Index_comment:不重要
返回数据中,有一Cardinality字段,优化器会根据这个字段来选择是否使用这个字段,不过这个字段并不是实时更新的,如果实时更新,代价比较大,如果要更新Cardinality字段的值,可以使用如下命令
analyze table tG;
Cardinality字段代表什么意思呢?表示索引中不重复记录数量的预估值,Cardinality/count(*)的值尽可能接近1(几乎没有重复字段),如果这个比值很小接近0,表示该索引中这个字段的数据大部分都是重复的,那么用户可以考虑是否有必要创建这个索引。
那么InnoDB何时更新Cardinality的值呢?
如果每次更新操作都对Cardinality进行更新统计,那么代价是非常大的,因此InnoDB对Cardinality的更新策略如下:
-
表中1/16的数据已发生过变化
-
start_modified_counter>2000000000 #20亿
如果表中某一行数据频繁的更新,表中数据量没变,变化的只是这一行。
InnoDB如何统计Cardinality的值呢?
-
取得B+数叶子节点的数量,记作A
-
随机取得8个叶子节点,统计每页不同记录得个数,记作p1,p2...p8
Cardinality = (p1+p2+..+p8)*A/8,因为是随机取得8个叶子节点,所以暗示着每次计算出得Cardinality的值有可能不同。
让我们看一下,我们公司测服上的数据库的Cardinality值
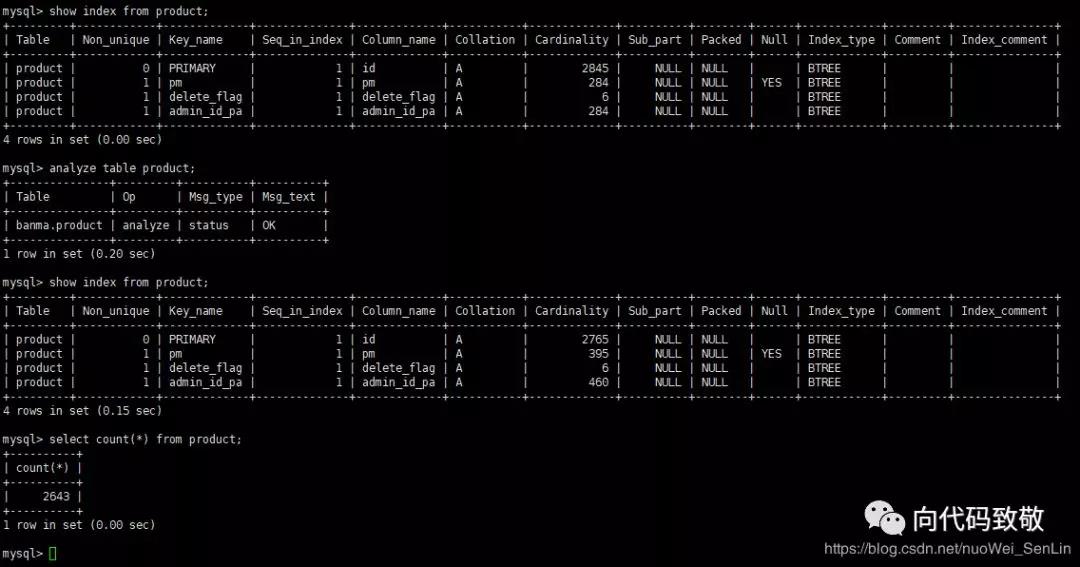
在工作中排查过的一个慢查询:
笔者有一个好朋友,在公司遇到一个很简单的单表查询,sql大概是这样的
select * from tb where status=1 and shop_id=1;
这张表数据量并不大,只有14万条,status字段上有索引,而且sql语句很简单,但是查询结果却要将近20s,笔者查询status字段Cardinality值为2,非常小,并没有用到status字段的索引,导致扫描全表。
关于覆盖索引:
-
就是select的数据列只用从索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。
-
如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫做覆盖索引。
-
当发起一个被索引覆盖的查询(也叫作索引覆盖查询)时,在EXPLAIN的Extra列可以看到“Using index”的信息
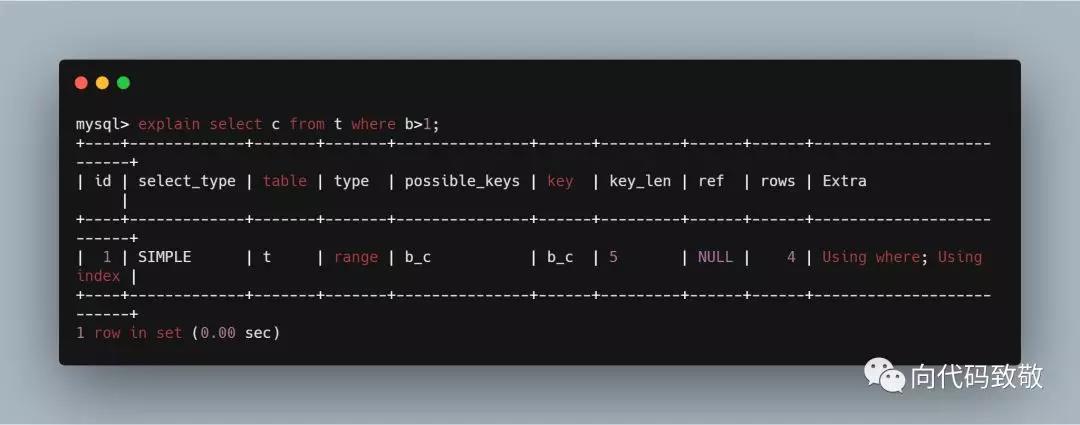
举个例子如下,建表t,a是主键,b和c中添加联合索引(b_c),并插入一些数据
create table t( a int primary key auto_increment, b int, c int, d int, key b_c (b,c) ); insert into t(b,c,d) values(1,1,1); insert into t(b,c,d) values(2,2,2); insert into t(b,c,d) values(3,3,3); insert into t(b,c,d) values(4,4,4); insert into t(b,c,d) values(5,5,5);
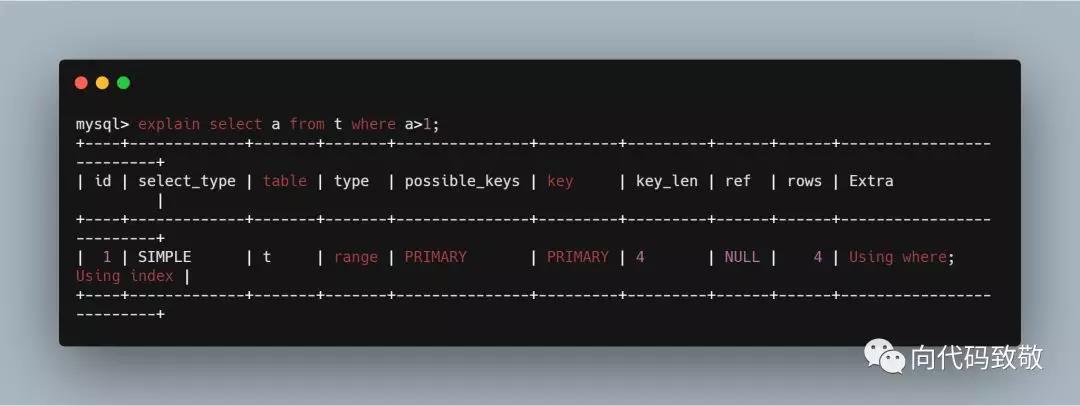
example1:我们看到,匹配到了主键,在Extra列中,出现Using index的字样;

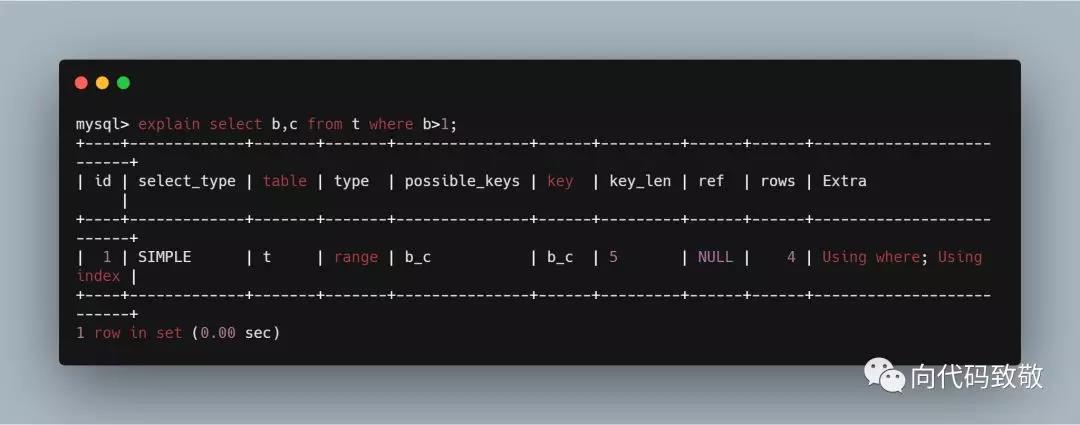
example2:我们看到,匹配到了(b_c),覆盖索引,key是b_c,在Extra列中,出现Using index的字样
example3:虽然查询条件是b,但是查询到的字段没有b/c而是d,所以key是NULL,没有用到索引;

example4:返回字段b c d,查询条件是b,索引没有完全覆盖到返回的字段。
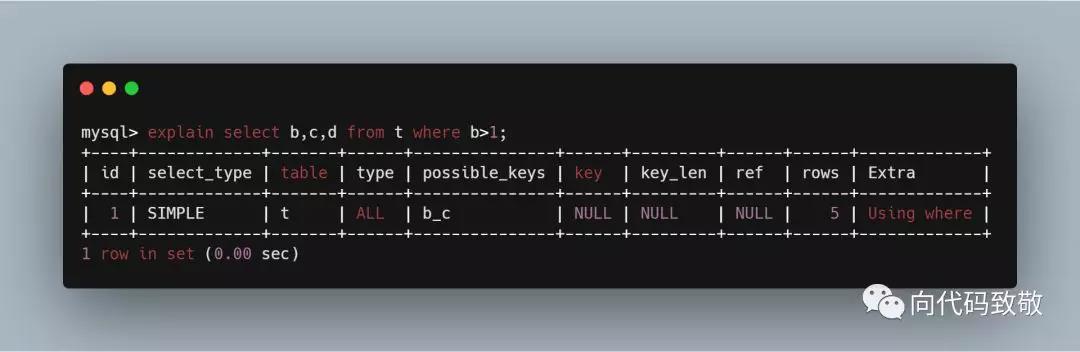
example5:没有覆盖到索引
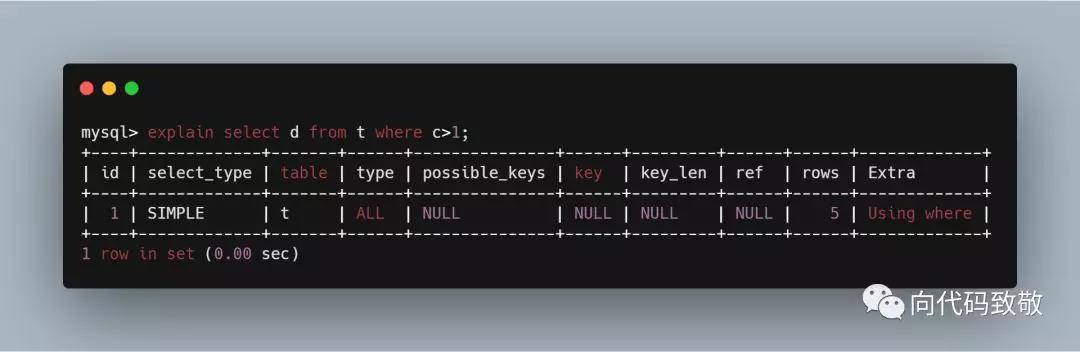
example6:索引中就包含c列的值,只用到了覆盖索引,Extra字段有Using index的字样