PSP表格
| PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
| Planning |
计划 |
30 |
20 |
| · Estimate |
估计这个任务需要多少时间 |
30 |
20 |
| Development |
开发 |
1230 |
855 |
| · Analysis |
· 需求分析 (包括学习新技术) |
90 |
70 |
| · Design Spec |
· 生成设计文档 |
60 |
40 |
| · Design Review |
· 设计复审 (和同事审核设计文档) |
30 |
60 |
| · Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
30 |
15 |
| · Design |
· 具体设计 |
60 |
40 |
| · Coding |
· 具体编码 |
800 |
390 |
| · Code Review |
· 代码复审 |
60 |
40 |
| · Test |
· 测试(自我测试,修改代码,提交修改) |
100 |
200 |
| Reporting |
报告 |
100 |
150 |
| · Test Report |
· 测试报告 |
60 |
100 |
| · Size Measurement |
· 计算工作量 |
10 |
20 |
| · Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 |
30 |
|
|
合计 |
1360 |
1025 |
一起讨论照片:

1.代码规范
1.1代码风格规范
1.缩进:4个空格。
2.空格:运算数与操作符之间要有空格。
3.括号:计算过程使用括号表示逻辑优先级。
4.断行:所有的’ { ‘ 和 ‘ } ’都独占一行。
5.分行:一条语句一行。
命名:
1.变量名:小驼峰命名法。
2.循环的临时变量统一使用ijk,临时变量使用temp1 temp2 ……。
3.函数名:大驼峰命名法。
4.接口:I+函数名。
5.注释:注释函数功能,输入输出。注释关键代码,且注释统一使用ASCII字符,不使用中文。
1.2代码设计规范:
1.Main内只做初始化和函数调用,不写具体的功能性代码。
2.对关键代码做异常处理。
3.对所有传递到函数中的参数都应该做正确性检验。
4.类中的成员按照public、protected、private的次序进行说明。
5.所有涉及到的清理工作都放在析构函数中。
6.在非必要的情况下不选择继承类。
2.需求分析
2.1基本功能
1. 统计字符数(只统计Ascii码,不考虑中文字符)
2. 统计有效行数(包括空白行)
3. 统计单词总数(至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写)
英文字母:A-Z,a-z 字母数字符号:A-Z,a-z,0-9 分割符:空格,非字母数字符号
例:file123是一个单词,123file不是一个单词。file,File和FILE是同一个单词
4. 统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
Tips:由于功能3可在功能4中得到使用,将其交与一人开发,可以提高开发的效率和正确性
2.2拓展功能
1. 能统计文件夹中指定长度的词组的词频
2. 能输出用户指定的前n多的单词与其数量
Tips:由于拓展功能2是基本功能4的普遍版本,建议直接对拓展功能进行开发,减少开发耗时。
3.接口设计及实现过程
对需求分析的进一步考虑,本次开发共设计两个类,6个函数,一个接口。
3.1基本流程
Step1: 对基本功能设置一个基类(Version1),建立4个函数去描述4个基本功能的实现。
Step2: 对拓展功能设计另一个单独的类(Version2),通过面向对象的继承关系与基类建立联系,继承基类的方法和属性,建立1个函数去实现拓展功能1。
Step3: 为了满足不同环境对代码的使用,对基本功能1,3,4独立出来,进行接口封装。
Step4: 将每个函数功能独立出来,进行C#的组件封装,作为此项目的核心Core模块。
3.2函数接口设计:
接口说明:
1 public interface CountWord 2 3 { 4 5 //统计Ascii码的个数,传入参数为文本地址,传出参数为Ascii码的个数 6 7 int CountAscii(string txtPathString); 8 9 10 11 12 //统计行数,传入参数为文本地址,传出参数为行数 13 14 int CountLine(string txtPathString); 15 16 17 18 //输出频率最高的n个单词,传入参数为文本地址,传出参数为单词和个数 19 20 Dictionary<string, int> OutputWord(string filePath, int outNumb); 21 22 23 24 //输出频n个单词构成的词组,传入参数为文本地址,传出参数为词组和个数 25 26 Dictionary<string, int> LengthDeterminingPhrases(string txtString); 27 28 29 30 //打印所有结果,传入参数为ascii数,单词数,行数,频率最高的n个单词,n个单词构 成的词组 31 32 void PrintWord(int asciiNum, int wordNum, int lineNum, Dictionary<string, int> wordFrequency, Dictionary<string, int> phraseFrequency, string outFilePath); 33 34 }
3.3关键函数设计思路及流程图:
例:OutputWord函数设计
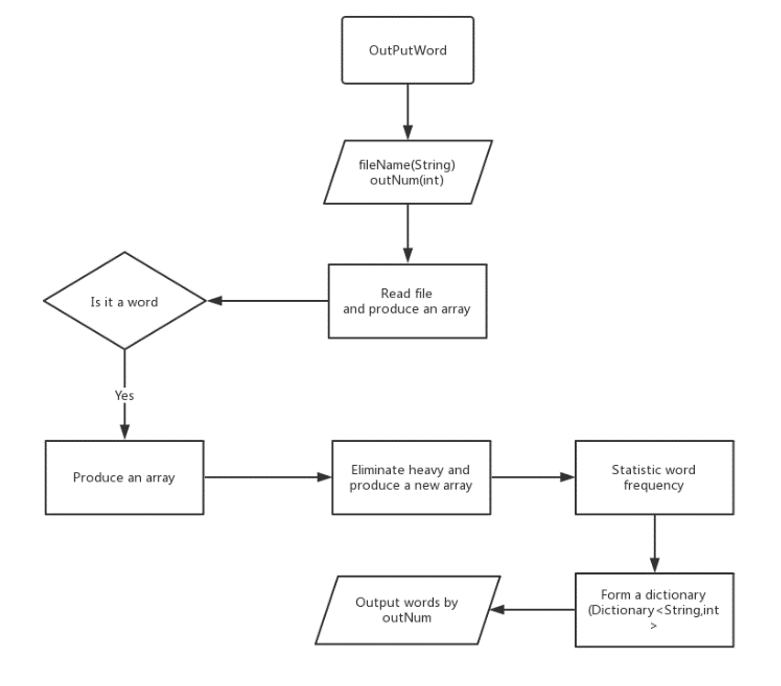
public class Outputword : IOutputWord { /// <summary> /// this function is to count the frequency of all words and sort the output descendly /// </summary> /// <param name="filePath"></param> /// <param name="outNum"></param> /// <returns> word dictionary </returns> public Dictionary<string, int> OutputWord(string filePath, int outNum) { if (!File.Exists(filePath)) { Console.WriteLine("File does not exist!"); return null; } //StreamReader to read file StreamReader sr = new StreamReader(filePath, System.Text.Encoding.UTF8); int wordNum = 0; string str = ""; string[] word = null; List<string> res = new List<string>(); //Save all words List<string> temp = new List<string>(); //Temporary word List<int> num = new List<int>(); //Save words index List<int> freqNum = new List<int>(); //Save the frequency Dictionary<string, int> dictionary = new Dictionary<string, int>(); //Save the word and its frequency Dictionary<string, int> outWord = new Dictionary<string, int>(); try { string line = sr.ReadLine(); //Read all characters in the file while (line != null) { str = str + line + " "; line = sr.ReadLine(); } //Delimiters are Spaces and special characters word = Regex.Split(str, @"[^a-z|^A-Z|^0-9]", RegexOptions.IgnoreCase); for (int i = 0; i < word.Length; i++) { //Determine if it is a word if (word[i].Length >= 4 && Regex.IsMatch(word[i].Substring(0, 4), @"^[A-Za-z]{4}$")) { res.Add(word[i]); temp.Add(word[i]); } } //Words eliminate heavy for (int i = 0; i < res.Count - 1; i++) { for (int j = i + 1; j < res.Count; j++) { if ((res[j].ToLower() == res[i].ToLower())) { num.Add(j); } } } num.Sort(); num = num.Distinct().ToList(); num.Reverse(); for (int i = 0; i < num.Count; i++) { res.RemoveAt(num[i]); } //Count words frequency for (int i = 0; i < res.Count; i++) { wordNum = 0; for (int j = i; j < temp.Count; j++) { if ((temp[j].ToLower() == res[i].ToLower())) { wordNum++; } } freqNum.Add(wordNum); } //Write the types and frequencies of words into the dictionary for (int i = 0; i < res.Count; i++) { dictionary.Add(res[i], freqNum[i]); } //Sort the value of the dictionary dictionary = DictonarySort(dictionary); //Print outNumber words for (int i = 0; i < outNum; i++) { outWord.Add(dictionary.ElementAt(i).Key, dictionary.ElementAt(i).Value); } } catch (IOException e) { Console.WriteLine(e.Message); } catch (ArgumentOutOfRangeException e) { Console.WriteLine(e.Message); } finally { sr.Close(); } return outWord; } //Sort the value of the dictionary <linq dictionary .net 3.5> private Dictionary<string, int> DictonarySort(Dictionary<string, int> dic) { var dicSort = from objDic in dic orderby objDic.Value descending select objDic; return dicSort.ToDictionary(p => p.Key, o => o.Value); } }
4.代码复审
问题:经过双方对最终代码的复审,发现代码的逻辑都不存在较大问题,更多的问题在于对细节的处理上,如:数组索引溢出,文件忘记关闭等问题。程序的注释不够详细,不能熟练使用C#自带的方法,重复造轮子。
改进: 对最初代码的设计应该更为细致,尽可能的不出现问题,通过使用断点的方式去调试程序会大大提高程序的正确性,并且能准确验证程序的逻辑性,代码还需添加更多的注释,让开发的双方都能够最快的理清程序的逻辑。掌握更多的C#方便的使用技巧,提高编码效率。
5.文件说明
最后上传到Github的文件如下,其中CountWord,OutputWord,PrintResult功能由我实现,分别建立3个类库,源代码在对应文件夹中,测试代码也在其中,CountAscii,CountLine,LengthDeteminingPhrase由罗梅实现,测试代码在对应文件夹中。将6个功能都封装成组件让Main函数调用,dll文件位于对应文件夹中。Interface specification文件为接口说明,test.txt,save.txt分别为测试用输入文件和输出文件。
6.性能分析
将总程序通过多次循环调用,通过使用vs2017性能探查器查看运行程序时的CPU使用率
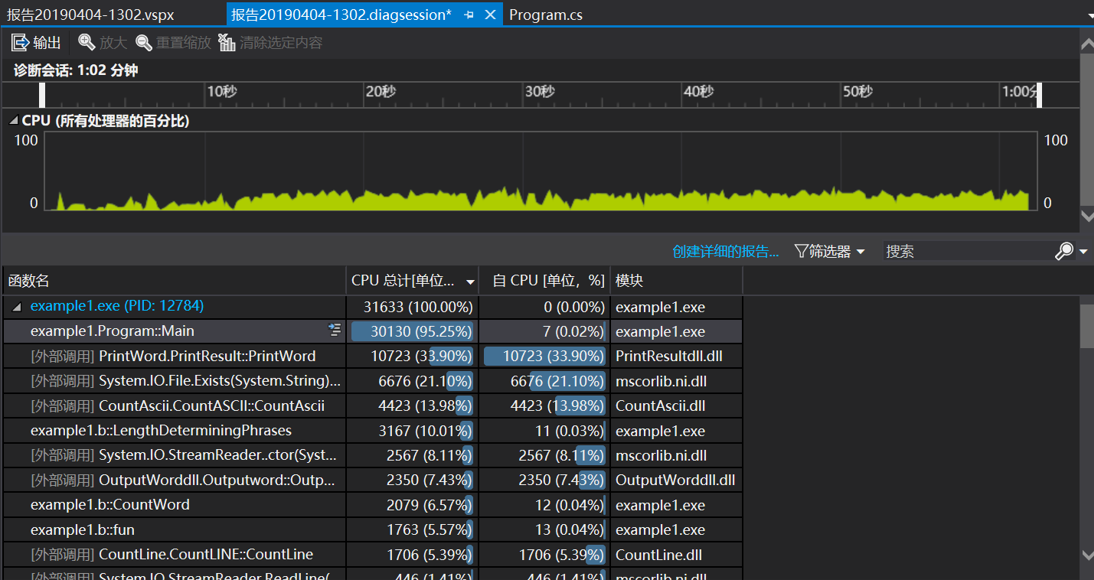
由诊断图即可看出程序34%的CPU占用率都集中在PrintResult(打印及保存结果到文本)函数,说明程序再逻辑上的效果较好,没有较多的额外CPU占用。
还有较多的CPU开销体现在System.IO类的使用上,具体的改进可以针对这方面去进行。
主要CPU占用图
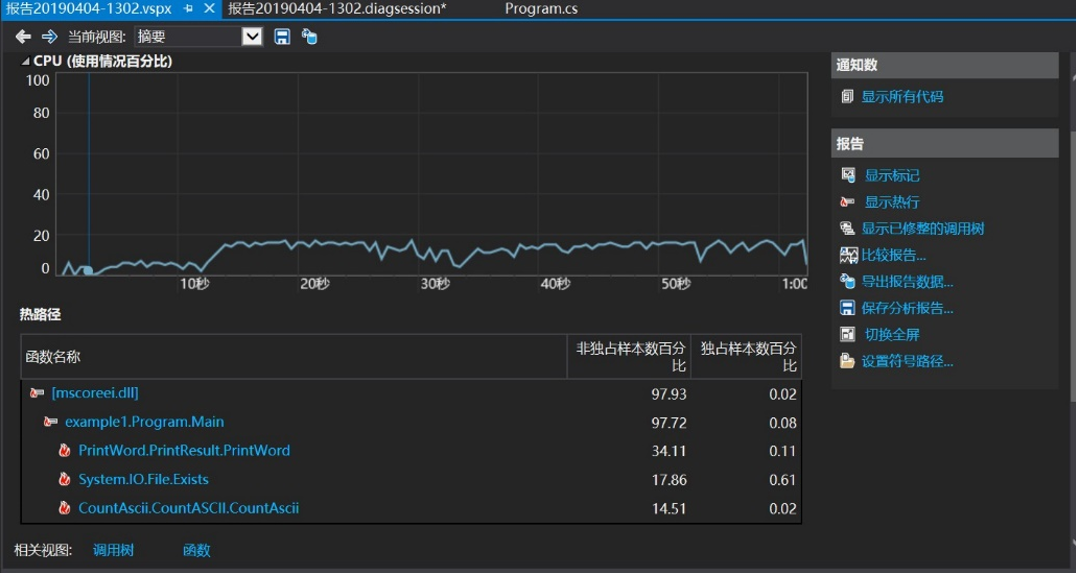
CPU占用率随运行时间的变化
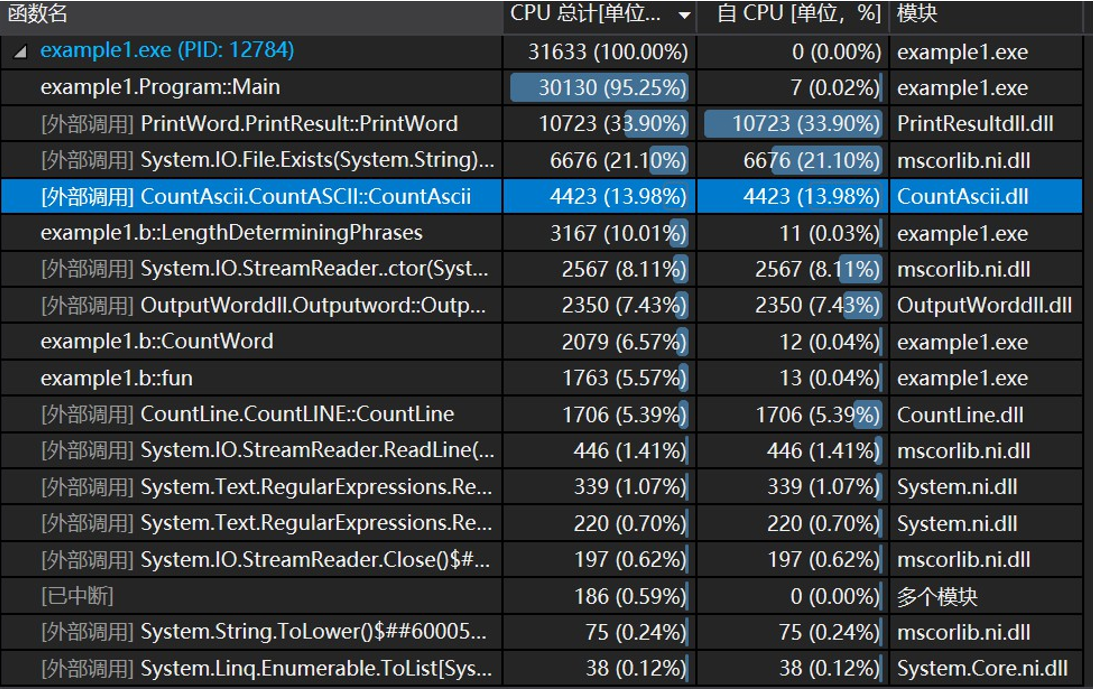
大部分CPU占用图
通过查看更为详细的CPU占用报告即可看出具体代码的CPU占用率。以CountWord类为例,找出最多占用的程序代码,由下图可看出,该类CPU的使用主要集中在使用StreamReader去读取文件功能上,由此可以从更高的读取文件的方式去改进该程序,其他类的分析同理。
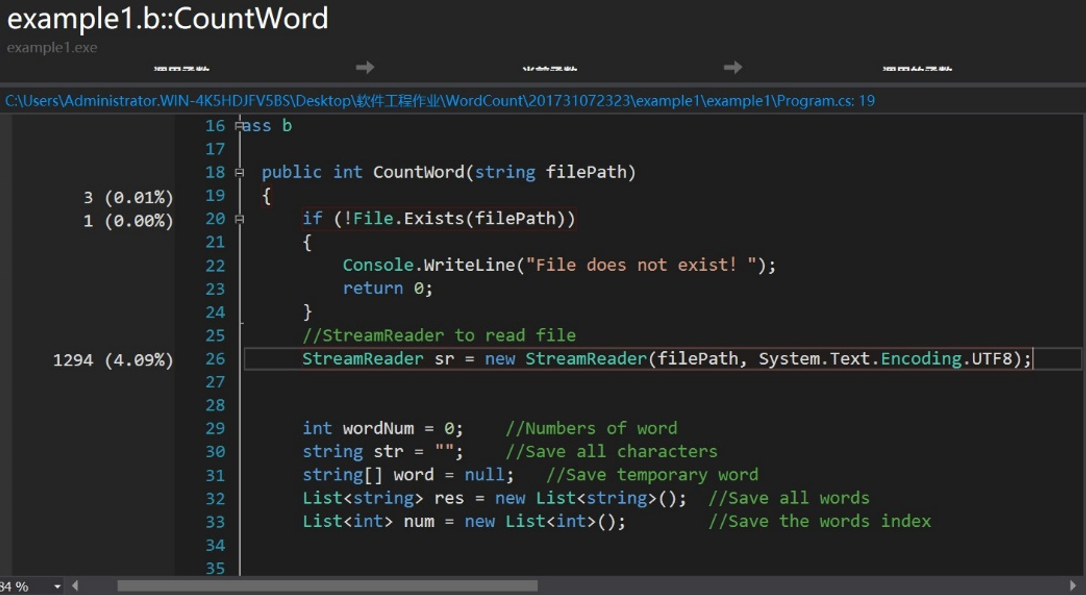
7.单元测试
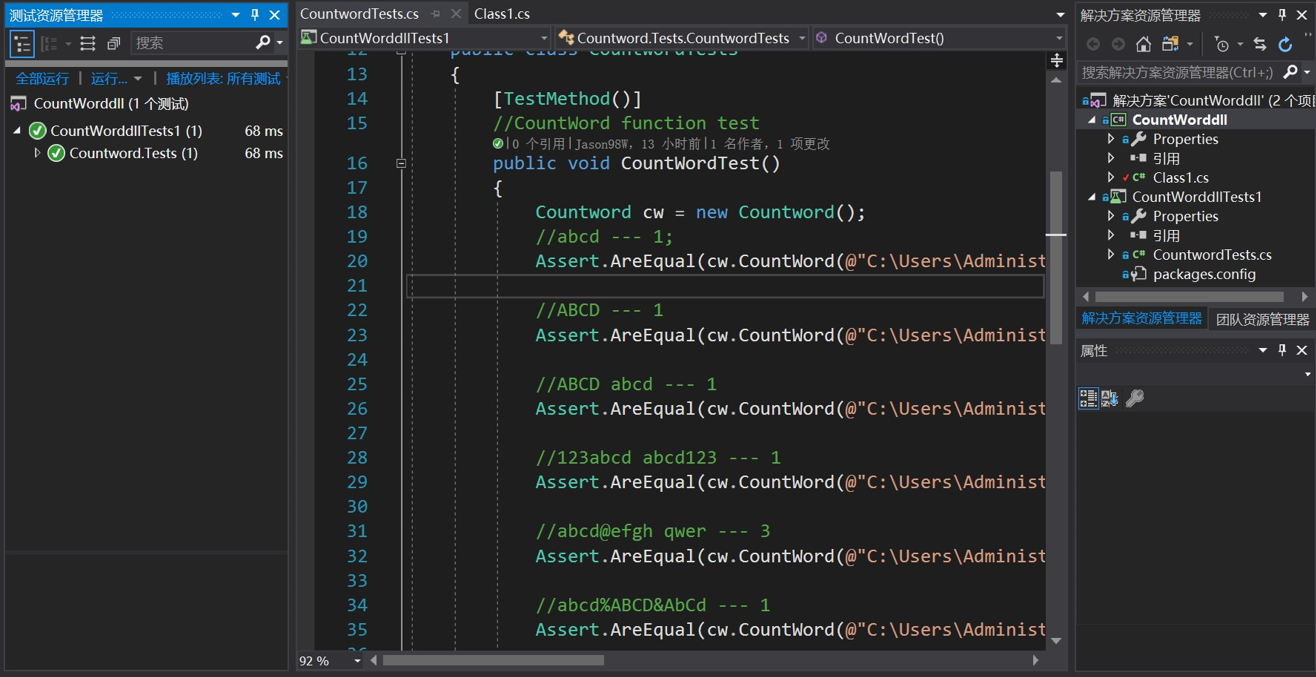
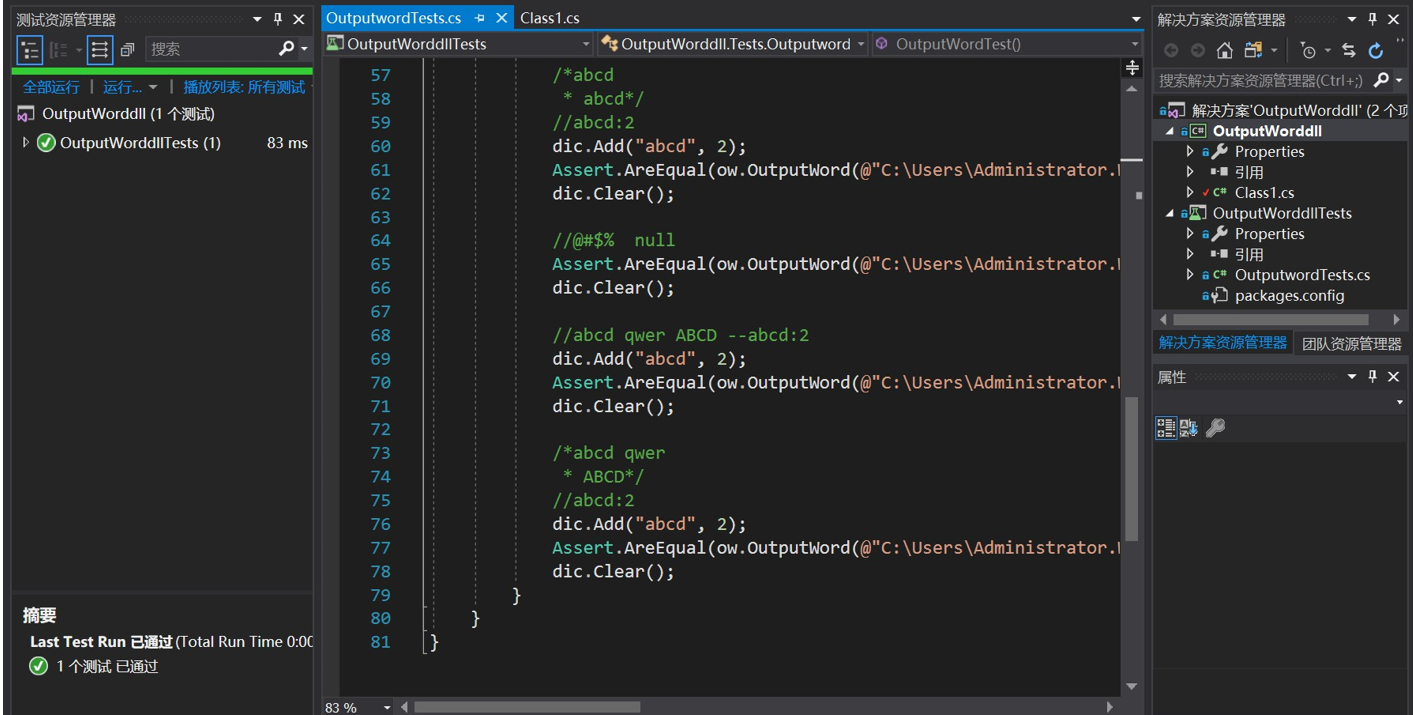
对关键类CountWord和OutPutWord进行全面的单元测试,使之满足各种复杂的情况,测试按如下方式创建10个不同的文本,对10中情况都执行单元测试,使所有的测试结果都满足预期值。
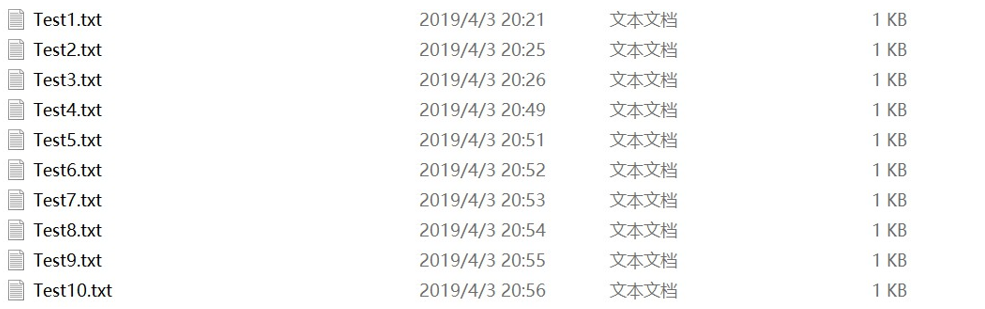
CountWord类测试均通过
OutputWord类测试均通过
8.异常处理
对异常进行单元测试,

9.结对过程
这次结对编程,确实呐,意义超大的,主要是颠覆了我对软件工程的看法,原来两个人一起开发项目的效率是那么的高,可以对每一个问题提出多种解决方案,能够总结方案的可行性,文档复审,代码复审都有利于提高项目开发的正确性。而且,结对编程时,精力是很集中的,因为每个人都对项目的完成起着至关重要的作用,不敢丝毫马虎,拒绝拖延,很棒的一次经历啊~~ 咳咳咳… 关于1+1和2的关系 这个肯定是1+1>>>>>>2 ~~
10.最终结果
最终的结果就是下图了…利用cmd进行来运行程序,还参考了吕登名同学的help方法加了一个程序使用说明
运行效果图:

程序使用说明:

11.计算工作量
在完成了整个任务以后,对上述工作进行了一个回顾总结,并大致统计了各部分的工作时间量,填入了文章开头的psp表格中,在结对编程中,最终决定,以 人/天 为计算单位,最终的工作量统计下来是 8 人天。
12.总结感悟
这次的项目做的是真爽,连续熬了好几个夜,终于圆满的把所有功能都实现咯,难得呀,感谢罗梅同学的合作~,一起改了很多Bug,分工也很明确,效率都挺高的,都主动承担了很多分工。感觉这次不仅仅将C#通通复习了一遍,还学习了新的知识,如:正则表达式,linq对Dictionart排序,组件的熟练使用, cmd的简易操作,github结对编程技巧等等等。虽然花了很多时间,但觉得很值,对专业的兴趣更加浓厚了。
但由于最初对项目的规划不够完善,出现较多次“写了又该模式”,……有点尴尬,所以呀,以后敲代码之前,细心的分析更为重要,后面写了再改的代码确实有点大~~~