成员:张贺 杨涛 石恩升
github地址:https://github.com/ThomasMrY/ASE-project-MSRA
题目简介:
此次编程的题目是——统计文本文件中英语单词的频率,作业要求我们不仅要完成题目功能,还要对我们的程序做单元测试、回归测试以及效能分析。
题目的源地址:https://www.cnblogs.com/xinz/archive/2011/11/27/2265000.html
用户需求:英语的26 个字母的频率在一本小说中是如何分布的?某类型文章中常出现的单词是什么?某作家最常用的词汇是什么?《哈利波特》 中最常用的短语是什么,等等。 我们就写一些程序来解决这个问题,满足一下我们的好奇心。
程序要具有的基本功能:
第0步:输出某个英文文本文件中 26 字母出现的频率;
第一步:输出单个文件中的前 N 个最常出现的英语单词;
第二步: 支持 stop words,即略过停用词文件里的单词;
第三步: 统计常用的短语频率,短语包含的单词数目由人为规定;
第四步:把动词形态都统一之后再计数;
第五步:统计“动词-介词”短语的频率。
前期准备:
项目前期,我们小组在一起讨论了作业的实现思路,并最终决定了我们工作流程和代码风格。
工作流程:首先,每个人根据自己的想法实现作业中的几个功能;然后,比较每个人的算法在各个任务上的性能,选择最优的版本继续开发;最后,通过pair programming的方式将最终代码汇总,并作性能分析和功能优化。之所以选择这种方式,一是为了产生更多的想法,避免思路的局限性;另一方面也是为了让不熟悉python语言的同学尽快掌握编程方法。事实证明,这种方式确实增加了我们的工作效率和讨论深度,还是很有效的。
代码风格:我们投票决定使用python作为项目的开发语言,为了提高我们的合作效率,我们规定了代码中变量、函数的命名风格以及注释的格式。
变量、函数命名风格:驼峰命名法
变量举例
wordsCount #普通变量 g_letterDict #全局变量
函数/类名举例
def CountLetters(fileName,n,stopName,verbName):
注释风格:
########################################## #Name:CountLetters #Inputs:fileName # n : output the top N items in letters # stopName: the file of stopwords skipped # verbName: the file of verb dict #outputs:None #Author: ThomasY #Date:2018.10.24 ##########################################
开发阶段:
1、项目开发过程中,因为小组成员线下交流比较方便,因此,针对各个阶段功能的实现,我们遵守了先前的约定,各自完成功能核心代码后便进行了交流。经过比较代码性能,选择较好的版本并入项目,此过程我们通过结对编程来完成。
2、每增加一个功能,我们用“单元测试”验证代码的正确性和覆盖率,以step2:支持 stop words为例说明,我们在用测试用例测试该模块代码时,发现虽然可以100%实现预期功能,但其中两行代码总是无法覆盖,如下图所示:
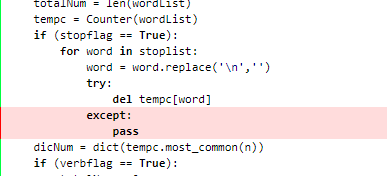
红色阴影处是我们在删除单词字典“tempc”中的元素时,为防止删除字典中不存在的元素时会报错而写的异常处理机制。分析后可知,上一步得到的“tempc”变量是“Counter”类型的,这一类型的结构在删去本身不存在的元素时会自动跳过,因此我们的异常处理是多余的。删去try...except...语句后覆盖率达到100%,如下图所示。

但是这种异常处理机制并非完全没有必要,在后续的模块中我们不得已引入了这种机制,负责整合代码的同学以为前面也需要这种处理,便将这种机制也加入了前面的模块。尽管回归测试不能发现问题,但重新对这块代码进行单元测试,还是可以找出一些不完美的地方,单元测试确实在我们持续开发进程中发挥着至关重要的作用。
其他阶段的单元测试,可以参见这篇博客:https://blog.csdn.net/qq_35001962/article/details/83627235
3.每次在原有工程上扩充一个新功能后,我们都在做单元测试的同时,测试以往功能,避免新引入的模块对以前的功能造成破坏,从而完成回归测试。
我们最终完成所有功能时的回归测试代码如下:
from CountLetters import CountLetters from CountPhrase import CountPhrases from CountPrephrase import CountVerbPre from CountWords import CountWords from CountDir import OperateInDir if (__name__ == '__main__'): # test letters CountLetters('gone_with_the_wind.txt', 10, None, None) CountLetters('gone_with_the_wind.txt', -10, None, None) CountLetters('gone_with_the_wind.txt', 10, 'stopwords.txt', 'verbs.txt') CountLetters('empty.txt', 10, None, None) CountLetters('blanks.txt', 10, None, None) # test words CountWords('gone_with_the_wind.txt', 10, None, None) CountWords('gone_with_the_wind.txt', 10, 'stopwords.txt', None) CountWords('gone_with_the_wind.txt', 10, None, 'verbs.txt') CountWords('gone_with_the_wind.txt', 10, 'stopwords.txt', 'verbs.txt') CountWords('empty.txt', 10, 'stopwords.txt', 'verbs.txt') # test phrase CountPhrases('gone_with_the_wind.txt', 10, None, None, 2) CountPhrases('gone_with_the_wind.txt', 10, None, 'verbs.txt', 2) CountPhrases('gone_with_the_wind.txt', 10, 'stopphrase.txt', 'verbs.txt', 2) CountPhrases('blanks.txt', 10, 'stopphrase.txt', 'verbs.txt', 2) # test dir OperateInDir(CountWords, 'examples', 10, 'stopwords.txt', 'verbs.txt', True) OperateInDir(CountPhrases, 'examples', 10, 'stopwords.txt', 'verbs.txt', None, 2) # test verbpre CountVerbPre('empty.txt', 10, None, 'verbs.txt', 'prepositions.txt') CountVerbPre('empty.txt', 10, 'stopverbpre.txt', 'verbs.txt', 'prepositions.txt') CountVerbPre('gone_with_the_wind.txt', 10, None, 'verbs.txt', 'prepositions.txt') CountVerbPre('gone_with_the_wind.txt', 10, 'stopverbpre.txt', 'verbs.txt', 'prepositions.txt')
4.完成题目要求的所有功能后,我们用python中自带的cProfile模块和可视化图形模块graphviz对工程做效能分析。以step1:输出单个文件中的前 N 个最常出现的英语单词为例说明,起初我的想法是用正则表达式找出文本中的所有单词,然后遍历找到的单词列表,构建单词的词典。性能分析时,我发现自己函数主体模块耗时较为严重,应该是实现“遍历”的循环结构导致的。

杨涛同学想到了用collections模块中的Counter函数来统计单词列表里不同元素的个数,只需调用一次该函数即可统计所有单词频率,性能比我实现遍历的循环要高出不少。代码改良后,耗时0.50s,明显优于先前的0.628s,而且函数主体的耗时和其他模块的耗时已经不在一个量级上了,而引入的Counter函数耗时显然远远优于循环的模块,说明优化的方向是对的。
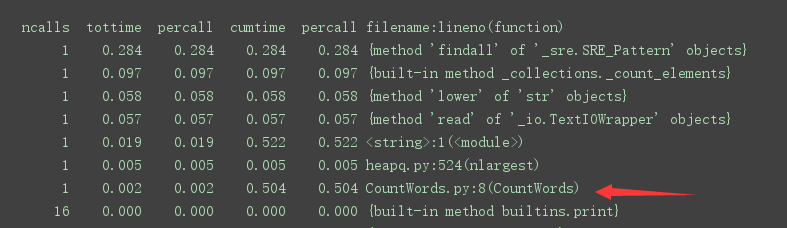
重点关注改良后效能分析图的两个耗时占比较大的模块:
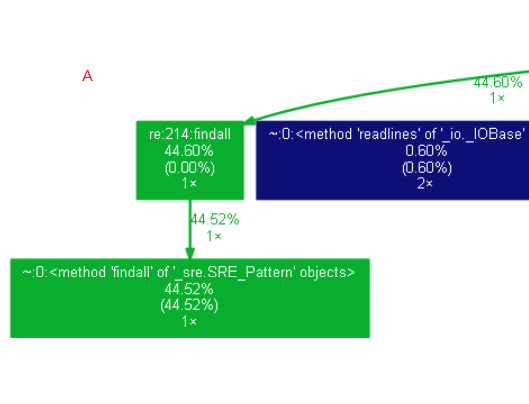
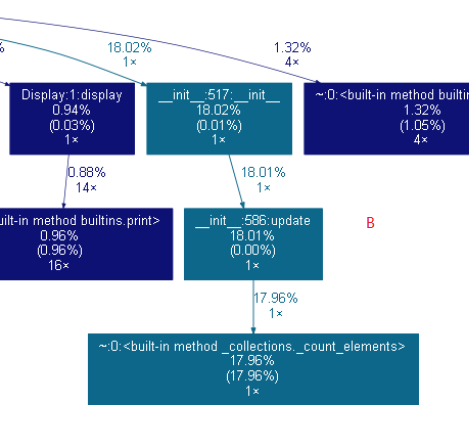
A模块是调用一次的findall函数,用来找出文本中的所有单词,很难再继续优化;B模块是调用一次的Counter函数,速度比上万次的遍历要好出很多。其他阶段的优化情况有很多,此处不一一列举,详细的优化过程可以参看这篇博客:https://blog.csdn.net/qq_35001962/article/details/83627235
队友评价:
队友甲:1.对python语言十分熟悉,不仅是我们的小老师,还经常有一些十分精彩的操作和处理;
2.执行力强,编程能力过硬,可以很快的完成预期目标;
3.做事有热情有追求,可以很好的激发队友潜力。
队友乙:1.认真负责,积极地提出工作中的疑惑和不足,并组织大家讨论解决;
2.善于交流,很好的统筹了我们的讨论计划和工作安排;
3.学习能力很强,可以很快地接受消化新知识。
队友不足:队友甲有时候想法实现的太快,有时候会忘了与我们沟通分享,他的某些暗中的骚操作在项目后期有时候会带来一点点麻烦;
队友乙在项目前期对python语言不太熟悉,编程速度较慢。
个人收获:
1.这是我第一次按照软件开发的流程写代码,体会到了很多新东西。在以前的编程中,我通常不会过分注重代码的格式和效率,只关心结果是否是我想要的,功能是否能实现。现在深刻感受到,一份结构简洁、注释清晰的代码,对于别人理解自己的思想以及自己的调试和优化都大有裨益。
2.这也是我第一次参与结对编程。在编程的过程中,有可能是因为工作量较小,并没有感觉到编程效率有明显提高,但是自己的知识广度和思维方式真的是大开眼界。在审视别人的代码时,我往往不会纠结于功能的实现过程,反而对队友的语言逻辑和异常处理格外上心,这对我养成良好的编程习惯也很有帮助。
3.我从队友身上学到很多。这次结对过程中,两位队友在某个功能中对我实现的效果并不满意,决定实现另一个较为棘手的算法。一开始我对那个算法并不看好,在“勉为其难”地参与了他们的讨论后,我发现队友地想法还是很有可行性的,最终我们一起解决了那个问题。这样的“插曲”让我感受颇深,一是体会到结对的好处,二是反思了自己不敢于尝试新算法的弱点。
4.在互相交流代码的时候,我们很自然的收集了彼此的用户体验。我开始以为这是一个并不复杂的项目,但在互相嫌弃和挑bug的过程中,我深刻感受到,想把一个看似简单的项目做到毫无瑕疵、人人接受也是一件很伤脑筋的事,可能这就是软件工程的魅力所在吧。