获取百度页面
1,确定url
2,打开url
3,返回一个html 16进制
4,转化为utf8
5,存入本地
import urllib.request
url = "http://www.baidu.com"
response = urllib.request.urlopen(url)
data = response.read()
#data数据本来为bytes类型数据,需要转换为str数据
html = data.decode("utf8")
#将html数据存入到文件中
with open("baidu.html","w",encoding="utf8") as f :
f.write(html)
获取百度的图片
获取百度翻译
1,找到json
2,找到url
3,找到接口,请求方式
F12>>左上角屏蔽键>>点击一下翻译>>找到json数据
 找到url
找到url

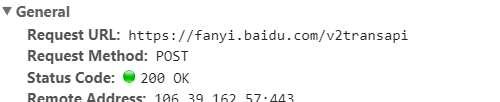
找到传入参数(data)

确定json格式,用在线json工具
 确定hero位置
确定hero位置

伪装爬虫身份
寻找User-Agent:
 1, 在创建request对象的时候,填入headers参数(包含User Agent信息),这个Headers参数要求为字典;
1, 在创建request对象的时候,填入headers参数(包含User Agent信息),这个Headers参数要求为字典;
2,在创建Request对象的时候不添加headers参数,在创建完成之后,使用add_header()的方法,添加headers。