使用技术
python3 + requests模块
安装requests模板
pip install requests
实现目标
- 可以通过控制台输入爬去图片类型
- 指定爬去图片数量
- 保存本地
页面分析
- 由于不存在翻页,但是可以通过向下滑动加载更多的图片,所以可以猜测为ajax请求
通过Chrome的开发者工具(F12)查看浏览器发出的ajax请求
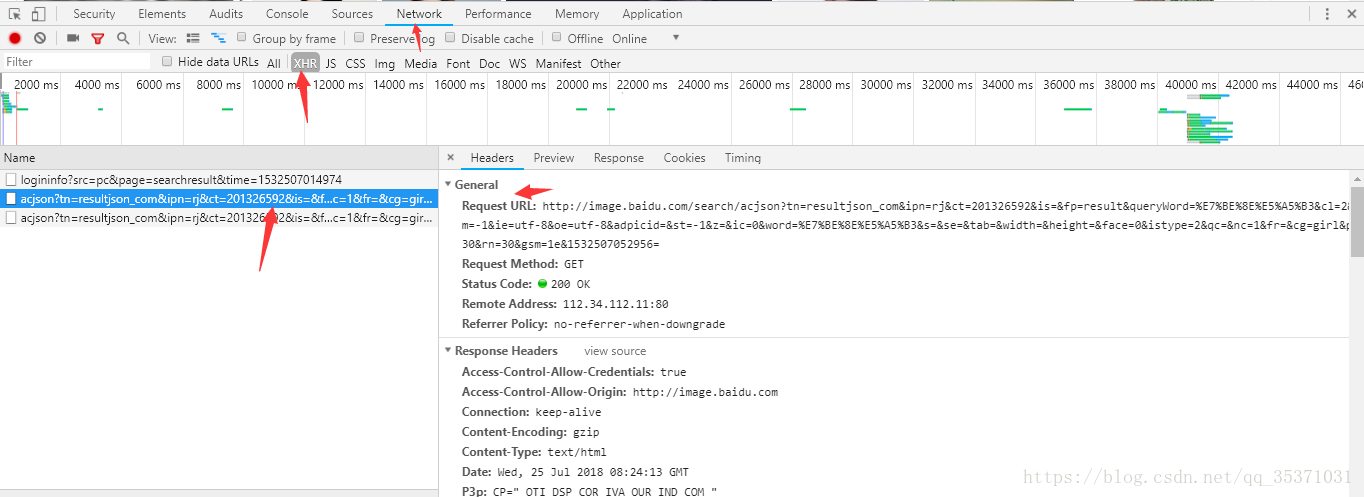
由此可以发现请求链接,浏览器单独访问得到对应的json数据如下图:

都是乱码看的还是非常头疼,不过没关系,爬虫的神器www.json.cn进行json数据的解析

这样数据格式就很清晰了,可以发现有一个数据中包含了几个相同的url,这并不妨碍提取数据,选取thumbURL 的url数据进行提取
url规则提取
上面获取的url地址太过复杂,不方便我们使用,我们可以通过不断删减已达到简化url的目的,最后得到如下url地址,返回的数据和原链接返回的数据相同
https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&rn=60&word=%E7%89%B9%E6%96%AF%E6%8B%89&pn=0
根据不断尝试,可以发现,rn代表传输多少数据,最大为60,pn代表从第几个数据显示
word表示搜索的图片类型
开始编程
首先导入模块, requests用户发送请求,re用于提取图片url, hashlib模板使用md5进行设置唯一文件名
温馨提示: 由于多线程,请求非常迅速容易被封ip,建议加上睡眠时间, 线程虽好不要太放纵
import requests
from threading import Thread
import re
import time
import hashlib
class BaiDu:
"""
爬去百度图片
"""
def __init__(self, name, page):
self.start_time = time.time()
self.name = name
self.page = page
self.url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&rn=60&'
self.header = {}# 添加为自己的
self.num = 0
def queryset(self):
"""
将字符串转换为查询字符串形式
"""
pn = 0
for i in range(int(self.page)):
pn += 60 * i
name = {'word': self.name, 'pn': pn}
url = self.url + name
self.getrequest(url)
def getrequest(self, url, data):
"""
发送请求
"""
print('[INFO]: 开始发送请求:' + url)
ret = requests.get(url, headers=self.header, data=data)
if str(ret.status_code) == '200':
print('[INFO]: request 200 ok :' + url)
else:
print('[INFO]: request {}, {}'.format(ret.status_code, url))
response = ret.content.decode()
img_links = re.findall(r'thumbURL.*?\.jpg', response)
links = []
# 提取url
for link in img_links:
links.append(link[11:])
self.thread(links)
def saveimage(self, link):
"""
保存图片
"""
print('[INFO]:正在保存图片:' + link)
m = hashlib.md5()
m.update(link.encode())
name = m.hexdigest()
ret = requests.get(link, headers = self.header)
image_content = ret.content
filename = '/home/python/baidu_image/' + name + '.jpg'
with open(filename, 'wb') as f:
f.write(image_content)
print('[INFO]:保存成功,图片名为:{}.jpg'.format(name))
def thread(self, links):
"""多线程"""
self.num +=1
for i, link in enumerate(links):
print('*'*50)
print(link)
print('*' * 50)
if link:
# time.sleep(0.5)
t = Thread(target=self.saveimage, args=(link,))
t.start()
# t.join()
self.num += 1
print('一共进行了{}次请求'.format(self.num))
def __del__(self):
end_time = time.time()
print('一共花费时间:{}(单位秒)'.format(end_time - self.start_time))
def main():
name = input('请输入你要爬取的图片类型: ')
page = input('请输入你要爬取图片的页数(60张一页):')
baidu = BaiDu(name, page)
baidu.queryset()
if __name__ == '__main__':
main()
爬取的数据