ELK表示:Elasticsearch、Logstash、Kibana 三个开源软件的缩写。是集成这三个软件于一体的日志分析及全文搜索解决方案, 被广泛应用于实时日志处理、文档索引和搜索、以及数据的多维查询和统计分析等领域。(数据采集分析展示一体化)
Elasticsearch 是一个分布式的 RESTful 风格的搜索和数据分析引擎。能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,它集中存储您的数据。(数据存储分析)
Logstash 是开源的服务器端数据处理管道。能够同时从多个源中采集数据、转换数据,然后将数据发送到您最喜欢的 “存储库” 中,例如Elasticsearch。(数据采集转换)
Kiabana是一款开源灵活的数据分析和可视化平台。使用Kibana可以对Elasticsearch索引中的数据进行搜索,查看,交互操作。您可以很方便的利用图表、表格及地图对数据进行多元化的可视化分析和呈现。(数据可视化)
2 ELK架构
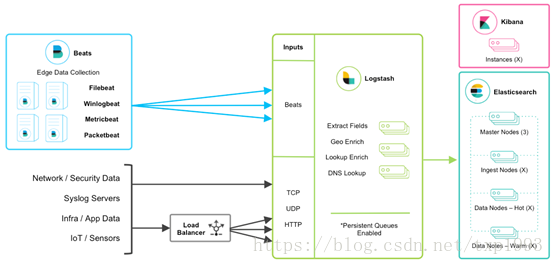
说明:
Beats 平台集合了多种单一用途数据采集器。这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向 Logstash 或 Elasticsearch 发送数据。
目前Beats包含很多数据搜集的工具:
1. Filebeat(搜集日志文件数据)
2. Winlogbeat(搜集 Windows 事件日志数据)
3. Metricbeat(搜集系统和服务的指标数据)
4. Packetbeat(搜集网络流量数据)
……
Logstash 是一个动态数据收集管道。支持以 TCP/UDP/HTTP 多种方式收集数据(也可以接受 Beats 传输来的数据),并对数据做进一步丰富或提取字段处理。数据流处理可以结合Apache Kafka, RabbitMQ,Amazon SQS和ZeroMQ等消息队列以便提高吞吐量。
ElasticSearch 是一个基于 JSON 的分布式的搜索和分析引擎。作为 ELK 的核心,它集中存储数据。
Kibana 是 ELK 的用户界面。它将收集的数据进行可视化展示(各种报表、图形化数据),并提供配置、管理 ELK 的界面。
3 应用场景
3.1 大数据运维平台
可作为大数据平台的运维方案,提供数据采集、实时分析、全文检索等功能,不仅可以提高诊断的效率,而且可以进行系统监测、网络安全监测、事件管理、bug 发现等。
3.2 实时日志分析平台
可用于实时日志分析处理平台,通过 Logstash 提供的数据采集、转换、优化和输出能力,Kibana 提供的强大可视化管理界面,以及 Elasticsearch 提供的实时分布式搜索和分析引擎,对日志信息进行实时分析、了解业务情况以及用户行为。
4 ELK的安装部署
4.1 环境配置
在ELK官网https://www.elastic.co/downloads下载最新版本的工具安装包,Windows环境选择后缀为zip格式的下载。
系统环境:
System: Windows 10
ElasticSearch: 6.3.1
Logstash: 6.3.1
Kibana: 6.3.1
Java: JDK1.8
注:由于Logstash的运行依赖于Java环境, 而Logstash 1.5以上版本不低于java 1.7,因此推荐使用最新版本的Java。
本次ELK平台搭建均在Windows环境(Windows 10)下进行,Linux平台下环境搭建和Windows下基本类似。JDK的安装不在此说明。
4.2 安装ELK
4.2.1 安装说明
由于Logstash服务依赖Elasticsearch 服务,Kibana服务依赖Logstash和Elasticsearch ,所以ELK的服务启动顺序为:Elasticsearch ->Logstash->Kibana,为了配合服务启动顺序,我们安装顺序和启动顺序保持一致。
解压三个压缩包到同一个目录中,目录的绝对路径中最好不要出现中文字符和空格。如下图(解压到E盘的ELK目录下):
4.2.2 启动Elasticsearch
1. Elasticsearch 本身查看数据要使用命令,不方便,所以装个head插件方便查询,下载地址:https://codeload.github.com/mobz/elasticsearch-head/zip/master,下载解压到elasticsearch-6.3.1目录下。
2. 进入Elasticsearch的config目录 修改elasticsearch.yml文件:
# 集群的名字
#cluster.name: my-application
# 节点名字
#node.name: node-1
# 数据存储目录(多个路径用逗号分隔)
#path.data: /home/es/data
# 日志目录
#path.logs: /home/es/logs
#本机的ip地址(设成0.0.0.0让任何人都可以访问,线上服务不要这样设置)
network.host: 0.0.0.0
#设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点
#discovery.zen.ping.unicast.hosts: ["0.0.0.0"]
# 设置节点间交互的tcp端口(集群),(默认9300)
#transport.tcp.port: 9300
# 监听服务端口(默认 9200)
http.port: 9200
# 增加参数,使head插件可以访问es
http.cors.enabled: true
http.cors.allow-origin: "*"
3. 进入Elasticsearch 的bin目录,运行elasticsearch.bat,启动ES服务,如下图:

启动成功后,访问:http://localhost:9200/,会返回如下页面:

4. 安装配置 elasticsearch-head-master ,进入 elasticsearch-head-master 解压目录。
5. 执行npm install -g grunt-cli,grunt是基于Node.js的项目构建工具(先保证安装了Node.js),可以进行打包压缩、测试、执行等等的工作,head插件就是通过grunt启动。

6. 执行npm install 安装依赖,如果npm安装出错可以换成cnpm安装.
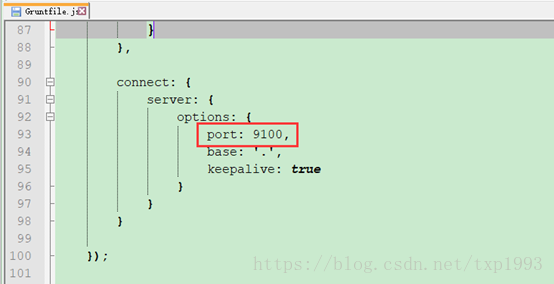
7. 修改 elasticsearch-head-master 配置
配置head服务监听地址: elasticsearch-head-master\Gruntfile.js
修改elasticsearch服务连接地址:elasticsearch-head-master\src\app\app.js
8. 执行 grunt server命令启动运行head服务

9. 启动成功后,访问地址:http://localhost:9100/,会返回如下页面:
4.2.3 安装Logstash
Logstash处理有三个阶段:inputs(接收) → filters(处理) → outputs(转发)。
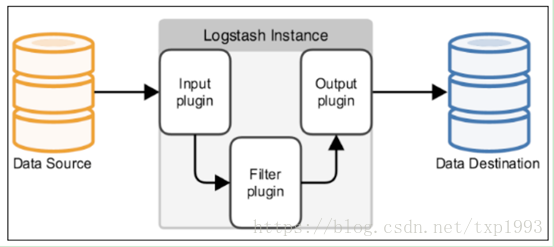
Input:输入数据到logstash。
一些常用的输入为:
file:从文件系统的文件中读取,类似于tial -f命令
syslog:在514端口上监听系统日志消息,并根据RFC3164标准进行解析
redis:从redis service中读取
beats:从filebeat中读取
Filters:数据中间处理,对数据进行操作。
Outputs:outputs是logstash处理管道的最末端组件。
一个event可以在处理过程中经过多重输出,但是一旦所有的outputs都执行结束,这个event也就完成生命周期
一些常见的outputs为:
elasticsearch:可以高效的保存数据,并且能够方便和简单的进行查询。
file:将event数据保存到文件中。
graphite:将event数据发送到图形化组件中,一个很流行的开源存储图形化展示的组件。
1. 运行cmd进入Logstash文件夹的bin目录,执行命令logstash-plugin.bat install logstash-input-log4j安装log4j插件(这种方式已经弃用,建议用filebeat,通过文件可以减少数据丢失)。
2. 在Logstash文件夹的bin目录里新建run.conf配置文件,具体内容如下(本示例以filebeat读取日志文件为例),具体参数可以自定义:
input {
beats {
host => "localhost"
port => 5544
}
}
filter {
}
output {
elasticsearch{
hosts => ["localhost:9200"]
index => "log4j-%{+YYYY.MM.dd}"
}
}
3. 在Logstash文件夹的bin目录中新建启动批处理文件run.bat,具体内容如下,并启动该脚本。
logstash.bat -f run.conf
到这里,我们已经可以使用Logstash来接收filebeat采集的日志文件数据并保存到Elasticsearch 服务中了。
4. 官网下载Filebeat-6.3.1,并解压到目录,进入Filebeat目录修改filebeat.yml的配置文件(最好别粘贴,配置格式要求很严格,建议在原文件配置修改):
filebeat.inputs:
- type: log
enabled: true
### 读取的日志文件目录
paths:
- E:\1.workInstall\ELK\work\logtest\*
multiline.pattern: ^\[
multiline.negate: true
multiline.match: after
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
output.logstash:
### 对应logstash输入的端口地址
hosts: ["localhost:5544"]
5. cmd命令进入Filebeat的安装目录,执行filebeat -c filebeat.yml –e启动Filebeat。
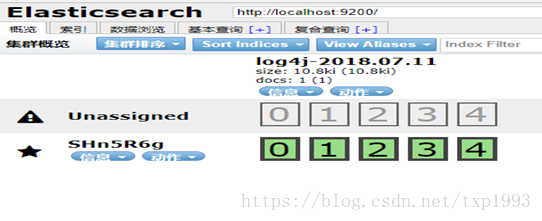
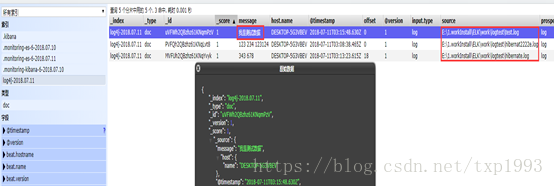
6. 查看Elasticsearch 的head页面接收显示的数据:
4.2.4 安装Kibana
1. 进入Kibana的config目录 修改kibana.yml文件:
#server.host: "localhost"
### 设置自己机器的IP
server.host: "192.168.2.23"
#elasticsearch.url: "http://localhost:9200"
elasticsearch.url: "http://192.168.2.23:9200"
2. 进入Kibana的bin目录 运行kibana.bat文件:
3. 页面访问:192.168.2.23:5601
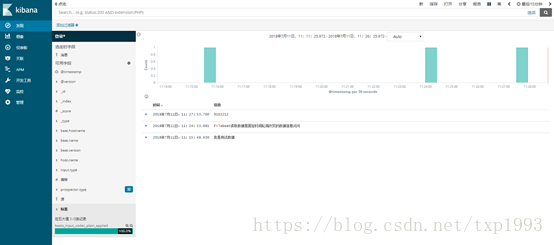
安装完毕