| 项目 | 内容 |
|---|---|
| 项目名称 | 实验四 英文文本统计分析 |
| Github的仓库主页 | https://github.com/HaiYou667/WordCount_Analysis |
| 所属课程 | http://www.cnblogs.com/nwnu-daizh/ |
| 作业要求 | 实验四 软件工程结对项目 |
| 课程学习目标 | 体验两人合作,练习结对编程; 掌握Github上增量发布软件的操作方法 |
任务一:
点评对象 :201671010434王雯涵
点评作业的地址 :https://www.cnblogs.com/han0114/p/10562516.html
点评内容 :
博文的结构基本符合实验要求。博文内容:存在一些小问题:在设计实现虽然列出了功能设计个程序流程图,但是对于流程图中的方法没有必要的说明。只列出了psp,如果能对PSP进行分析和思考就更好了。从你的psp可以看出,在具体编码阶段耗费了大量时间,需求分析,具体编码和测试的实际用时都超出预期很多,这说明在这些开发阶段还有待提高。之前下载运行了你的个人项目代码,代码还算规范,功能方面除了柱状图其他也基本符合要求,希望后期能得到完善。
点评心得:
从我的博文和结对队友王雯涵的项目对比可以看出,我们对于设计阶段的内容都不够详细,应该更具体的描述该系统的设计,并且对涉及到的类或方法进行要进行必要说明。在具体编码中,我的代码不够规范,对于一些类型和方法名起的过于简单,不能够直接明了的体现出类或方法的含义,让人不容易理解,然而王雯涵在这方面做的很好,所以在实验四中,我会弥补实验二中的不足,让代码更规范。
任务二:
1. 需求分析
本次实验任务是在实验二个人软件项目的基础上实现英文文本的统计分析。
所以本次实验的需求除了实验二所提到的还需实现下列需求:
- 统计该文本中的行数及字符数;
- 各种统计功能均提供计时功能,显示程序统计所消耗时间(单位:ms);
- 可处理任意用户导入的任意英文文本;
- 人机交互界面要求GUI界面(WEB页面、APP页面都可);
- 附加功能:统计文本中除冠词、代词、介词之外的高频词;
- 附加功能:统计前10个两个单词组成的词组频率。
2. 功能设计
根据需求分析中提到的内容,本程序中设计以下几个功能:
- 基于web的人机交互界面
- 可处理用户输入的任意文本文件
- 统计用户指定文件中单词及其词频数,且输出到指定文件;
- 统计用户任意输入的单词在文件中出现的次数;
- 以降序输出用户输入的前K个高频词的个数及其柱状图;
- 统计该文本文件中的行数及字符数
计算实现各种功能的消耗时间
3. 设计实现
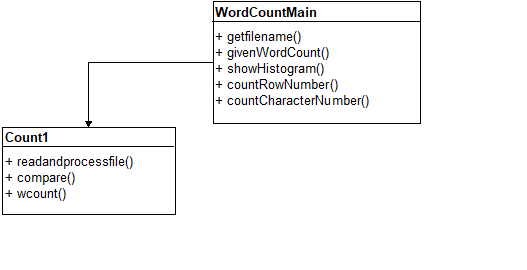
Count1类用于对文件获取和处理,它里面主要有三个方法,其中:
- readandprocessfile()方法是用来获取用户输入的文件,读取和处理文件内容
- Compare()方法是对处理后的文件中的词频进行降序排序
- wcount()方法是用来对排序处理的统计结果以文件方式保存
wordCountMain类用于处理前台页面中的用户请求,它里面主要有五个方法,其中:
- Getfilename()方法实现用户输入文件路径统计词频
- givenWordCount()方法是实现统计用户输入的任意单词在文件中出现的次数
- showHistogram()方法是实现用户输入任意有效范围K个高频词的统计
- countRowNumber()方法是实现对指定文件的行数的统计
- countCharacterNumber()方法是实现对指定文件中的各类字符数的统计
4.测试运行
1.启动Tomcat服务器,在浏览器中输入访问地址,进入主界面
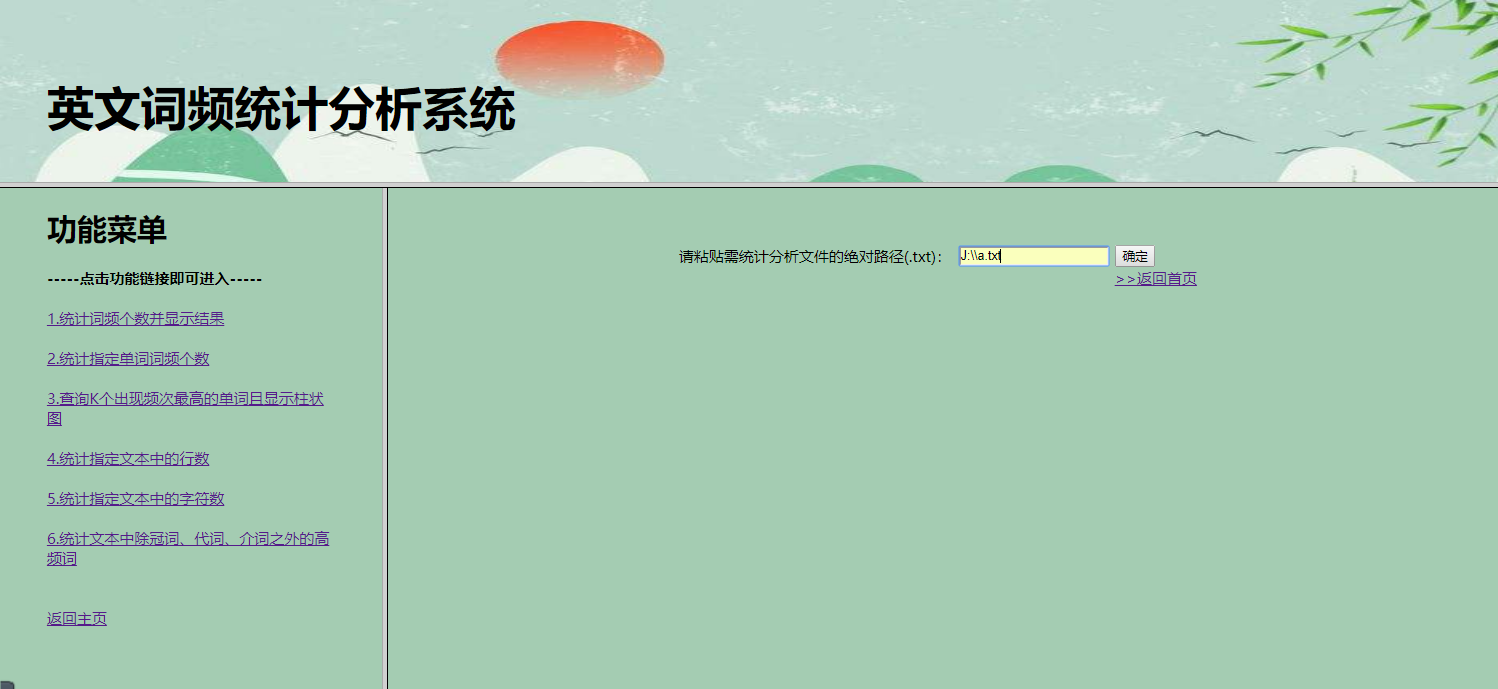
2.选择功能选项1:统计词频个数,可输入任意文本文件地址
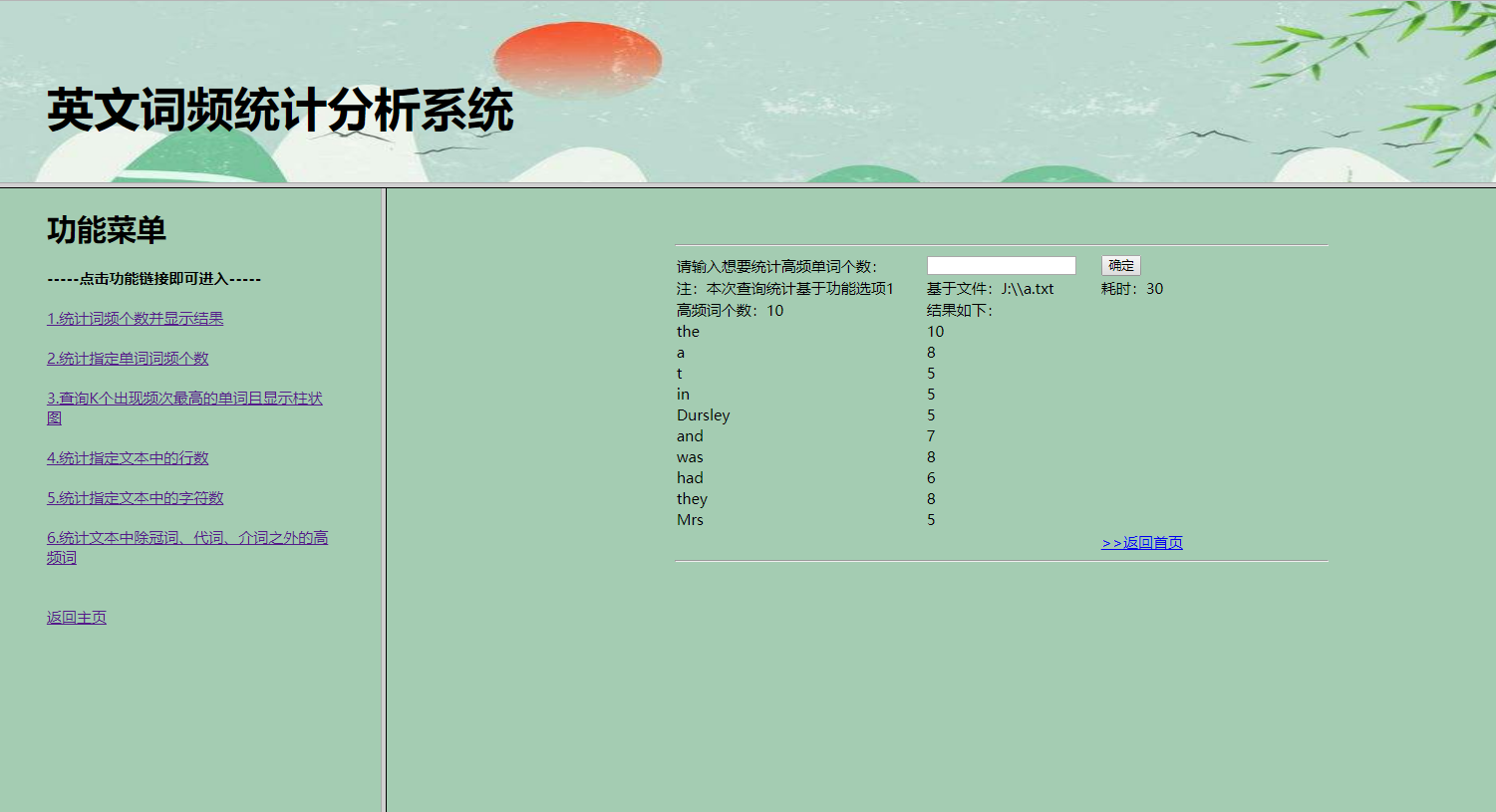
3.显示词频总数,统计结果及其消耗时间

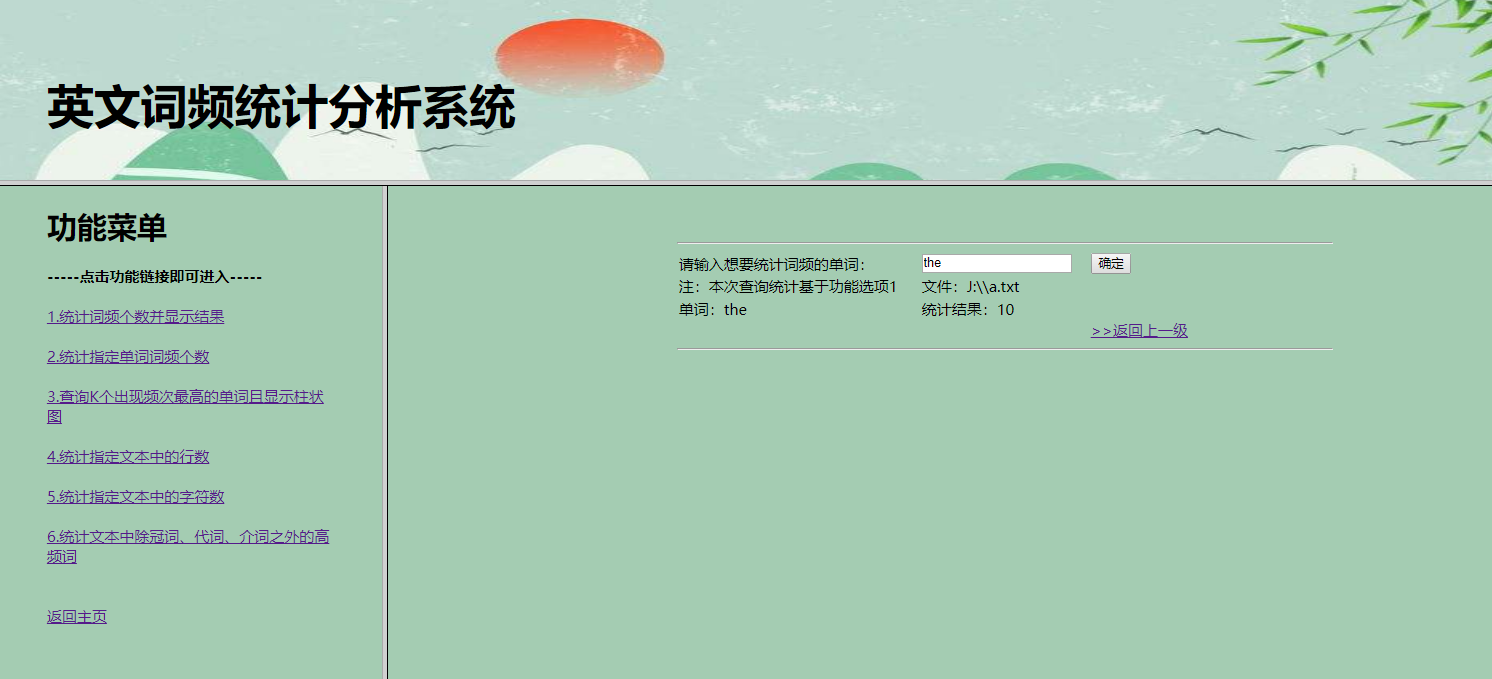
4.选择功能选项2:统计指定单词词频个数
5.选择功能选项3:查询k个高频词的词频及其统计图
6.选择功能选项4:统计指定文本中的行数及其消耗时间

7.选择功能选项5:统计指定文件中的字符数及其消耗时间

5. 部分代码展示
1.统计给定单词词频
private void givenWordCount(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
Count1 c1=new Count1();
c1.wcount(file);
List<Map.Entry<String, Integer>> ordlist = new ArrayList<Map.Entry<String,Integer>>(c1.map.entrySet());
//排序
Collections.sort(ordlist,c1.valcom);
String givenword=request.getParameter("givenword");
String word="";
int count=0;
int flag=1;
//查询统计给定单词词频
for (Map.Entry<String, Integer> entry : ordlist) {
if(entry.getKey().equals(givenword)){
word=entry.getKey();
count=entry.getValue();
flag=1;
break;
}else{
flag=0;
}
}
if(flag==1){
System.out.println("该单词"+word+"出现的个数为:"+count);
}else{
System.out.println("对不起文章中没有出现该单词!");
}
request.setAttribute("givenword", givenword);
request.setAttribute("word", word);
request.setAttribute("count", count);
request.setAttribute("file", file);
request.getRequestDispatcher("/html/givenWordCount.jsp").forward(request, response);
}
2.统计k个高频词出现的次数
private void showHistogram(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
long startTime=System.currentTimeMillis();
long totaltime=0;
Count1 c1=new Count1();
c1.wcount(file);
List<Map.Entry<String, Integer>> ordlist = new ArrayList<Map.Entry<String,Integer>>(c1.map.entrySet());
//排序
Collections.sort(ordlist,c1.valcom);
Integer k=Integer.parseInt(request.getParameter("wordnumber"));
int num=k;
Map<String,Integer> map = new HashMap<String, Integer>();
if(k>0&&k<=ordlist.size())
{
for (Map.Entry<String, Integer> entry : ordlist) {
map.put(entry.getKey(), entry.getValue());
if(--k==0)
break;
}
}else{
System.out.println("输入有误!请重新输入!");
}
long endTime=System.currentTimeMillis();
totaltime=endTime-startTime;
request.setAttribute("totaltime", totaltime);
request.setAttribute("ordlist", map);
request.setAttribute("k", num);
request.setAttribute("file", file);
request.getRequestDispatcher("/html/HighFrequencyWordsAndHistogram.jsp").forward(request, response);
}6. 总结:
第一次尝试两人合作的软件开发模式,刚开始非常的不适应,在结对编程的时候因为两个人的编码习惯不同,思维方式也不同,会出现意见不一致,矛盾争吵等问题,但慢慢的熟悉之后就会发现结对编程其实也有好多好处,我觉得最大的好处就是减少了代码出错的概率。一个人编程时总会出现一些细小又不易察觉的错误,但两人结对时,对方就会注意到这些小问题并且及时指出,从而减少了出错的概率。
下面是我们结对编程过程情景:

7.PSP个人软件过程
| PSP2.1 | 任务内容 | 计划共完成需要的时间(min) | 实际完成需要的时间(min) |
|---|---|---|---|
| Planning | 计划 | 5 | 6 |
| •Estimate | • 估计这个任务需要多少时间,并规划大致工作步骤 | 5 | 6 |
| Development | 开发 | 562 | 591 |
| ••Analysis | 需求分析 (包括学习新技术) | 10 | 15 |
| •Design Spec | • 生成设计文档 | 5 | 7 |
| •Design Review | • 设计复审 (和同事审核设计文档) | 5 | 7 |
| •Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 7 | 7 |
| •Design | 具体设计 | 10 | 10 |
| •Coding | 具体编码 | 500 | 510 |
| •Code Review | • 代码复审 | 5 | 10 |
| •Test | • 测试(自我测试,修改代码,提交修改) | 20 | 25 |
| Reporting | 报告 | 15 | 15 |
| ••Test R1eport | • 测试报告 | 4 | 3 |
| •Size Measurement | 计算工作量 | 5 | 6 |
| •Postmortem & Process Improvement Plan | • 事后总结 ,并提出过程改进计划 | 6 | 6 |
对PSP分析和总结:
对比上次的个人项目PSP,可以看出本次实验在计划,需求分析等方面的用时都相对减少,因为部分需求之前已分析过。本次项目是在上次项目的基础上实现,按理说在具体编码方面应用时更少才对,但实际却恰恰相反,主要原因是本次实验要实现基于web的人机交互,而我对于web项目又比较生疏,要实现又相当于重新学习一遍,这期间遇到了许多问题像Eclipse中服务器的配置,Tomcat服务器无法启动,服务器运行显示端口占用,web项目jsp报错,el表达式的使用,还有Echarts的学习等等,所以在这方面耗费了大量时间,但经过自己一步一步遇到问题,解决问题还是感觉挺有成就的,往后需要更加努力。