点击打开链接
点击打开链接
一、定义
对象检测:预测对象的位置和类别。对于图像中的每个对象实例,预测五个变量,类名,矩形框四个变量(左上,左下,右上右下)。
二、应用
人脸识别、计数(例如数人、车、花朵,最近因为监控设备的需求不断上升,此项应用有更大的前景),可视化搜索引擎(利用对象检测构建数据输入通道,)、航拍图像分析(利用卫星拍摄来对象检测,并且计数产生高质量的数据,一些公司利用无人机来探查某些人类难以到达的区域或者利用目标检测来做一般目标分析,一些顶级的公司利用自动检测和为题定位,实现无人干预)
三、挑战
1.变化的对象数目
因为在图像中的对象数目是不固定的,无法确定正确的输出数目。因此,一些后置处理需要被添加,增加了模型的复杂性。传统的解决办法是基于窗口(滑动的窗口)来生成固定大小特征的方法,得到这些特征之后,一些被遗弃另一些被合并得到最后的结果。
2.调整检测对象的窗口大小
即在进行分类时候,既希望占图片大部分的对象进行分类,又想要找到一些可能只有12个像素、或者是原始图像一小部分的小对象。使用不同尺寸的滑动窗口可以解决这个问题,但效率很低。
3.建模
如何同时满足两种要求:即将定位和分类结合到一个单一的神经网络。
四、经典传统方法
1. Viola-Jones framework proposed in 2001 by Paul Viola and Michael Jones in the paper Robust Real-time Object Detection,这种方法快速但是相对简单,这种算法可以进行实时凡是粗略的人脸检测,是在傻瓜相机中实现的一种算法。
2.使用定向梯度HOG特征和支持向量机SVM进行分类,仍采用多尺度滑动窗口和1方法相比,虽然效果更佳,但是速度要慢得多。
五、现代深度学习方法
发展:
1.overfeat
第一个对象检测的深度学习方法,提出了一种使用卷积神经网络的多尺度滑动窗口算法。
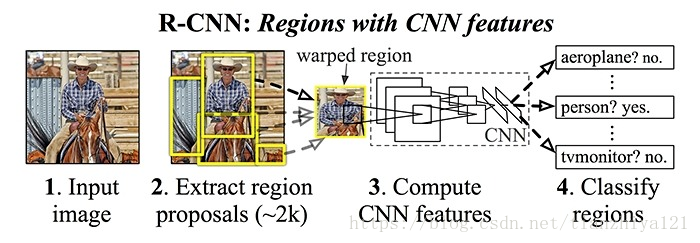
2.R-CNN基于卷积神经网络特征的区域方法
不同的区域提出不同的天,然后提取可能的对象(最常用的是选择性搜索算法),用CNN从区域提取特征,用SVM对区域进行分类。
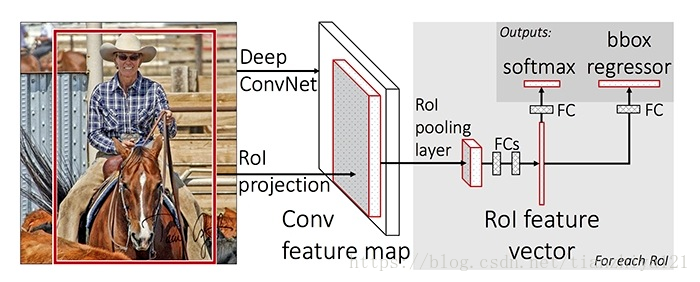
3.快速R-CNN(fast R-CNN)
R-CNN快速升级成深度学习方法,之后的fast r-cnn与r-cnn相似,使用选择性搜索生成对象的提案。与R-CNN不同的是,R-CNN独立地提取各区域的所有特征,然后使用SVM分类器;Fast R-CNN在整个图片上使用CNN,然后对特征映射使用“兴趣区域” (Region of Interest, RoI) 池化,最后使用前馈网络进行分类和回归。这种方法不仅速度更快,而且具有RoI池化层和全连接层,这使模型具有端到端的可微性并且更容易训练。Fast R-CNN最大的缺点是,模型仍然依赖于选择性搜索(或其他区域方案算法),这使推断成为了它的瓶颈。(补充sspnet理解)
4.YOLO(You Only Look Once: Unified, Real-Time Object Detection)

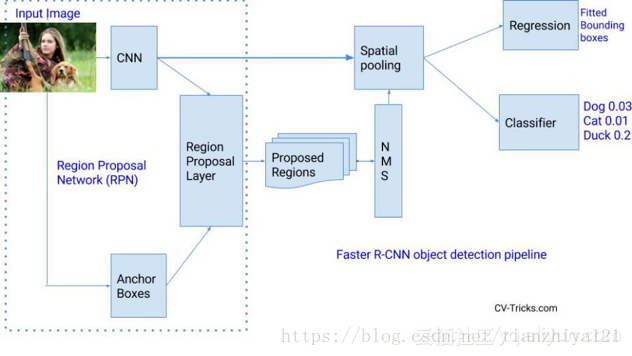
5.更快的R-CNN(Faster R-CNN)
更快的R-CNN。它添加了区域提案网络 (Region Proposal Network, RPN),摆脱了选择性搜索算法,并可以做到端到端的训练。RPNs的任务是基于objectness分数输出对象,然后用RoI池化 (RoI Pooling) 和完全连接层分类。