第二十五周学习笔记
im2latex
本次实验使用的是github上别人公开的代码并参考了及其配套博文
背景介绍
大数据与高性能GPU的出现促进了深度学习的发展,其中,尤以深度神经网络为代表,在多项基准测试中超过传统基于规则的方法和统计学习方法,成为当前的一大热点。在一般的认知中,人工智能任务主要集中在分类(回归)和聚类上,诸如logistic回归、朴素贝叶斯、决策树、k-means聚类等统计学习方法以及Boosting、Stacking等集成学习方法在解决此类问题上已经有了很好的表现,然而,大数据和人工智能领域仍然存在一些更具挑战性的目标,机器翻译(文本到文本)、风格迁移(图像到图像)、图像理解(图像到文本)、图像生成(文本到图像)涉及到生成结构化的数据(structured data),即图像和文本,二者与单纯的标签(类别)输出相比,是更加困难的任务,图像要符合人类视觉习惯,在局部和整体上都需要一定的合理性,而文本需要前后逻辑通顺,这些单纯使用基于规则的方法和传统统计学习方法是难以完成的。
得益于深度神经网络的发展,各种端到端模型的产生给出了很多state-of-the-art的解决方法。从而各种在线翻译结果大有提升,照片风格迁移也早已嵌入各类一键调用的应用中。
在进行文章写作时,时常会需要手动输入参考文献上的公式,虽然latex的出现大大规范、便捷了公式的键入,但是反复敲打公式仍然是一项繁琐而徒劳无功的任务,以此为契机,本文研究pdf文件中,数学公式的截图逆向生成latex代码的方法,即上文所说的图片到文本,这个过程恰是书写latex代码编译为pdf文件的逆过程。
数据来源
为了构建截图生成latex代码的模型,首先需要准备数据,数据是来源于arxiv.org上的论文中公式latex源码和pdf截图对(数据集),分为训练集76053对图片-latex源码对和测试集9447对,一对示例数据如下
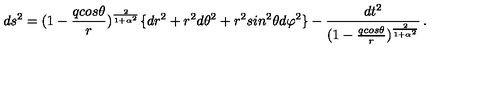
d s ^ { 2 } = ( 1 - { \frac { q c o s \theta } { r } } ) ^ { \frac { 2 } { 1 + \alpha ^ { 2 } } } \lbrace d r ^ { 2 } + r ^ { 2 } d \theta ^ { 2 } + r ^ { 2 } s i n ^ { 2 } \theta d \varphi ^ { 2 } \rbrace - { \frac { d t ^ { 2 } } { ( 1 - { \frac { q c o s \theta } { r } } ) ^ { \frac { 2 } { 1 + \alpha ^ { 2 } } } } } , .
问题叙述
本文需要解决的问题是从数学公式截图逆向生成latex源码的任务,需要构建一个以截图为输入,latex代码为输出的模型。
解题思路
思路1,OCR+编译
解决数学公式截图到生成latex源码的一个最朴素的思想是将整个过程分为以下两大步轴:
- 通过光学字符识别(OCR)得到图片中的字符
- 根据字符间的位置关系,编译为latex源码
优点
两个分步符合逻辑,简单明了,依托于现有的技术,OCR容易实现
缺点
当前OCR技术包多为各国语言的单个或混合封装模块,没有数学符号的模块,需要自行建立数据集训练
由字符位置关系重构latex源码的编译器需要大量的规则,编译器的编码难度预估与重写latex编译器的难度相当
思路2,深度神经网络端到端模型
所谓端到端模型,就是利用神经网络灵活的输入输出模式,设计一个网络架构,使得原始图片输入到神经网络中后,直接可以产出latex源码,从而省略复杂的图像预处理和特征工程等工作,这些步骤将由网络自行学习完成,在大规模的训练集训练中,神经网络将有可能学习到截图到代码的直接映射。
优点
一个模型一步到位,无需在各个模块步骤中协调
缺点
- 网络架构需要进行精心挑选和设计
- 参数设定困难,失之毫厘,差之千里
- 鲁棒性差,图片的微小改动将导致结果千差万别
模型建立
最终我们选择深度神经网络端到端模型,启发于机器翻译的端到端模型,我们的模型也由一个Encoder和一个Decoder组成,二者都是神经网络,其中,Encoder负责提取图片中的信息并编码为向量,Decoder负责从该向量中解码得到latex代码,与机器翻译中使用编码和解码文本的LSTM作为Encoder和Decoder不同,我们需要能够编码图片的神经网络,即卷积神经网络
Encoder
我们需要从图片中抓取重要特征,因此我们使用在图像上表现突出的卷积神经网络(CNN)作为Encoder,接受图像作为输入,将图像转化为低维的特征向量。
Decoder
得到低维的图像特征表达后,即可使用Decoder将之解码得到latex源码,由于传统的文本端到端模型中,Decoder中的LSTM初始隐变量为Encoder中LSTM的最后一个隐变量,但因为Encoder不再是一个LSTM网络,而是一个卷积神经网络,因此,采取设定参数令神经网络自行拟合矩阵W和向量b来学习第一个隐藏单元
损失函数
使用生成序列和目标序列的交叉熵作为损失函数(加上交叉熵公式)
模型度量
- Loss
- BLEU-4
- Perplexity
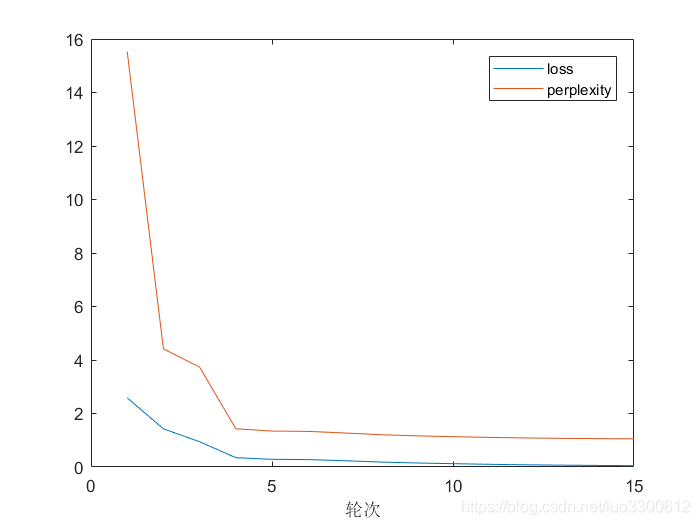
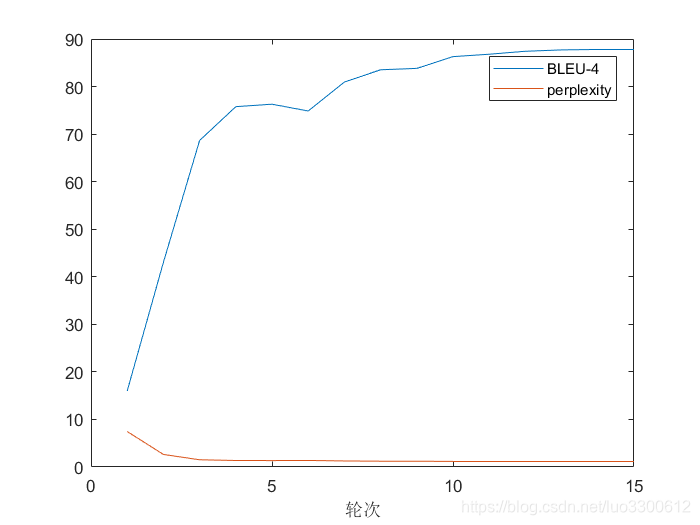
训练结果
模型总共迭代15轮,每轮训练结束后会在测试集上运行当前模型,模型在训练集和测试集的表现分别如下
训练集表现
测试集表现
采样测试
手动选择一些测试集中的数据来测试模型的效果,选取了三个示例如下
输入图片:

输出公式:
\alpha _ { 1 } ^ { r } \gamma _ { 1 } + \ldots + \alpha _ { N } ^ { r } \gamma _ { N } = 0 \quad ( r = 1 , . . . , R ) ; ,
输入图片:
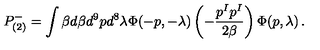
输出公式:
P _ { ( 2 ) } ^ { - } = \int \beta d \beta d ^ { 9 } p d ^ { 8 } \lambda \Phi ( - p , - \lambda ) \left( - { \frac { p ^ { I } p ^ { I } } { 2 \beta } } \right) \Phi ( p , \lambda ) , .
输入图片:
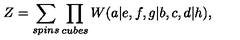
输出公式:
Z = \sum _ { s p ; n s , u b s s } W ( a | e , f , g | b , c , d | h ) ,
重新使用latex编译结果为
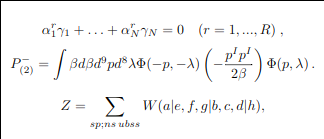
可见模型对于复杂的公式,具有一定的识别能力
结论
通过本次实验,我们学习到了神经网络的有关知识,对于分类、聚类、结构化数据生成等人工智能目标有了更好的了解。
本文构建了数学公式截图到latex的端到端模型,借助网上的预处理好的训练集,通过调参训练,得到了在测试集上也具有一定准确率的模型,模型可以识别各种数学符号,也可以识别复杂数学公式中的各个成分从而实现代码重建,虽然仍然存在一些错误,但是从实际应用考虑,已经可以作为书写论文的辅助工具,在实际应用中,人们可以先使用模型生成公式,再人工进行微小改动,即可完成公式的书写,如此可以有效提高写作的效率。