序言
与单机环境下编程相比,分布式环境下的编程有两点不同:
- 分布式环境下,会出现一部分计算机工作正常,另一部分计算机工作不正常的情况,程序需要在这种情况下尽可能地正常工作,挑战非常大。
- 单机环境下,大部分函数采用同步调用;在分布式环境下,函数调用的返回时间可能是单机环境下的100倍,所以分布式环境下的RPC通常采用异步调用。
第一章 概述
1、分布式存储分类
数据的种类大致可以分为三类:
- 非结构化数据,比如图像,音频,视频等。
- 机构化数据,储存在关系数据库中,可以用关系表结构来表示的。
- 半结构化数据,模式化结构和内容混在一起,比如 HTML 文档,XML。
根据储存数据种类的不同,可以将储存系统分为以下几类:
- 分布式文件系统,存储非结构化数据,典型的系统有 Facebook Haystack,Taobao File Systen。
- 分布式键值系统,存储关系简单的半结构化数据,典型的有 Memcache 。
- 分布式表格系统,存储关系较为复杂的半结构化数据, 典型的有 Google Bigtable 。
- 分布式数据库,存储结构化数据。典型的系统有 MySQL 。
第二章 单机存储系统
1、硬件基础
传统的数据中心网络拓扑为三层结构,该网络拓扑下,同一接入层下服务器之间带宽相同,不同接入层的服务器带宽会出现不一致的情况,因此,设计系统时需要考虑服务器是否在一个机架内。
为了减少系统对网络拓扑结构的依赖,可以采用三级 CLOS 网络,使得任何两台服务器之间的带宽都相同。
2、单机存储引擎
2.1 哈希存储引擎
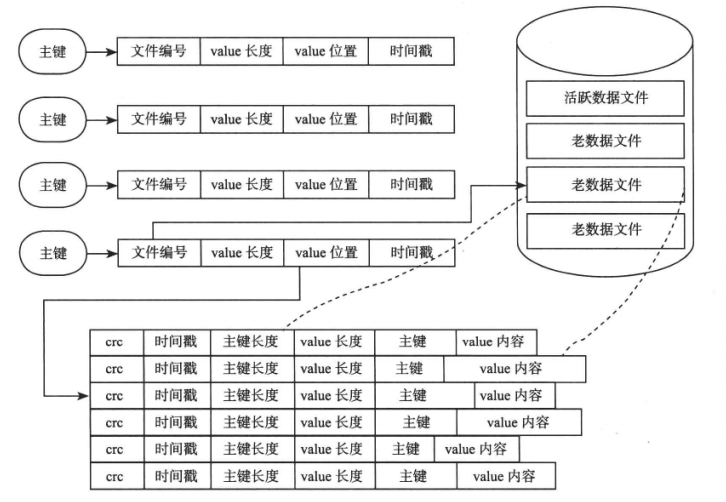
Bitcask 是基于哈希表结构的键值存储系统,仅支持追加操作。内存中采用的是基于哈希表的索引,哈希表结构中的每一项包含文件编号(file_id),value 在文件中的位置(value_pos),value 长度(value_sz)。通过读取 file_id 对应的文件,从 value_pos 开始的 value_sz 个字节,就可得到 value 值。

2.2 B 树存储引擎
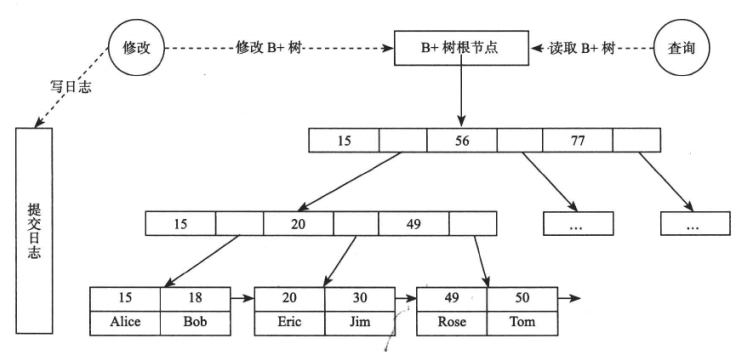
叶子节点保存每行的完整数据,非叶子节点保存索引信息。数据库查询时从根节点开始二分查找到叶子节点,每次读取节点时,如果节点不在内存中,需要从磁盘中读取并缓存。
缓冲区管理器会决定哪些页面淘汰,缓冲区的替换策略有以下两种:
- LRU,淘汰最长事件没有读或者写的块。
- LIRS,将缓冲池分为两级,数据首先进入第一级,如果数据在较短时间内被访问两次或者以上,则成为热点数据进入第一级,每一级内部还是采用LRU 算法。
2.3 LSM树存储引擎
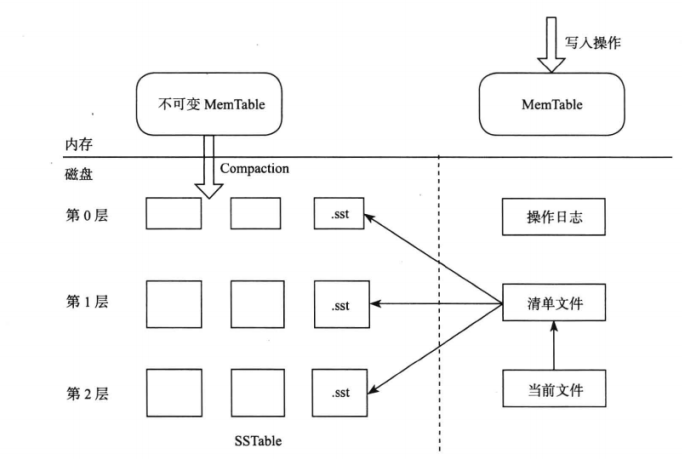
LSM 树就是将对数据的修改增量保持在内存中,达到指定大小后将这些修改操作批量写入磁盘,读取时需要合并磁盘中的历史数据和内存中最近的修改操作。
LevelDB 存储引擎包括:内存中的 MemTable 和不可变的 MemTable。写入记录时,LevelDB 会先将修改操作写入操作日志,之后再将修改操作应用到 MemTable,这样就完成了写入操作。MemTable 的大小达到上限值后,LevelDB 会将原先的 MemTable 变成不可变 MemTable,并重新生成新的MemTable,之后的修改操作记录在新的 MemTable 中。同时 LevelDB 后台线程会将不可变 MemTable 的数据转储到磁盘。
3、故障恢复
分布式系统一般使用操作日志技术来实现故障恢复。操作日志可以分为回滚日志(undo log),重做日志(redo log)。回滚日志记录的是事务修改前的状态,重做日志记录的是事务修改之后的状态。
3.1 操作日志
为了数据库数据的一致性,数据库操作需要持久化到磁盘,如果每次操作都更新磁盘上的数据,系统性能会较差。操作日志上面记录的就是每个数据库操作,并在内存中执行这些操作,内存中的数据定时刷新到磁盘,就可以实现随机写请求转化为顺序写请求。
3.2 重做日志
使用 REDO 日志进行故障恢复,必须确保,在修改内存中的数据之前,把这一修改相关的操作日志刷新到磁盘上。这么做的原因在于,假设是先修改内存数据,如果在完成内存修改和写入日志之间发生故障,那么最近的修改操作没有办法通过 REDO 日志恢复,用户可能读取到修改后的结果,出现不一致的情况。
3.3 成组提交
之前说过,数据库操作需要先写入操作日志,但是如果每次操作都立即将操作日志刷人磁盘,系统性能会降低。因此可以先将 REDO 日志储存在缓冲区,定期刷入磁盘。但这样做,可能会丢失最后一部分数据库操作。
3.4 检查点
当内存不足,或者 REDO 日志的大小达到上限时,需要将内存中修改后的数据刷新到磁盘上,这种技术就是 checkpoint(检查点)技术。同时系统会加入 checkpoint 时刻,以后的故障恢复只需要回放 checkpoint 时刻之后的 REDO 日志。
第三章 分布式系统
1、基本概念
1.1 “超时”
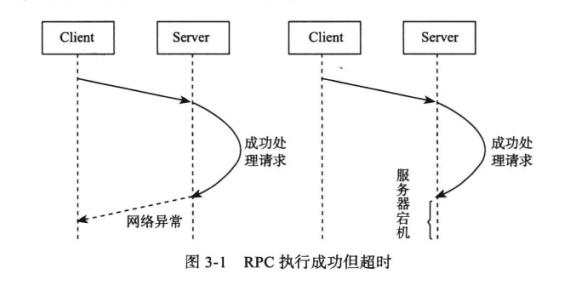
在分布式系统中,如果一个节点发起 RPC 调用,RPC 执行结果有三种:“成功”,“失败”,“超时”。当出现超时状态时,不能简单的认为 RPC 操作失败,只能通过不断读取之前操作的状态来验证 RPC 操作是否成功。当然,可以将系统设计为幂等性。
1.2 一致性
保证多个副本之间的一致性是分布式系统的核心。例如有 A,B,C 同时操作存储系统,可以将一致性大致分别三种:
- 强一致性,A 写入值,后续 A,B,C 读取的都是最新值。
- 弱一致性,A 写入值,不能保证后续 A,B,C 读取的都是最新值。
- 最终一致性,A 写入值,在后续没有更新该值,则后续 A,B,C 读取的都是最新值。有一个“不一致窗口”的概念。
2、数据分布
分布式系统不同于传统的单机系统,分布式系统能够将数据分布到多个节点,在多个节点间实现负载均衡。以下介绍的是数据分布的两种方式。
2.1 哈希分布
哈希分布就是根据数据的某一特征计算哈希值,哈希值与服务器有映射关系,以此实现数据的分布。哈希分布的优劣取决于散列函数的特征,容易出现“数据倾斜”的问题。而且,当有服务器上线或者下线时,哈希映射会被打乱,会带来大量的数据迁移。
一致性哈希可以避免集群扩容造成的大量数据迁移问题。其思想是:系统中的每个节点都分配一个 token,这些 token 构成哈希环。储存数据时,先计算数据的哈希值,然后存放到顺时针第一个大于或者等于该哈希值的节点。这样在增加、删除节点时,只会影响到哈希环中相邻的节点。一致性哈希可以采用虚拟节点的发放来实现负载均衡。

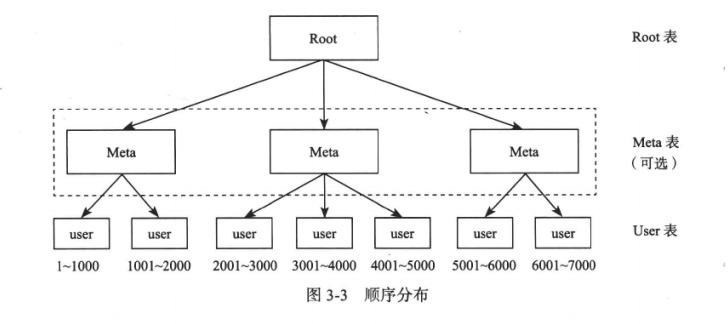
2.2 顺序分布
哈希分布实现数据分布时,不能支持顺序扫描。顺序分布可以提供连续的范围扫描,一般做法是将大表顺序分为连续的范围,每个范围一个子表。Bigtable 系统将索引分为两级,Root 表和元数据 Meta 表,由 Meta 表维护 User 表的位置信息, Root 表维护 Meta 表的位置信息。
3、复制
3.1 复制的概念
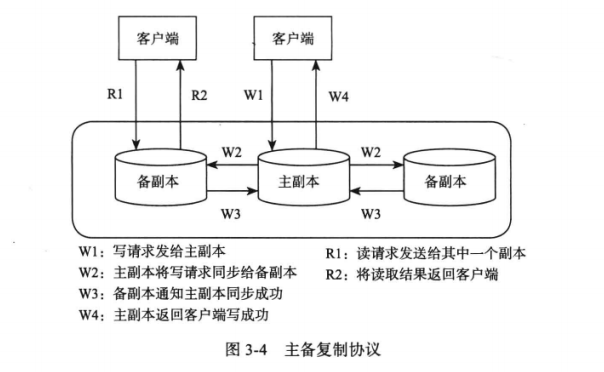
在分布式系统中,同一份数据有多个副本,其中一个副本为主副本,其他为备副本。复制时,由主副本将数据复制到备份副本。复制协议可以分为强同步复制和异步复制。
强同步复制要求主备成功后才可以返回成功,可以保证强一致性,但是,复制时是阻塞写操作,系统可用性较差。
异步复制就是主副本不需要等待备副本的回应,只需要本地修改成功就可以返回成功。
上述两种复制协议都是主副本将数据发送给其他副本,当主副本出现故障时,需要选择新的主副本。经典的选举协议为 Paxos 协议。
3.2 一致性和可用性
CAP 理论就是:一致性(Consistency),可用性(Availability),分区可容忍性(Tolerance of network Partition)三者不能同时满足。
分区可容忍性指的是在机器故障、网站故障等异常情况下仍然满足一致性和可用性。
设计存储系统时需要在一致性和可用性之间权衡。如果采用强同步复制,保证系统的一致性,当主备副本之间出现故障时,写操作被阻塞,系统的可用性将无法满足。如果采用异步复制,保证了可用性,但无法做到一致性。
Oracle 数据库的 DataGuard 复制组件有三种模式,可以借鉴:
- 最大保护模式:即强同步模式
- 最大性能模式:即异步复制模式
- 最大可用模式:正常情况是最大保护模式,主备间出现故障时,切换为最大性能模式。
4、容错
4.1 故障检测
故障检测可以使用心跳的方式来做,但并不能保证机器一定出现了故障,可能是机器 A 和机器 B 之间的网络发生问题。
通常使用租约机制来进行故障检测。租约机制就是:机器 A 向 机器 B 发放租约,机器 B 在持有租约的有效期内才允许提供服务,否则主动停止服务,机器 B 可以再租约快要到期的时候向机器 A 重新申请租约。
4.2 故障恢复
总控节点检测到工作机器出现故障时,需要将服务迁移到其他工作机节点。总控节点本身可有可能出现故障,也需要将自身状态实行同步到备机。

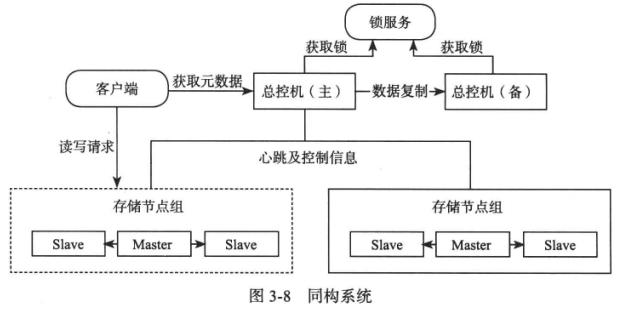
分布式存储系统的总控节点只需要维护数据的位置信息,通常不会成为瓶颈。如果成为瓶颈,可以采用两级结构:

5、可扩展性
5.1 数据库扩容
数据库扩容的手段有:
- 通过主从复制提高系统的读写能力
- 通过垂直拆分和水平拆分将数据分布到多个节点

传统的数据库为同构系统,在扩容上不够灵活。同一组内的节点存储相同的数据,在增加副本时需要迁移的数据量太大。
 、
、
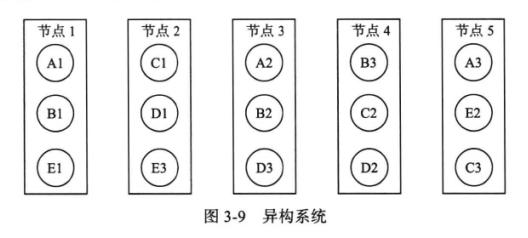
异构系统将数据划分为很多大小接近的分片,每个分片的多个副本可以分布 到集群中的任何一个存储节点。如果某个节点发生故障,原有的服务将由整个集群而不 是某几个固定的存储节点来恢复。如图3-9所示,系统中有五个分片(A, B, C, D, E),每个分片包含三个副本, 如分片A的三个副本分别为Al, A2以及A3。假设节点1发生永久性故障,那么可以 从剩余的节点中任意选择健康的节点来增加A, B以及E的副本。由于整个集群都参与 到节点1的故障恢复过程,故障恢复时间很短,而且集群规模越大,优势就会越明显。
6、分布式协议
6.1 两阶段提交协议
两阶段提交协议(2PC)用来保证跨节点操作的原子性。该协议中,将系统节点分为:协调者和事务参与者。正常执行过程如下:
- 请求阶段,协调者通知事务参与者准备提交(事务参与者本地执行成功)或者取消(事务参与者本地执行失败)事务。
- 提交阶段,协调者根据请求阶段的结果进行决策:提交或者取消。只有所有事务参与者都同意提交时,协调者才会通知所有的参与者提交事务,否则取消事务。
两阶段提交协议可能面临的故障:
- 事务参与者发生故障。给事务设置超时时间,达到超时时间后整个事务失败。
- 协调者发生故障。可以备用协调者。
两阶段提交协议是阻塞协议,执行期间要锁住其他更新,且不能容错。大多数分布式存储系统都对之避而远之。
6.2 Paxos 协议
Paxos 协议用来解决多个节点之间的一致性问题。当主节点出现故障时,Paxos 协议可以在多个备节点中选举出唯一的主节点。
Paxos 协议的两种用法:
- 用它来实现全局的锁服务或者命名和配置服务
- 用它来将用户数据复制到多个数据中心
paxos 协议怎么做的???待填坑!!!
6.3 Paxos 与 2PC
2PC 可以和 Paxos 协议结合起来,通过 2PC 保证多个数据分片上的操作的原子性,通过 Paxos 协议实现同一数据分片的多个副本之间的一致性。另外,通过 Paxos 协议解决 2PC 协议中协调者出现故障的问题。当 2PC 协议中的协调者出现故障时,通过 Paxos 协议选举出新的协调者继续提供服务。