本博客转载自https://blog.csdn.net/yeler082/article/details/83278371
在caffe参数配置文件当中遇到这么一段:
net: "models/h2_train.prototxt" #模型训练网络配置文件
base_lr: 1e-6 #基础学习率
lr_policy: "step" #学习率变化策略
gamma: 0.1 #grama值,用于学习率变化
iter_size: 10
stepsize: 10000 #用于学习率调整的步长,与lr_policy为step的情况同用
display: 10 #训练过程每10次打印一次
max_iter: 40000 #指定最大的迭代次数
momentum: 0.9 #动量值,一般设定为0.9
weight_decay: 0.0002 #用于正则化的权重衰减
snapshot: 2000 #每2000次得到一次快照,用于断点接续训练
snapshot_prefix: "snapshot/h2feat11-skl" #快照存储路径
solver_mode: GPU #训练采用GPU模式
这里的iter_size有点迷糊。这里给出解答:
iter_size是caffe的solver.prototxt中的一个重要参数,很多人在用caffe训练模型的时候,只关注到了网络中定义的batch_size, 却不知iter_size和batch_size有着很大的联系。
1. iter_size是什么?
对于caffe来说,solver.prototxt中的iter_size的确是一个计算batch_size的重要参数,caffe在训练过程中的batch_size (真正的batch_size) = iter_size X batch_size (model中定义的batch_size)。这一点好像在其他的框架(如pytorch)中是没有看到的。那这样做有什么好处呢? 我觉得可以从两方面来看,
(1) 硬件问题。正如其他人的回答,如果batch_size太大有可能会因为GPU显存的制约而无法训练。
(2) 数据问题。有时候我们输入的数据难免是任意尺寸,但又不想将其Resize或者Crop到同一尺寸,所以我们在model中的batch_size只能为1。(这个问题可以从faster RCNN(侧重end-to-end)中看出来,faster RCNN的任意实现方式都将batch_size设为了1。 也有人调整batch_size为4,但方法是将输入数据Resize到了同一尺寸,而Resize本身毕竟还是有损失的。具体可参见https://github.com/ice-pice/py-faster-rcnn)
由此,针对这两个问题,caffe的iter_size确实是一种折中的方法。通过将iter_size个batch(model中的定义)集合起来,进行一次优化,增大了batch_size,也解决了任意输入尺寸的问题。
2. iter_size 如何工作?
iter_size可以扩大batch,那到底是怎么扩大的呢?又是如何影响参数的更新呢?
首先,我们对几个名词重新进行统一,以方便理解
- batch_size: 指的是网络在训练过程中,经过多少数据更新一次权重,或者说经过多少数据优化一次网络。而将batch_size个数据构成的输入称为batch(或mini-batch)
- sub_batch_size: 指的是caffe在定义model.prototxt时设定的batch_size,这里我们为了上面提到的mini-batch做区分,所以将由sub_batch_size个数据构成的输入称为sub_batch
- iter_size: 指的是一个batch(mini-batch)包含的sub_batch的数量
通过上面的重新定义,我们可以近一步说明三者的关系为:
这与在问题一中的定义是一致的。那如何优化呢?
caffe在前向和反向的过程中是以sub_batch为单位的,而在优化过程中则是以batch(min-batch)为单位的。
首先,一个sub_batch的数据前向通过网络,计算损失,再通过反向传播,计算损失对各权重的梯度。虽然在这个过程中要进行反向传播,但参数不进行优化。
然后,将下一个sub_batch的数据也按照上面的方式,前向反向计算,直到iter_size个sub_batch都完成了上面的过程。
最后,当一个batch的数据都前反向计算后,准备进行优化。对于网络中的每一个要学习的参数,将每个sub_batch反向时对其计算的梯度进行累加,并除以iter_size,作为最终的梯度来更新该参数。至于更新的方法,则可以利用各种选定的优化方法进行优化,如SGD、Adam等。
通过上面的过程,我们能看到,是用iter_size个梯度的均值来更新具体的网络权重。那不是说要用loss的均值吗?caffe底层的代码solver.cpp中也提到了loss的均值,这里为什么说是梯度的均值呢? 这其实是一个极易混淆的问题,注意反向传播是每个sub_batch都要进行的,但优化是一个batch进行一次,如果强行采用一个batch的loss的均值去优化,必然会带来很大误差。所以,要仔细看源码,源码中的确是对梯度取得均值。而loss的均值是用来近一步做平滑处理,方便display的。一些源码的分析可以参考该博客http://alanse7en.github.io/caffedai-ma-jie-xi-4/ ,但是直接打打不开,大家也可以参见其百度快照。。。
所以我遇到的这个配置文件中令iter_size = 10。
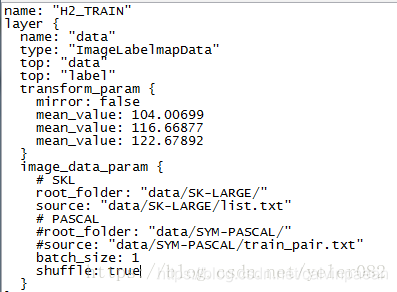
在训练的配置文件当中,又将batch_size设定为1;那么有
,意思是每次都用1张图片去训练,训练完10张更新一次参数,等同于10张图片一起训练。