版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_38358305/article/details/88643163
Batch_Size:
首先,batch_size来源于:小批量梯度下降(Mini-batch gradient descent)
梯度下降法是常用的参数更新方法,而小批量梯度下降是对于传统梯度下降法的优化。
定义:
Batch_size是每次喂给模型的样本数量。
Epoch_size是训练所有样本总的次数(即每个样本被训练的次数相当于iteration)。
1.批量梯度下降(BGD):一个epoch训练所有的样本后更新一遍梯度。
2.随机梯度下降(SGD):每训练一个样本,更新一遍梯度。
3.小批量梯度下降(Mini-batch gradient descent):把总的数据分为若干批次,每个批次更新一遍梯度。每个批次的大小即为batch_size。
首先抛出结论:
batch_size越大,速度越快,精度越低(相同训练轮数)。
Batch_size的调参:
- 当有足够算力时,选取batch size为32或更小一些。
- 算力不够时,在效率和泛化性之间做trade-off,尽量选择更小的batch size。
- 当模型训练到尾声,想更精细化地提高成绩(比如论文实验/比赛到最后),有一个有用的trick,就是设置batch size为1,即做纯SGD,慢慢把error磨低。
当然增大Batch_size会加快速度,但是变相地需要更多的Epoch(轮数)去达到需要的精度。
Trick:
以128大小为基准,往两个方向(乘除2倍)来比较最后的结果。
下表可供参考:
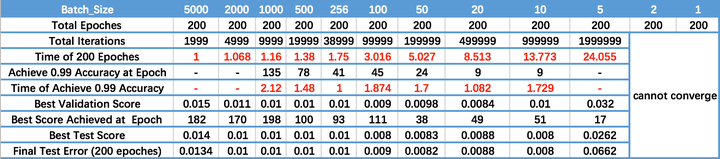
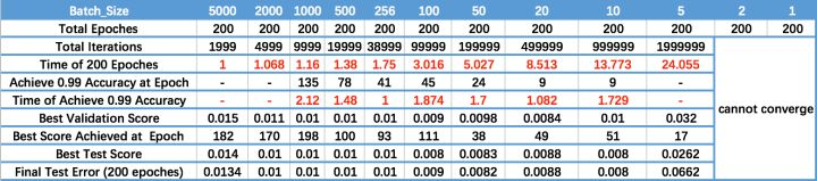
Epoch_Size:
对于Epoch大小的确定,牵扯到了防止过拟合的一个方法:提前停止训练。
随着epoch次数增加,神经网络中的权重的更新次数也增加,模型从欠拟合变得过拟合。
trick:
可以先设定一个固定的Epoch大小(100轮)
一般当模型的loss不再持续减小,且精度不在10轮内提升,就可以提前停止训练了。(设置条件来停止epoch)