代码这个博文分为3个部分,第一个部分为pytorch文档,主要是为了能够精确的分析项目代码。
1. pytorch
文章1主要是由pytorch实现手写数字识别MNIST,通过这个简单的例子我们就能学习到Pytorch的一些简单的利用。
在torchvision中提供了transforms用于帮我们对图片进行预处理和标准化。其中我们需要用到的有两个:ToTensor()和Normalize()。前者用于将图片转换成Tensor格式的数据,并且进行了标准化处理。后者用均值和标准偏差对张量图像进行归一化:给定均值: (M1,...,Mn) 和标准差: (S1,..,Sn) 用于 n 个通道, 该变换将标准化输入 torch.*Tensor 的每一个通道。而Compose函数可以将上述两个操作合并到一起执行。
# 数据预处理。transforms.ToTensor()将图片转换成PyTorch中处理的对象Tensor,并且进行标准化(数据在0~1之间)
# transforms.Normalize()做归一化。它进行了减均值,再除以标准差。两个参数分别是均值和标准差
# transforms.Compose()函数则是将各种预处理的操作组合到了一起
data_tf = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])])
PyTorch提供了一些常用数据集,所以我们定义数据集下载器如下:
# 数据集的下载器
train_dataset = datasets.MNIST(
root='./data', train=True, transform=data_tf, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_tf)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
然后选择相应的神经网路模型来进行训练和测试,我们这里定义的神经网络输入层为28*28,因为我们处理过的图片像素为28*28,两个隐层分别为300和100,输出层为10,因为我们识别0~9十个数字,需要分为十类。损失函数和优化器这里采用了交叉熵和梯度下降。
# 选择模型
model = net.simpleNet(28 * 28, 300, 100, 10)
# model = net.Activation_Net(28 * 28, 300, 100, 10)
# model = net.Batch_Net(28 * 28, 300, 100, 10)
if torch.cuda.is_available():
model = model.cuda()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
下面是训练阶段:
# 训练模型
epoch = 0
for data in train_loader:
img, label = data
img = img.view(img.size(0), -1)
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
else:
img = Variable(img)
label = Variable(label)
out = model(img)
loss = criterion(out, label)
print_loss = loss.data.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch+=1
if epoch%50 == 0:
print('epoch: {}, loss: {:.4}'.format(epoch, loss.data.item()))
然后测试一下我们的模型:
# 模型评估
model.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:
img, label = data
img = img.view(img.size(0), -1)
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
out = model(img)
loss = criterion(out, label)
eval_loss += loss.data.item()*label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(
eval_loss / (len(test_dataset)),
eval_acc / (len(test_dataset))
))
相信通过上面的简单的例子,大家一定会对pytorch有一个简单的理解。
2. openpose 论文代码分析,文章3给出了一个pytorch的代码,分析,但是我觉得还不够仔细,这里再对他进行下一步详细的分析。
import os
import re
import sys
import cv2
import math
import time
import scipy
import argparse
import matplotlib
from torch import np # Pytorch里可以直接加载numpy,但是官网文档里查不到
import pylab as plt
from joblib import Parallel, delayed
import util
import torch
import torch as T
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from collections import OrderedDict
from config_reader import config_reader
from scipy.ndimage.filters import gaussian_filter
#parser = argparse.ArgumentParser()
#parser.add_argument('--t7_file', required=True)
#parser.add_argument('--pth_file', required=True)
#args = parser.parse_args()
torch.set_num_threads(torch.get_num_threads())
weight_name = './model/pose_model.pth'
blocks = {}
'''
18个关节,pt19为背景
part_str = [nose, neck, Rsho, Relb, Rwri, Lsho, Lelb, Lwri, Rhip, Rkne, Rank, Lhip, Lkne, Lank, Leye, Reye, Lear, Rear, pt19]
'''
# find connection in the specified sequence, center 29 is in the position 15
# 18个关节对应19个关节链接(也就是肢体)
limbSeq = [[2,3], [2,6], [3,4], [4,5], [6,7], [7,8], [2,9], [9,10], \
[10,11], [2,12], [12,13], [13,14], [2,1], [1,15], [15,17], \
[1,16], [16,18], [3,17], [6,18]]
# the middle joints heatmap correpondence
# 肢体对应的PAF特征图(19-56共38张,每两张表示一个二维方向向量)
mapIdx = [[31,32], [39,40], [33,34], [35,36], [41,42], [43,44], [19,20], [21,22], \
[23,24], [25,26], [27,28], [29,30], [47,48], [49,50], [53,54], [51,52], \
[55,56], [37,38], [45,46]]
# visualize
colors = [[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0], \
[0, 255, 85], [0, 255, 170], [0, 255, 255], [0, 170, 255], [0, 85, 255], [0, 0, 255], [85, 0, 255], \
[170, 0, 255], [255, 0, 255], [255, 0, 170], [255, 0, 85]]
# 以下为构造网络部分,很好理解
block0 = [{'conv1_1':[3,64,3,1,1]},{'conv1_2':[64,64,3,1,1]},{'pool1_stage1':[2,2,0]},{'conv2_1':[64,128,3,1,1]},{'conv2_2':[128,128,3,1,1]},{'pool2_stage1':[2,2,0]},{'conv3_1':[128,256,3,1,1]},{'conv3_2':[256,256,3,1,1]},{'conv3_3':[256,256,3,1,1]},{'conv3_4':[256,256,3,1,1]},{'pool3_stage1':[2,2,0]},{'conv4_1':[256,512,3,1,1]},{'conv4_2':[512,512,3,1,1]},{'conv4_3_CPM':[512,256,3,1,1]},{'conv4_4_CPM':[256,128,3,1,1]}]
blocks['block1_1'] = [{'conv5_1_CPM_L1':[128,128,3,1,1]},{'conv5_2_CPM_L1':[128,128,3,1,1]},{'conv5_3_CPM_L1':[128,128,3,1,1]},{'conv5_4_CPM_L1':[128,512,1,1,0]},{'conv5_5_CPM_L1':[512,38,1,1,0]}]
blocks['block1_2'] = [{'conv5_1_CPM_L2':[128,128,3,1,1]},{'conv5_2_CPM_L2':[128,128,3,1,1]},{'conv5_3_CPM_L2':[128,128,3,1,1]},{'conv5_4_CPM_L2':[128,512,1,1,0]},{'conv5_5_CPM_L2':[512,19,1,1,0]}]
# 185 = 128 + 19 + 38
for i in range(2,7):
blocks['block%d_1'%i] = [{'Mconv1_stage%d_L1'%i:[185,128,7,1,3]},{'Mconv2_stage%d_L1'%i:[128,128,7,1,3]},{'Mconv3_stage%d_L1'%i:[128,128,7,1,3]},{'Mconv4_stage%d_L1'%i:[128,128,7,1,3]},
{'Mconv5_stage%d_L1'%i:[128,128,7,1,3]},{'Mconv6_stage%d_L1'%i:[128,128,1,1,0]},{'Mconv7_stage%d_L1'%i:[128,38,1,1,0]}]
blocks['block%d_2'%i] = [{'Mconv1_stage%d_L2'%i:[185,128,7,1,3]},{'Mconv2_stage%d_L2'%i:[128,128,7,1,3]},{'Mconv3_stage%d_L2'%i:[128,128,7,1,3]},{'Mconv4_stage%d_L2'%i:[128,128,7,1,3]},
{'Mconv5_stage%d_L2'%i:[128,128,7,1,3]},{'Mconv6_stage%d_L2'%i:[128,128,1,1,0]},{'Mconv7_stage%d_L2'%i:[128,19,1,1,0]}]
def make_layers(cfg_dict):
layers = []
for i in range(len(cfg_dict)-1):
one_ = cfg_dict[i]
for k,v in one_.iteritems():
if 'pool' in k:
layers += [nn.MaxPool2d(kernel_size=v[0], stride=v[1], padding=v[2] )]
else:
conv2d = nn.Conv2d(in_channels=v[0], out_channels=v[1], kernel_size=v[2], stride = v[3], padding=v[4])
layers += [conv2d, nn.ReLU(inplace=True)]
one_ = cfg_dict[-1].keys()
k = one_[0]
v = cfg_dict[-1][k]
conv2d = nn.Conv2d(in_channels=v[0], out_channels=v[1], kernel_size=v[2], stride = v[3], padding=v[4])
layers += [conv2d]
return nn.Sequential(*layers)
layers = []
for i in range(len(block0)):
one_ = block0[i]
for k,v in one_.iteritems():
if 'pool' in k:
layers += [nn.MaxPool2d(kernel_size=v[0], stride=v[1], padding=v[2] )]
else:
conv2d = nn.Conv2d(in_channels=v[0], out_channels=v[1], kernel_size=v[2], stride = v[3], padding=v[4])
layers += [conv2d, nn.ReLU(inplace=True)]
models = {}
models['block0']=nn.Sequential(*layers)
for k,v in blocks.iteritems():
models[k] = make_layers(v)
class pose_model(nn.Module):
def __init__(self,model_dict,transform_input=False):
super(pose_model, self).__init__()
self.model0 = model_dict['block0']
self.model1_1 = model_dict['block1_1']
self.model2_1 = model_dict['block2_1']
self.model3_1 = model_dict['block3_1']
self.model4_1 = model_dict['block4_1']
self.model5_1 = model_dict['block5_1']
self.model6_1 = model_dict['block6_1']
self.model1_2 = model_dict['block1_2']
self.model2_2 = model_dict['block2_2']
self.model3_2 = model_dict['block3_2']
self.model4_2 = model_dict['block4_2']
self.model5_2 = model_dict['block5_2']
self.model6_2 = model_dict['block6_2']
def forward(self, x):
out1 = self.model0(x)
out1_1 = self.model1_1(out1)
out1_2 = self.model1_2(out1)
out2 = torch.cat([out1_1,out1_2,out1],1)
out2_1 = self.model2_1(out2)
out2_2 = self.model2_2(out2)
out3 = torch.cat([out2_1,out2_2,out1],1)
out3_1 = self.model3_1(out3)
out3_2 = self.model3_2(out3)
out4 = torch.cat([out3_1,out3_2,out1],1)
out4_1 = self.model4_1(out4)
out4_2 = self.model4_2(out4)
out5 = torch.cat([out4_1,out4_2,out1],1)
out5_1 = self.model5_1(out5)
out5_2 = self.model5_2(out5)
out6 = torch.cat([out5_1,out5_2,out1],1)
out6_1 = self.model6_1(out6)
out6_2 = self.model6_2(out6)
return out6_1,out6_2 #分别输入38(PAF),19(关节+背景)维置信图
model = pose_model(models)
model.load_state_dict(torch.load(weight_name))
model.cuda()
model.float()
# 因为这是demo代码,所以是直接用训练好的模型,把Model调整为eval模式
model.eval()
param_, model_ = config_reader()
#torch.nn.functional.pad(img pad, mode='constant', value=model_['padValue'])
tic = time.time()
test_image = './sample_image/ski.jpg'
#test_image = 'a.jpg'
oriImg = cv2.imread(test_image) # B,G,R order
imageToTest = Variable(T.transpose(T.transpose(T.unsqueeze(torch.from_numpy(oriImg).float(),0),2,3),1,2),volatile=True).cuda()
#multiplier是用四种不同尺度的图像去作为输入,有利于学习关节的空间关系
multiplier = [x * model_['boxsize'] / oriImg.shape[0] for x in param_['scale_search']]
heatmap_avg = torch.zeros((len(multiplier),19,oriImg.shape[0], oriImg.shape[1])).cuda()
paf_avg = torch.zeros((len(multiplier),38,oriImg.shape[0], oriImg.shape[1])).cuda()
#print heatmap_avg.size()
toc =time.time()
print 'time is %.5f'%(toc-tic)
tic = time.time()
#对不同尺度的图进行处理
for m in range(len(multiplier)):
scale = multiplier[m]
h = int(oriImg.shape[0]*scale)
w = int(oriImg.shape[1]*scale)
pad_h = 0 if (h%model_['stride']==0) else model_['stride'] - (h % model_['stride'])
pad_w = 0 if (w%model_['stride']==0) else model_['stride'] - (w % model_['stride'])
new_h = h+pad_h
new_w = w+pad_w
imageToTest = cv2.resize(oriImg, (0,0), fx=scale, fy=scale, interpolation=cv2.INTER_CUBIC) # 原图进行scale变换
imageToTest_padded, pad = util.padRightDownCorner(imageToTest, model_['stride'], model_['padValue'])
imageToTest_padded = np.transpose(np.float32(imageToTest_padded[:,:,:,np.newaxis]), (3,2,0,1))/256 - 0.5
feed = Variable(T.from_numpy(imageToTest_padded)).cuda()
output1,output2 = model(feed)
print output1.size()
print output2.size()
#利用上采样将特征图变换成原图大小
heatmap = nn.UpsamplingBilinear2d((oriImg.shape[0], oriImg.shape[1])).cuda()(output2)
paf = nn.UpsamplingBilinear2d((oriImg.shape[0], oriImg.shape[1])).cuda()(output1)
heatmap_avg[m] = heatmap[0].data
paf_avg[m] = paf[0].data
toc =time.time()
print 'time is %.5f'%(toc-tic)
tic = time.time()
heatmap_avg = T.transpose(T.transpose(T.squeeze(T.mean(heatmap_avg, 0)),0,1),1,2).cuda()
paf_avg = T.transpose(T.transpose(T.squeeze(T.mean(paf_avg, 0)),0,1),1,2).cuda()
heatmap_avg=heatmap_avg.cpu().numpy()
paf_avg = paf_avg.cpu().numpy()
toc =time.time()
print 'time is %.5f'%(toc-tic)
tic = time.time()
#以下是根据预测的19张关节特征图寻找关节点对应的位置(类似于图像分割)
all_peaks = []
peak_counter = 0
for part in range(18):
map_ori = heatmap_avg[:,:,part]
map = gaussian_filter(map_ori, sigma=3)
map_left = np.zeros(map.shape)
map_left[1:,:] = map[:-1,:]
map_right = np.zeros(map.shape)
map_right[:-1,:] = map[1:,:]
map_up = np.zeros(map.shape)
map_up[:,1:] = map[:,:-1]
map_down = np.zeros(map.shape)
map_down[:,:-1] = map[:,1:]
#寻找局部极值
peaks_binary = np.logical_and.reduce((map>=map_left, map>=map_right, map>=map_up, map>=map_down, map > param_['thre1']))
# peaks_binary = T.eq(
# peaks = zip(T.nonzero(peaks_binary)[0],T.nonzero(peaks_binary)[0])
peaks = zip(np.nonzero(peaks_binary)[1], np.nonzero(peaks_binary)[0]) # note reverse
peaks_with_score = [x + (map_ori[x[1],x[0]],) for x in peaks]
id = range(peak_counter, peak_counter + len(peaks))
peaks_with_score_and_id = [peaks_with_score[i] + (id[i],) for i in range(len(id))]
all_peaks.append(peaks_with_score_and_id) # [[y, x, peak_score, id)],...]
peak_counter += len(peaks)
#以下是根据预测出的38张paf特征图来预测关节链接(肢体)
connection_all = []
special_k = []
mid_num = 10
#计算线性积分(对应论文part assosiation部分和Fig 6)
for k in range(len(mapIdx)):
score_mid = paf_avg[:,:,[x-19 for x in mapIdx[k]]]# channel为2的paf_avg,表示PAF向量
candA = all_peaks[limbSeq[k][0]-1]#第k个limb中左关节点的候选集合A(不同人的关节点)
candB = all_peaks[limbSeq[k][1]-1]#第k个limb中右关节点的候选集合B(不同人的关节点)
nA = len(candA)
nB = len(candB)
indexA, indexB = limbSeq[k]
if(nA != 0 and nB != 0):#有候选开始连接
connection_candidate = []
#连接所有检测出的关节点(nA * nB)
for i in range(nA):
for j in range(nB):
#计算单位向量
vec = np.subtract(candB[j][:2], candA[i][:2])
norm = math.sqrt(vec[0]*vec[0] + vec[1]*vec[1])
vec = np.divide(vec, norm)
#在A[i],B[j]连线上取mid_num个采样点
startend = zip(np.linspace(candA[i][0], candB[j][0], num=mid_num), \
np.linspace(candA[i][1], candB[j][1], num=mid_num))
#根据特征图取采样点的paf向量
vec_x = np.array([score_mid[int(round(startend[I][1])), int(round(startend[I][0])), 0] \
for I in range(len(startend))])
vec_y = np.array([score_mid[int(round(startend[I][1])), int(round(startend[I][0])), 1] \
for I in range(len(startend))])
#计算余弦值,用来衡量相似度
score_midpts = np.multiply(vec_x, vec[0]) + np.multiply(vec_y, vec[1])
score_with_dist_prior = sum(score_midpts)/len(score_midpts) + min(0.5*oriImg.shape[0]/norm-1, 0)
#评判连接有效的两个标准
criterion1 = len(np.nonzero(score_midpts > param_['thre2'])[0]) > 0.8 * len(score_midpts)
criterion2 = score_with_dist_prior > 0
if criterion1 and criterion2:
connection_candidate.append([i, j, score_with_dist_prior, score_with_dist_prior+candA[i][2]+candB[j][2]])
#对所有连接进行排序
connection_candidate = sorted(connection_candidate, key=lambda x: x[2], reverse=True)
connection = np.zeros((0,5))
#留下对于每个关节点得分最高的连接,连接数保证不大于nA,nB的最小值
for c in range(len(connection_candidate)):
i,j,s = connection_candidate[c][0:3]
if(i not in connection[:,3] and j not in connection[:,4]):
connection = np.vstack([connection, [candA[i][3], candB[j][3], s, i, j]]) # A_id, B_id, score, i, j
if(len(connection) >= min(nA, nB)):
break
connection_all.append(connection)
else:
special_k.append(k)
connection_all.append([])
'''
function: 将检测的关节点连接拼成人
subset: last number in each row is the total parts number of that person
subset: the second last number in each row is the score of the overall configuration
candidate: 候选关节点
connection_all: 候选limb
ps: 这段代码要先看not found的状态,生成subset
'''
subset = -1 * np.ones((0, 20))
candidate = np.array([item for sublist in all_peaks for item in sublist]# 一个id的(y,x,score,id)(关节点)
for k in range(len(mapIdx)):
if k not in special_k:
partAs = connection_all[k][:,0]# 第k个limb,左端点的候选id集合
partBs = connection_all[k][:,1]# 第k个limb,右端点的候选id集合
indexA, indexB = np.array(limbSeq[k]) - 1# 关节点index
for i in range(len(connection_all[k])): #= 1:size(temp,1)
found = 0
subset_idx = [-1, -1]
for j in range(len(subset)): #1:size(subset,1):遍历每个人(subset)
if subset[j][indexA] == partAs[i] or subset[j][indexB] == partBs[i]:
subset_idx[found] = j
found += 1
# 关节点在subset里只出现一次(比如人的肩肘已经连接,此时要连接肘腕,而肘就是公共点),这构造新连接,此subset的关节数+1
if found == 1:
j = subset_idx[0]
if(subset[j][indexB] != partBs[i]):
subset[j][indexB] = partBs[i]
subset[j][-1] += 1
subset[j][-2] += candidate[partBs[i].astype(int), 2] + connection_all[k][i][2]
# 对一个新连接来说,左右端点都出现,说明左右端点间还没有连接起来。
elif found == 2: # if found 2 and disjoint, merge them
j1, j2 = subset_idx
print "found = 2"
membership = ((subset[j1]>=0).astype(int) + (subset[j2]>=0).astype(int))[:-2]
# 如果两个人的相同关节点没有在各自的subset中都连成limb,那么合并两个subset构成一个人,关节数为两人各自关节数相加。
if len(np.nonzero(membership == 2)[0]) == 0: #merge
subset[j1][:-2] += (subset[j2][:-2] + 1)#+1的原因是初始值为-1
subset[j1][-2:] += subset[j2][-2:]
subset[j1][-2] += connection_all[k][i][2]
subset = np.delete(subset, j2, 0)
# 以下这段没看出具体的作用
else: # as like found == 1
subset[j1][indexB] = partBs[i]
subset[j1][-1] += 1
subset[j1][-2] += candidate[partBs[i].astype(int), 2] + connection_all[k][i][2]
# 每出现新的关节连接组合,则说明多了一个人,于是加一个subset,且关节数+2
# if find no partA in the subset, create a new subset
elif not found and k < 17:
row = -1 * np.ones(20)
row[indexA] = partAs[i]
row[indexB] = partBs[i]
row[-1] = 2
row[-2] = sum(candidate[connection_all[k][i,:2].astype(int), 2]) + connection_all[k][i][2]
subset = np.vstack([subset, row])
# 设置评判条件,不满足条件则不可称为人(删除subset)
# delete some rows of subset which has few parts occur
deleteIdx = [];
for i in range(len(subset)):
if subset[i][-1] < 4 or subset[i][-2]/subset[i][-1] < 0.4:
deleteIdx.append(i)
subset = np.delete(subset, deleteIdx, axis=0)
canvas = cv2.imread(test_image) # B,G,R order
for i in range(18):
for j in range(len(all_peaks[i])):
cv2.circle(canvas, all_peaks[i][j][0:2], 4, colors[i], thickness=-1)
stickwidth = 4
# 关节及肢体显示
for i in range(17):
for n in range(len(subset)):
index = subset[n][np.array(limbSeq[i])-1]
if -1 in index:
continue
cur_canvas = canvas.copy()
Y = candidate[index.astype(int), 0]
X = candidate[index.astype(int), 1]
mX = np.mean(X)
mY = np.mean(Y)
length = ((X[0] - X[1]) ** 2 + (Y[0] - Y[1]) ** 2) ** 0.5
angle = math.degrees(math.atan2(X[0] - X[1], Y[0] - Y[1]))
polygon = cv2.ellipse2Poly((int(mY),int(mX)), (int(length/2), stickwidth), int(angle), 0, 360, 1)
cv2.fillConvexPoly(cur_canvas, polygon, colors[i])
canvas = cv2.addWeighted(canvas, 0.4, cur_canvas, 0.6, 0)
#Parallel(n_jobs=1)(delayed(handle_one)(i) for i in range(18))
toc =time.time()
print 'time is %.5f'%(toc-tic)
cv2.imwrite('result.png',canvas)
我们从中慢慢来分析网络结构模型图:
其实整个网络模型包括VGG19+openpose模型部分,首先我们老分析VGG19,输入为224×224,

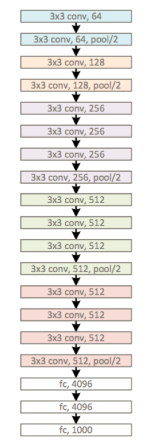
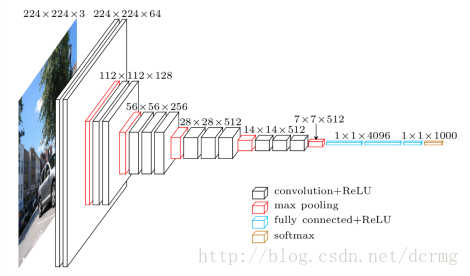
在这里 补充Ksize,padding,stride的相关知识,图像大小为W*H,ksiz为k_h*k_w,则经过卷积之后的大为n_h =( H-k_h)/ h, 在 H 方向的stride为 h, 在W方向 的stride为 w。最后一个参数就是padding
在矩阵每一行的上方需要添加的像素数为:
pad_need_H/2 取整 在矩阵每一行的下方需要添加的像素数为pad_need_H - pad_need_H/2
在这里继续补充一下,卷积神经网络的技术公式,我觉得最重要的是输出维度大大小就是卷积核的个数。
参考文章:
1. https://blog.csdn.net/out_of_memory_error/article/details/81434907
2. https://blog.csdn.net/out_of_memory_error/article/details/81414986