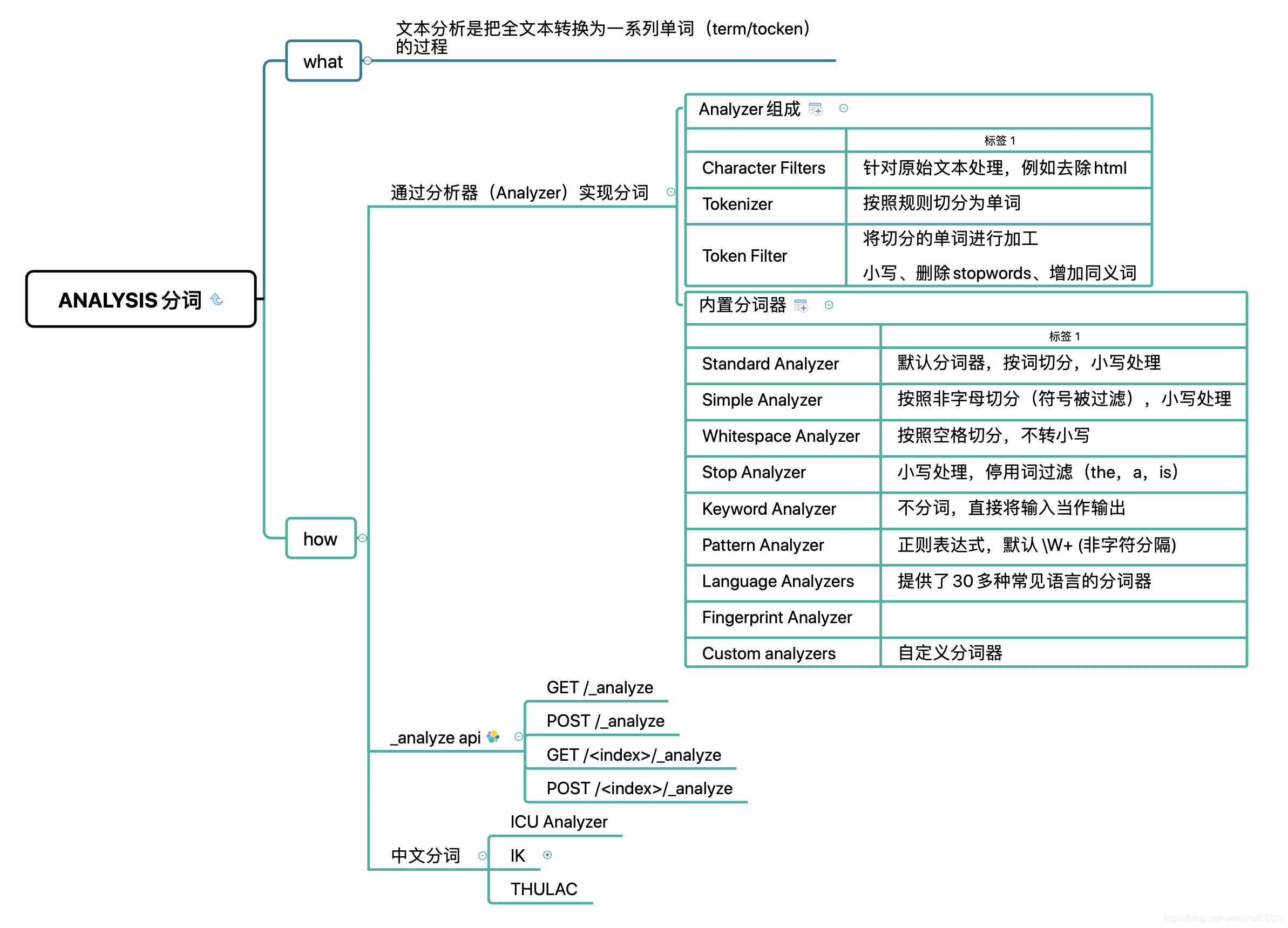
Analyzer 的组成
分词器是专门处理分词的组件,Analyzer 由三部分组成
- Character Filters - 针对原始文本处理,例如去除 html
- Tokenizer - 按照规则切分为单词
- Token Filter - 将切分的单词进行加工,小写,删除 stopwords,增加同义词
Elasticsearch 内置分析器
| 分析器 | 作用 |
|---|---|
| Standard Analyzer | 默认分词器,按词切分,小写处理 |
| Simple Analyzer | 按照非字母切分(符号被过滤),小写处理 |
| Whitespace Analyzer | 按照空格切分,不转小写 |
| Stop Analyzer | 小写处理,停用词过滤(the,a,is) |
| Keyword Analyzer | 不分词,直接将输入当作输出 |
| Pattern Analyzer | 正则表达式,默认 \W+ (非字符分隔) |
| Language Analyzers | 提供了30多种常见语言的分词器 |
| Fingerprint Analyzer | |
| Custom analyzers | 自定义分词器 |
中文分词
中文分词的难点
中文句子,切分成一个一个词(不是一个个字)。英文中,单词有自然的空格作为分隔。一句中文,在不同的上下文,可以有不同的理解:
这个苹果,不大好吃
这个苹果,不大,好吃!
一些例子他说的确实在理
这事的确定不下来
开源的中文分析器
- ICU Analyzer - 提供了Unicode支持,可以更好地支持亚洲语言
- IK Analyzer - 开源的、好用的中文分析器
- THULAC - 清华大学主导的中文分析器
_analyzer API
-
直接指定 Analyzer 进行测试
-
指定索引的字段进行测试
-
自定义分词器进行测试
GET _analyze 可以获取分词结果,通过analyzer可以指定分词器。
GET _analyze
{
"analyzer": "standard",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
GET _analyze
{
"analyzer": "simple",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
GET _analyze
{
"analyzer": "stop",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
安装中文分词器
POST _analyze
{
"analyzer": "icu_analyzer",
"text": "他说的确实在理”"
}
POST _analyze
{
"analyzer": "standard",
"text": "他说的确实在理”"
}
POST _analyze
{
"analyzer": "icu_analyzer",
"text": "这个苹果不大好吃"
}
POST books/_analyze
{
"field":"title",
"text":"Mastering Elasticsearch"
}
POST /_analyze
{
"tokenizer":"standard",
"filter":["lowercase"],
"text":"Mastering Elasticsearch"
}
