前言
互联网技术和大数据技术的迅猛发展正在时刻改变我们的生活,视频网站、资讯app、电商网站对于推荐系统而言,每天都有大量的活跃用户在不断的产生海量的用户行为,同时,每天又都产生大量的新增PGC或者UGC内容(如小说、资讯文章、短视频等)。
从推荐系统的角度来看,系统每时每刻都面临大量的新旧用户、新旧物品和大量的用户行为数据,对于用户,我们需要对要用户进行建模,去刻画用户的肖像和兴趣,然而我们常常面对的情况是用户的行为是稀疏的,而且可能存在比例不一的新用户,如何给新用户推荐,是推荐系统中的一个著名问题,即冷启动问题,给新用户展示哪些item决定了用户的第一感和体验;同时在推荐过程中,我们需要考虑给新item展示的机会,也能也需要给一个喜欢科幻电影的user推荐一些非科幻类型的电影,而这就是推荐系统中另外一个问题,即探索和利用的问题。
冷启动和EE问题
冷启动问题
推荐系统需要根据历史的用户行为和兴趣偏好预测用户未来的行为和兴趣,因此历史用户行为某种程度上成为推荐推荐的重要先决条件。实际过程中,我们面对大量的新用户,这些用户我们并不知道他们的profile,对于这些用户,常用的冷启动的算法包括根据已有的个人静态信息(年龄、性别、地理位置、移动设备型号等)为用户进行推荐。然而实际情况下,我们很难在系统中直接获取这些用户信息。给新用户推荐的item,由于成本较高(用户不感兴趣就再也不来了),我们需要保证item要足够热门,要保证足够的多样性,同时尽量保证可区分。
与用户的冷启动相对应的,则是item的冷启动,当一个新物品加入站内,如何快速的展现的用户。对于CF算法来说,无论是基于领域还是基于模型,如果想要这个新物品被推荐出来,显然我们需要用户对这个物品的行为。特别是在某些场景下,推荐列表是给用户展示的唯一列表,那么显而易见,只能在推荐列表中尝试给用户推荐新物品。
一个最简单的做法就是在推荐列表中随机给用户展示新物品,但是这样显然不太个性化,一个较好的做法是将新物品推荐给曾经喜欢过与新物品相似的物品的用户。由于新item没有用户行为,因此物品相似度只能从item自身出发,包括根据item的内容信息挖掘出item的向量表示,通过向量相似度来刻画物品相似度,还可以利用topic model挖掘出item的主题分布等等。
探索利用问题
推荐系统需要考虑对用户兴趣的不断探索和细化,同时也需要尽可能的扩大展示物品的多样性和宽度。比如展示物品的场景只有推荐列表,同时我们需要尽可能的优化的ctr,那么给冷启动用户我们该如何选择物品,如何快速的探测出用户的兴趣。比较简单的方式我们可以可以根据ctr排序,给冷启动用户推荐最热门点击率最高的物品,给足球迷推荐点击率最高的足球相关物品,显然这样做会保证我们推荐结果的ctr会比较高,但是这样做会减少我们推荐结果的覆盖率,降低推荐结果的多样性,以致于推荐物品候选集也会收敛,甚至出现反复推荐。而这也就是我们需要不断探索用户兴趣,扩大推荐结果多样性的原因。
简单来看这其实是一个选择问题,即探索(exploration)和利用(exploitation)的平衡问题。接下来本文接下来将详述EE问题和某些已有算法。
多臂老虎机模型和UCB算法
当你走进一家赌场,面对20个一模一样的老虎机,你并不知道它们吐钱的概率,假设你的成本是1000元,每摇一次的成本是2元,那么你在总共500次摇臂的机会下,该如何最大化你的收益呢?这就是多臂老虎机问题(Multi-armed bandit problem, K-armed bandit problem,MAB)。
一个简单的做法就是每台老虎机我们都摇10次,余下的300次都选择成功率最高的那台。但是显然我们耗费了200次机会来探索,而且我们仍然无法保证实验成功率最高的那台老虎机就是真实成功率最高的。大家也可以猜到,如果我们有足够多的探索机会,那么我们几乎可以选择出成功率最高的老虎机。很遗憾,我们没有足够的探索机会,对应到我们的推荐问题中就是任何的用户展示pv都是珍贵的,况且实际情况的“老虎机”远远不止20台,而且还存在不断新加入的情况,这就导致获取每个item收益率的成本太大。
我们使用累计遗憾(collect regret)来衡量策略的优劣:
t表示当前轮数,
解决bandit问题的算法众多,一般分为基于semi-uniform的策略、probability matching
策略、pricing策略等。这里只列举若干个策略,具体大家可以参考。
Epsilon-greedy策略:每次试验都以
Epsilon-first策略:该策略探索和利用交叉选择,总试验次数为N,探索次数为
Epsilon-decreasing策略:与Epsilon-greedy策略近似,不同地方在于
UCB(Upper Confidence Bound)算法
在推荐系统中,通常量化一个物品的收益率(或者说点击率)是使用
显然是不可能的。而这就是统计学中的置信度问题,计算点击率的置信区间的方法也有很多,比如威尔逊置信空间。UCB算法步骤包括:首先对所有item的尝试一下,然后每次选择以下值最大的那个item:
其中
这个公式表明随着每个物品试验次数的增加,其置信区间就越窄,收益概率就越能确定。如果收益均值越大,则被选中的机会就越大(exploit),如果收益均值越小,其被选中的概率也就越少,同时哪些被选次数较少的item也会得到试验机会,起到了explore的作用。
Probability-matching策略表明一台机器的选择次数应当与它是最佳收益item的概率相同。其中Thompson采样就是一种Probability-matching策略算法,该算法也是一个的在线学习算法,即通过不断的观察数据来更新模型参数。
Thompson采样
Thompson采样假设每个item的收益率为p,那么如何来估计一个item的收益概率p呢?直接用试验结果的收益概率p是否合理呢?
比如一个item给用户展示了20次,用户点击了16次,那么我们可以认为这个item的收益率是80%吗?而这显然是不合理的,因为我们首先需要考虑的就是这个收益率的置信度,20次试验得出的结果置信度小于试验了10000次试验的置信度,其次可能我们的经验表明所有item的平均收益率只有10%。
Thompson采样使用Beta分布来描述收益率的分布 (分布的分布),我们通过不断的试验来估计一个置信度较高的基于概率p的概率分布。假设概率p的概率分布符合Beta(wins,
lose),beta分布有两个参数wins和lose,每个item都维护了beta分布的参数,每次试验都选择一个item,有点击则wins增加1,否则lose增加1。每次选择item的方式则是:用每个item的beta分布产生一个随机数,选择所有item产生的随机数中的最大的那个item。Beta分布概率密度函数如下:
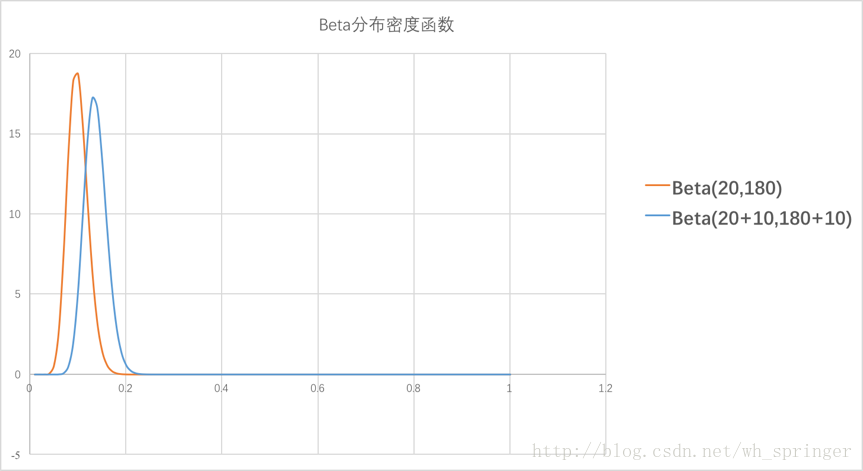
举例来说,推荐系统需要试探新用户的兴趣,假设我们用内容类别来表示每个用户的兴趣,通过几次展示和反馈来获取用户的兴趣。针对一个新用户,使用Thompson算法为每一个类别采样一个随机数,排序后,输出采样值top N 的推荐item。获取用户的反馈,比如点击。没有反馈则更新对应类别的lose值,点击了则更新对应类别的wins值。
后续:推荐系统中的冷启动和探索利用问题探讨 (下):LinUCB算法和CLUB算法