使用LLVM Pass进行程序依赖关系的分析
一、LLVM
1.1 LLVM简介
LLVM项目是模块化和可重用的编译器和工具链技术的集合。LLVM全称为Lower Level Virtual Machine,最初是以C/C++为编译目标,现如今LLVM已经能够为ActionScript、D、Fortran、Haskell、Java、Objective-C、Swift、Python、Ruby、Rust、Scala等众多语言提供了编译支持,有一些新兴的语言就直接使用LLVM作为后端。此外LLVM目前已经不仅仅是个编程框架,它目前还包含了很多的子项目,比如最具盛名的Clang。
在LLVM中,程序的基本组成单位是模块(Module)。函数(Function)是Module的基本组成单位,一个Module由一个或多个函数组成;基本块(Basic Block)是函数的基本组成单位;指令(Instruction)是基本块的基本组成单位。
LLVM主要由3部分组成:前端(Frontend)、Pass、后端(Backend)。前端将源代码编译为LLVM IR。LLVM IR主要有三种格式:一种是在内存中的编译中间语言;一种是磁盘上存储的二进制中间语言(字节码文件,以.bc结尾),最后一种是用户可读的文本表现形式的中间格式(以.ll结尾)。这三种中间格式是完全相等的。LLVM IR是前端的输出,后端的输入,桥接前后端。LLVM IR基于静态单赋值(Static Single Assignment —SSA)的,有很大的灵活性和类型的安全性,能够清楚的表达绝大多数高级语言。Pass对程序的中间表示进行分析转换,是LLVM系统转换和优化工作的一个节点,每个节点(Pass)做一些工作,这些工作加起来就构成 了LLVM整个系统的优化和转化。后端用来生成实际的机器码。
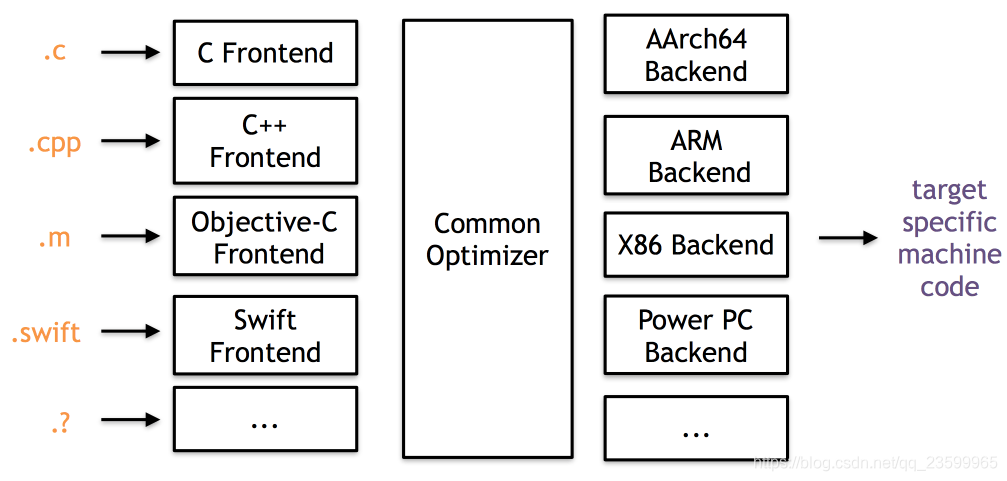
1.2 程序从源代码到可执行文件
编译简单来说其实就是把人类可读的高级语言映射到机器执行码。编译的过程是非常复杂的,为了使这个复杂的过程简化,LLVM就使用了模块化的思想,这样可以使得每一个编译阶段都被独立出来。总的分为以下几个部分:预处理(Preprocess)、词法分析 (Lexical Analysis)、语法分析 (Semantic Analysis)、IR代码生成 (CodeGen)、生成字节码 (LLVM Bitcode)、生成相关汇编文件、生成目标文件、、生成可执行文件。

二、编写LLVM Pass
LLVM 的pass框架是LLVM系统的一个很重要的部分。LLVM的优化和转换工作就是由多个pass来一起完成的。类似流水线操作一样,每个pass完成特定的优化工作。 要想真正发挥LLVM的威力,掌握pass是不可或缺的一环。LLVM中pass架构的可重用性和可控制性都非常好,这允许用户自己开发pass或者关闭一些默认提供的pass。总的来说,所有的pass大致可以分为两类:分析和转换。分析类的pass以提供信息为主,转换类的会修改中间代码。
2.1 Pass初探
首先,我们可以参照LLVM官方介绍Pass的文档,通过编写简单的分析类型的Pass来对Pass进行一个初步的认识。
(1) 基于Pass构建动态加载库
在llvm/lib/Transforms/Hello中,新建Hello.cpp:
#include "llvm/Pass.h"
#include "llvm/IR/Function.h"
#include "llvm/Support/raw_ostream.h"
using namespace llvm;
namespace {
struct Hello : public FunctionPass {
static char ID;
Hello() : FunctionPass(ID) {}
// Pass的入口点
bool runOnFunction(Function &F) override {
errs() << "Hello: ";
errs().write_escaped(F.getName()) << '\n';
return false;
}
}; // end of struct Hello
} // end of anonymous namespace
char Hello::ID = 0; //初始化Pass Id,LLVM使用ID的地址来标识Pass,因此初始化值并不重要
// 注册Pass,命令行参数“hello”,并命名为“Hello World Pass”
static RegisterPass<Hello> X("hello", "Hello World Pass",
false /* Only looks at CFG */,
false /* Analysis Pass */);
在llvm/lib/Transforms/Hello中,新建CMakeLists.txt:
# 指定当前目录中的MyHello.cpp文件将被编译并链接到共享对象build/lib/LLVMHello.so,
# 可由opt工具通过其-load选项动态加载。
add_llvm_loadable_module( LLVMHello
Hello.cpp
PLUGIN_TOOL
opt
)
在llvm/lib/Transforms/CMakeLists.txt中添加
add_subdirectory(Hello)
在build目录下执行make,生成LLVMHello.so

(2) 将测试程序转换为LLVM IR文件
clang++ test.cpp -c -emit-llvm -o test.bc
(3) 使用opt -load加载共享库以执行Pass对IR文件进行分析
opt -load .../build/lib/LLVMHello.so -hello test.bc
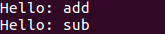
这样的一个过程,就是从编写LLVM Pass到使用编写的Pass对程序进行分析的一个完整的实现步骤。
2.2 程序依赖关系的分析
以往对于程序依赖关系的分析大多是依据信息流策略,使用LLVM Pass来对程序进行依赖关系的分析,主要包括以下3个方面:通过分析Def-Use指令链构建数据依赖图(DDG)、通过调用llvm/Analysis/MemoryDependenceAnalysis.h来构建内存依赖图(MDG)、通过调用llvm/Analysis/PostDominators.h实现对控制依赖图(CDG)的构建。进一步对DDG、MDG和CDG进行合并,生成程序依赖关系图(PDG)。其中,DDG和MDG构建的是指令(Instruction)之间的依赖关系,而CDG构建的是基本块(Basic Block)之间的依赖关系。
(1) 定义DependenceGraph
首先先定义依赖图,用于记录节点(指令或基本块)之间的依赖关系
template <typename ValueType> class DependenceGraph {
protected:
// 依赖关系表示为从节点到依赖于它们的节点集的映射
map<const ValueType *, set<const ValueType *>> Nodes;
public:
// 节点迭代器
typedef typename map<const ValueType *, set<const ValueType *>>::iterator nodes_iterator;
typedef typename map<const ValueType *, set<const ValueType *>>::const_iterator const_nodes_iterator;
typedef typename set<const ValueType *>::iterator dependant_iterator;
typedef typename set<const ValueType *>::const_iterator const_dependant_iterator;
void addNode(const ValueType *Value);
void addEdge(const ValueType *From, const ValueType *To);
void removeNode(const ValueType *Value);
void removeEdge(const ValueType *From, const ValueType *To);
bool dependsOn(const ValueType *A, const ValueType *B);
// 获取依赖于节点A的节点集。
const set<const ValueType *> &getDependants(const ValueType *A) const;
dependant_iterator child_begin(const ValueType *A);
dependant_iterator child_end(const ValueType *A);
void clear();
nodes_iterator nodes_begin();
nodes_iterator nodes_end();
};
(2) DDG(数据依赖关系图)的构建
DDG主要是通过对def-use指令链的分析进行构建:
bool DataDependenceGraphPass::runOnFunction(Function &F) {
for (inst_iterator I = inst_begin(F), E = inst_end(F); I != E; ++I) {
Instruction *Inst = &*I;
DDG.addNode(Inst);
}
for (inst_iterator I = inst_begin(F), E = inst_end(F); I != E; ++I) {
for (User *U : I->users()) {
if (Instruction *Inst = dyn_cast<Instruction>(U)) {
DDG.addEdge(&*I, Inst);
}
}
}
return false;
}
对于数据依赖图的构建,首先在图中将函数中每条指令添加到节点中,然后在图中将具有数据依赖关系的两条指令添加对应的边。
(3) MDG(内存依赖关系图)的构建
MDG是通过使用LLVM内置的MemoryDependenceAnalysis Pass来进行构建:
bool MemoryDependenceGraphPass::runOnFunction(Function &F) {
MemoryDependenceAnalysis &mda = Pass::getAnalysis<MemoryDependenceAnalysis>();
for (inst_iterator I = inst_begin(F), E = inst_end(F); I != E; ++I) {
Instruction *Inst = &*I;
MDG.addNode(Inst);
}
for (inst_iterator I = inst_begin(F), E = inst_end(F); I != E; ++I) {
Instruction *Inst = &*I;
if (!Inst->mayReadOrWriteMemory()) {
continue;
}
MemDepResult mdr = mda.getDependency(Inst);
Instruction *DepInst = mdr.getInst();
if (DepInst != nullptr && mdr.isDef()) {
MDG.addEdge(DepInst, Inst);
}
}
return false;
}
对于内存依赖图的构建,首先在图中将函数中每条指令添加到节点中,然后在图中将具有内存依赖关系(这里仅考虑def依赖)的两条指令添加对应的边。
(4) CDG(控制依赖关系图)的构建
CDG是通过使用LLVM内置的PostDominatorTree pass来进行构建,基本组成单位是Basic Block:
bool ControlDependenceGraphPass::runOnFunction(Function &F) {
const PostDominatorTree &pdt = Pass::getAnalysis<PostDominatorTree>();
stack<DomTreeNode *> bottom_up_traversal = getBottomUpTraversal(pdt);
map<BasicBlock *, set<BasicBlock *>> post_dom_frontier =
getPostDomFrontier(pdt, std::move(bottom_up_traversal));
for (auto &kv : post_dom_frontier) {
BasicBlock *node = kv.first;
CDG.addNode(node);
}
for (auto &kv : post_dom_frontier) {
BasicBlock *to = kv.first;
for (BasicBlock *from : kv.second) {
CDG.addEdge(from, to);
}
}
return false;
}
后序支配树被用于构建控制依赖图,首先我们构建当前函数的后序支配树的自下而上的遍历的stack,然后使用它来为控制流图中的每个节点构建后序支配边界,从基本块到其后序支配边界的映射的reverse就是从基本块到具有控制依赖关系的基本块的映射,这样就完成了CDG的构建。
(5) 组合DDG,MDG和CDG形成PDG
bool ProgramDependenceGraphPass::runOnFunction(Function &F) {
const DependenceGraph<BasicBlock> &cdg =
Pass::getAnalysis<ControlDependenceGraphPass>().getCDG();
const DependenceGraph<Instruction> &mdg =
Pass::getAnalysis<MemoryDependenceGraphPass>().getMDG();
const DependenceGraph<Instruction> &ddg =
Pass::getAnalysis<DataDependenceGraphPass>().getDDG();
for (auto I = ddg.nodes_cbegin(), E = ddg.nodes_cend(); I != E; ++I) {
PDG.addNode(I->first);
}
for (auto I = ddg.nodes_cbegin(), E = ddg.nodes_cend(); I != E; ++I) {
const Instruction *source = I->first;
for (const Instruction *target : I->second) {
PDG.addEdge(source, target);
}
}
for (auto I = mdg.nodes_cbegin(), E = mdg.nodes_cend(); I != E; ++I) {
const Instruction *source = I->first;
for (const Instruction *target : I->second) {
PDG.addEdge(source, target);
}
}
for (auto I = cdg.nodes_cbegin(), E = cdg.nodes_cend(); I != E; ++I) {
const Instruction &source = I->first->back();
for (const BasicBlock *BB : I->second) {
for (BasicBlock::const_iterator it = BB->begin(); it != BB->end(); ++it) {
PDG.addEdge(&source, &*it);
}
}
}
DepGraphTraitsWrapper<Instruction>(PDG).writeToFile("pdg.test.dot");
return false;
}
PDG的构建是将DDG、MDG和CDG进行合并,PDG的基本组成单元是指令,与DDG,MDG一致。首先我们从DDG和MDG中复制节点和依赖关系到PDG中,由于CDG中表示的是基本块之间的依赖关系,并且依赖基本块的所有指令取决于父基本块的最后一条指令,将这样的指令间的依赖关系加入到PDG以实现对CDG的转换,这样就完成了PDG的构建,实现了对于程序数据、控制和内存依赖关系的分析。
三、总结
本文简要介绍了LLVM的基本组成部分、LLVM IR和程序的编译过程,通过编写简单的LLVM Pass来初步认识Pass和如何使用自己编写的Pass对程序进行分析,进一步说明了使用LLVM Pass对程序进行依赖关系的分析分为数据、控制和内存依赖关系的分析,通过合并DDG,MDG和CDG来形成PDG。
参考 & 引用
[1] Jeanne Ferrante, Karl J. Ottenstein, Joe D. Warren. The program dependence graph and its use in optimization. ACM Transactions on Programming Languages and Systems, Vol.9, No.3, July 1987, Pages 319-349.
[2] Stanislav Manilov, Christos Vasiladiotis, Björn Franke. Generalized Profile-Guided Iterator Recognition. The University of Edinburgh. CC’18, February 24–25, 2018, Vienna, Austria.
[3] http://llvm.org/docs/WritingAnLLVMPass.html
[4] https://blog.csdn.net/hypercode/article/details/53815894
[5] https://github.com/compor/icsa-dswp