笔记
算法设计方法有多种。插入排序使用了增量法:在排序子数组
后,将单个元素
插入子数组的适当位置,产生排序好的子数组
。
本节采用另一种方法,即分治法,同样来完成数组的排序。总的来说,分治法的思想是:将原问题分解为几个规模较小但类似于原问题的子问题,递归地求解这些子问题,然后再合并这些子问题的解来建立原问题的解。典型的分治法分为三个步骤:
1) 分解:将原问题分为若干子问题,这些子问题是原问题的规模较小的实例。
2) 求解:递归地求解各子问题。若子问题的规模足够小,可直接求解,不用递归。
3) 合并:将这些子问题的解合并成原问题的解。
用分治法来解决数组排序问题的算法叫做归并排序。该算法完全遵循分治法,也分为三个步骤:
1) 分解:将待排序的
个元素的序列分成各具
个元素的两个子序列。
2) 求解:递归地排序两个子序列。
3) 合并:合并两个已排序的子序列以产生排好序的序列。
归并排序的关键操作是第3)步合并。以下是合并过程的伪代码。

执行MERGE过程,前提是子数组
和
已经排好序。其基本思想是:每次循环迭代,比较两个子数组中各自的最小值,取其中较小者放入合并的数组中;迭代直到两个子数组都变成空为止。合并之后的子数组
也已经排好序了。MERGE过程需要
的时间,其中
是待合并的元素的总数。
下面是归并排序的伪代码。

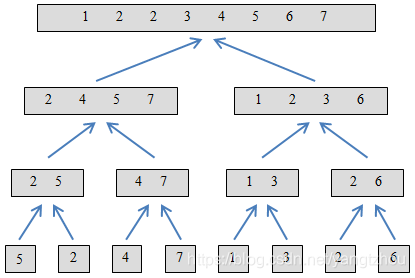
从伪代码可以看到,MERGE-SORT就是一个典型的分治算法。先递归排序左子数组,再递归排序右子数组,再调用MERGE合并左右子数组。下图展示了归并排序在数组
上的执行过程。
下面我们来分析归并排序的运行时间。假设对
个元素的数组进行归并排序的时间为
。归并排序先对两个规模为
的子数组递归排序,对每个子数组递归排序的时间为
;然后合并两个排好序的子数组,这一过程的时间为
。根据以上分析,可以得到递归式
。初始情况是
,即只有一个元素的数组,显然对只有一个元素的数组的排序时间是常数时间,即
。综合以上分析,可以得到
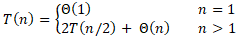
求解这个递归式,得到
。
练习
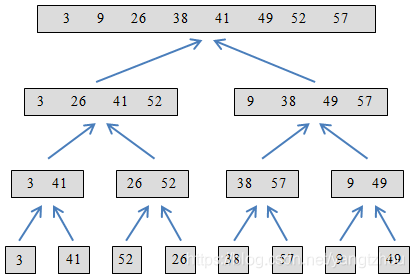
2.3-1 使用图2-4作为模型,说明归并排序在数组
上的操作。
解
2.3-2 重写过程MERGE,使之不使用哨兵,而是一旦数组
或
的所有元素均被复制回
就立刻停止,然后把另一个数组的剩余部分复制回
。
解
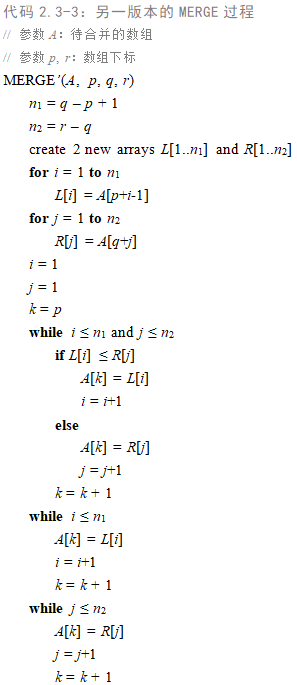
2.3-3 使用数学归纳法证明:当
刚好是
的幂时,以下递归式的解是
。
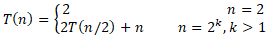
解
初始情况
,
,等式
成立。
现在假设等式对
成立,即
。根据递归式,
。
2.3-4 我们可以把插入排序表示为如下的一个递归过程。为了排序
,我们递归地排序
,然后把
插入已排序的数组
。为插入排序的这个递归版本的最坏情况运行时间写一个递归式。
解
排序
的时间分为两部分:1) 排序
的时间
;2) 将
插入到已排序数组
的时间
。
将
插入到已排序数组
,在最坏情况下需要做
次比较,故最坏情况时间为
。
将两部分时间相加得到递归式
。
2.3-5 回顾查找问题(参见练习2.1-3),注意到,如果序列
已排好序,就可以将该序列的中点与
进行比较。根据比较的结果,原序列中有一半就可以不用再做进一步的考虑了。二分查找算法重复这个过程,每次都将序列剩余部分的规模减半。为二分查找写出迭代或递归的伪代码。证明:二分查找的最坏情况运行时间为
。
解
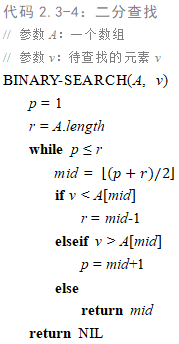
2.3-6 注意到2.1节中的过程INSERTION-SORT的第5~7行的while循环采用一种线性查找来(反向)扫描已排好序的子数组
。我们可以使用二分查找(参见练习2.3-5)来把插入排序的最坏情况总运行时间改进到
吗?
解
用二分查找,可以在
时间之内找到
要插入的位置。但是要将
插入到合适的位置
,需要将
中每个元素都向后移一个位置,在最坏情况下,这个过程仍然需要花费
时间。因此,引入二分查找不能把插入排序的最坏情况运行时间降到
。
2.3-7 描述一个运行时间为
的算法,给定
个整数的集合
和另一个整数
,该算法能确定
中是否存在两个其和刚好为
的元素。
解
最简单的办法,考察数组中的所有元素对,看看其中是否有和为
的。长度为
的数组,一共有
个元素对,因此这种方法的运行时间为
。
然而,如果数组已经排好序,可以利用数组的有序性来大大降低算法的运行时间。接下来的分析假定数组已经是有序的,即
。
先考察数组的首尾元素
和
,根据它们的和,分为三种情况:
①
这种情况可以排除
,问题转化为查找子数组
。因为
需要与一个比
更大的元素相加,它们的和才有可能等于
,而
已经是数组中最大的元素,数组中没有比
更大的元素。
②
这种情况可以排除
,问题转化为查找子数组
。因为
需要与一个比
更小的元素相加,它们的和才有可能等于
,而
已经是数组中最小的元素,数组中没有比
更小的元素。
③
此时找到了两个和刚好为
的元素。
根据以上分析,该算法实际上是一个递归过程。每次递归,子数组的模规减
。最坏情况是,当子数组的规模减到
时(只有一个元素),还没有找到两个和为
的元素,这说明数组
中不存在和为
的两个元素。显然,这一过程的运行时间为
。
对数组
排序采用归并排序算法,时间复杂度为
。因此,整个算法的运行时间为
。

本节代码链接:https://github.com/yangtzhou2012/Introduction_to_Algorithms_3rd/tree/master/Chapter02/Section_2.3