这是一篇机器学习的介绍,本文不会涉及公式推导,主要是一些算法思想的随笔记录。
适用人群:机器学习初学者,转AI的开发人员。
编程语言:Python
机器学习三剑客
- Numpy :数组与矩阵运算
- Matplotlib :绘图
- Pandas :数据分析与处理,个人理解:SQL+Excel
Numpy与Scipy
numpy 准确地说提供了一个在python中做科学计算的基础库,狭义地讲它重在数值计算,甚至可以说是用于多维数组处理的库;而 scipy 则是基于numpy,提供了一个在python中做科学计算的工具集,也就是说它是更上一个层次的库,主要包含一下模块:
- statistics 统计
- optimization 优化
- numerical integration 数值积分
- linear algebra 线性代数
- Fourier transforms 傅里叶变换
- signal processing 信号处理
- image processing 图像处理
- ODE solvers 微分方程求解器
- special functions 特殊功能
Matplotlib与Seaborn、Plotly
Matplotlib是最基础的可视化库;
Seaborn 是基于 Matplotlib 的一个可视化工具,它提供了一些更高级的接口,让绘图过程更简洁。Seaborn针对的点主要是数据挖掘和机器学习中的变量特征选取,Seaborn可以用短小的代码去绘制描述更多维度数据的可视化效果图。
数据分析的一个业务场景就是用数据讲故事,交互信息可视化的工具就在此凸显出了优势。
Plotly实现了在线导入数据做可视化并保存内容在云端server的功能。做演示的时候,只需要在本地的jupyter notebook与plotly server建立通信,即可调用已经做好的可视化内容做展示。
Plotly作图神器使用指南
Pandas与StatsModels
Pandas着眼于数据的读取、处理和探索,而StatsModels则更加注重数据的统计建模分析,它使得 Python有了R语言的味道。
StatsModels支持与 Pandas进行数据交互,因此,它与 Pandas结合,成为了 Python下强大的数据挖掘组合。
机器学习包:scikit-learn
scikit-learn是python的机器学习开发包,里面集成了机器学习的大部分算法(热门的XGBoost需要单独下载,但scikit-learn提供了与XGBoost兼容性的接口),官网地址:https://scikit-learn.org/dev/index.html ,如下是scikit-learn经典小抄:

Scikit-learn的基本功能主要被分为六大部分:分类,回归,聚类,数据降维,模型选择和数据预处理。
分类是指识别给定对象的所属类别,属于监督学习的范畴,最常见的应用场景包括垃圾邮件检测和图像识别等。目前Scikit-learn已经实现的算法包括:支持向量机(SVM),最近邻,逻辑回归,随机森林,决策树以及多层感知器(MLP)神经网络等等。
需要指出的是,由于Scikit-learn本身不支持深度学习,也不支持GPU加速,因此这里对于MLP的实现并不适合于处理大规模问题。有相关需求的读者可以查看同样对Python有良好支持的Keras、Tensorflow等框架。
回归是指预测与给定对象相关联的连续值属性,最常见的应用场景包括预测药物反应和预测股票价格等。目前Scikit-learn已经实现的算法包括:支持向量回归(SVR),脊回归,Lasso回归,弹性网络(Elastic Net),最小角回归(LARS ),贝叶斯回归,以及各种不同的鲁棒回归算法等。
聚类是指自动识别具有相似属性的给定对象,并将其分组为集合,属于无监督学习的范畴,最常见的应用场景包括顾客细分和试验结果分组。目前Scikit-learn已经实现的算法包括:K-均值聚类,谱聚类,均值偏移,分层聚类,DBSCAN聚类等。
数据降维是指使用主成分分析(PCA)、非负矩阵分解(NMF)或特征选择等降维技术来减少要考虑的随机变量的个数,其主要应用场景包括可视化处理和效率提升。
模型选择是指对于给定参数和模型的比较、验证和选择,其主要目的是通过参数调整来提升精度。目前Scikit-learn实现的模块包括:网格搜索,交叉验证和各种针对预测误差评估的度量函数。
数据预处理是指数据的特征提取和归一化等,是机器学习过程中的第一个也是最重要的一个环节。特征提取是指将文本或图像数据转换为可用于机器学习的数字变量。
总结来说,Scikit-learn实现了一整套用于数据降维,模型选择,特征提取和归一化的完整算法/模块,虽然缺少按步骤操作的参考教程,但Scikit-learn针对每个算法和模块都提供了丰富的参考样例和详细的说明文档。
多标签分类:scikit-multilearn
多标签分类的例子,比如给电影分类,爱情、浪漫、科幻、记录、动作等,但是很多电影往往不是只属于其中某一类,而是同属多个类,如:浪漫、爱情。
Scikit-learn提供了一个独立的库scikit-multilearn,用于多种标签分类。为了更好的理解,让我们开始在一个多标签的数据集上进行练习。scikit-multilearn库地址:http://scikit.ml/api/datasets.html
参考文章:解决多标签分类问题(包括案例研究)
附上一副机器学习的知识体系图,图中列出了大部分知识点:
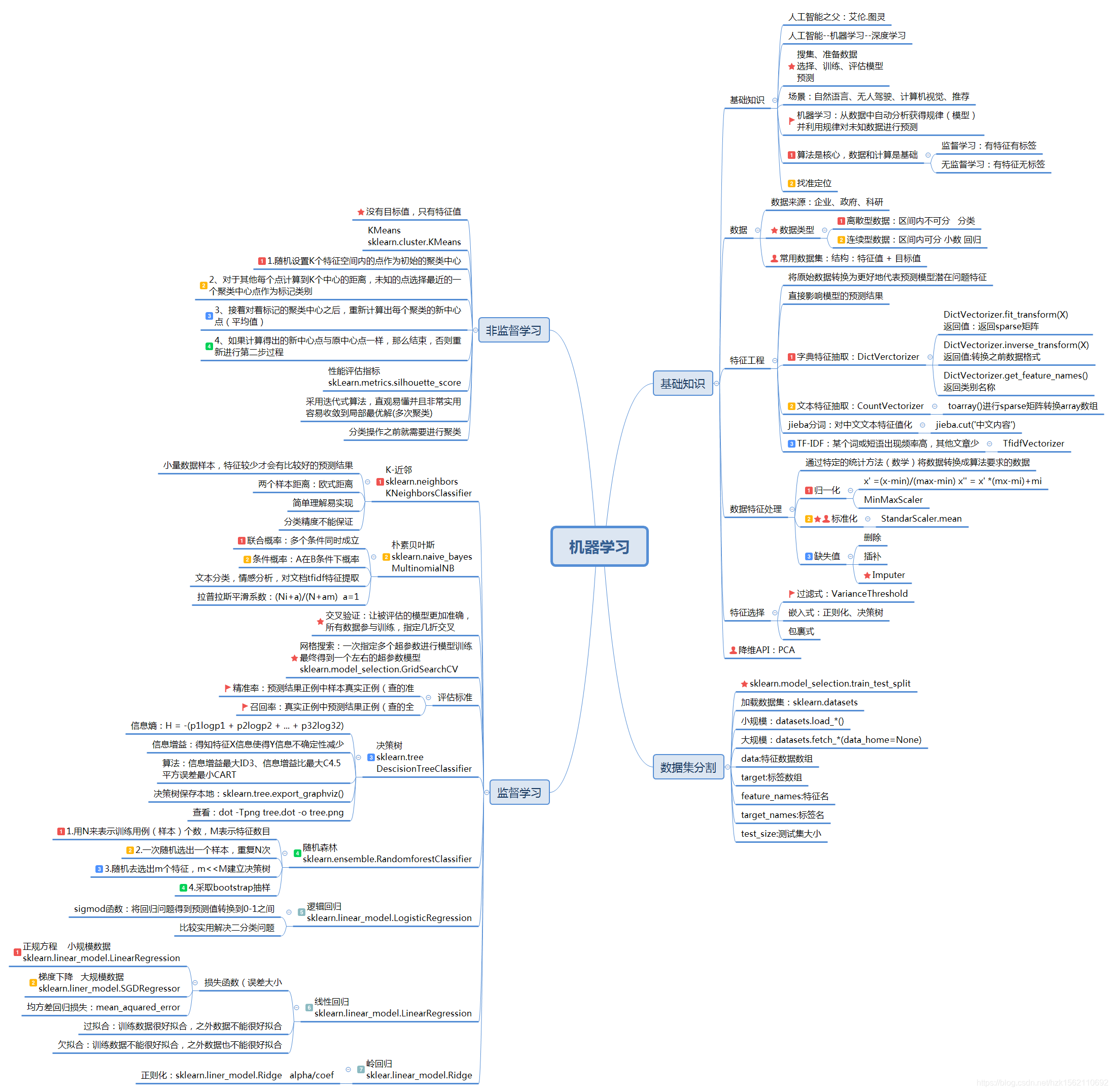
共勉!