经历了四周学习和三次OO作业,现对OO第一阶段进行总结。
(一)基于度量分析程序结构
尽管老师上课一再强调,OO是面向对象编程,要注重类的划分,类与类之间传递的是消息,但是由于自身理解不到位,至今尚未从面向过程编程的思想中走出,在划分类的时候出现类与类之间耦合太多,类的划分不清晰等问题。
以下是第一次作业类之间的关系图。
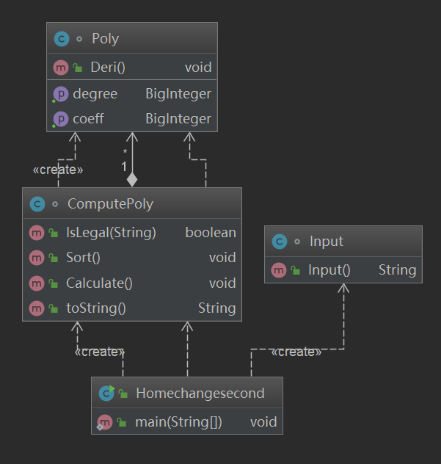
其中:
Homechangesecond是主类,占12行;
Input是处理输入的类,其功能仅是返回一个输入的字符串,占12行;
Poly是因子类,其中包含两个属性——系数和指数,类中包含的方法有实例化对象、求导以及返回系数和指数,占29行;
ComputePoly类的属性是Poly类的ArrayList,ComputePoly类完成了代码中的大部分工作,包括判断输入合法性,将表达式解析成各个项并提取项的系数和指数,把求导后的项再次合成为字符串,占202行。
其中类的内聚及耦合情况如下:
由图中可见,不少模块存在基本复杂度,模块设计复杂度以及圈复杂度较高的问题。
第二次作业类之间的关系图:
由图可知,第二次作业笔者设计的类与类之间的交互明显比第一次多。
考虑到第一次作业中ComputePoly类太长且过于面向过程,因此在第二次作业中,我将ComputePoly中的某些方法单独提取出来自成一类(但总感觉自己在写函数),由于第二次作业增加了三角函数,因此此次作业与第一次相比,因子类发生了变化,除了有幂函数类(ItemP),增加了三角函数类(ItemT)以及项类(Item)。
类的内聚及耦合情况如下:
第三次作业:
由于第三次作业比较复杂,笔者对类的理解不到位,递归下降分析法从未接触过,因此尽管老师已给提示,我和同伴思索一天后仍然没有想到一个能够较好地提取出每一个因子的方法,因此采用了寻找并替换合法因子为x的方法,判断表达式是否合法,在递归求导的时候,递归的终止条件是输入为符合第二次语法规则的表达式,并直接使用第二次的代码计算出求导结果,完全面向过程极其不优雅地写完了第三次作业。
因此第三次作业的类图与第二次几乎相同:
(二)分析程序的bug
在三次作业中,我都会在通过中测后以走查的方式整理一遍思路,并检查是否有错误,并且在第三次,由于替换因子感到可能存在情况尚未考虑,因此构造了一些测试数据对自己的代码进行了测试。尽管如此,三次作业都仍然存在bug,十分幸运bug都没有使程序在强测时崩溃,但在互测环节bug均会被找出。
第一次作业,难点在于如何写出正确的正则表达式。由于因子只能是常数或幂函数,比较简单,因此我在考虑输入的时候采用了覆盖的方式,分析所有可能出现的输入,并最终合成一个大正则。但由于NFA在匹配时存在回溯,因此表达式的长度较长时,存在正则表达式爆栈的可能,因此我开启了正则表达式的独占模式,但由于匹配的最后一行手残把‘+’错写为了‘?’,因此当表达式为x*x*……*x(长度为1000左右)时再次发生了爆栈的惨剧(笔者在课下测试时没使用500个x连乘验证正确性,而是使用了150个4*x^3连乘,因此没有发现独占模式修改错误这个问题,bug的发现是在笔者测试同组同学的代码时发现的)。除了正则表达式爆栈,我的第一次作业还存在一个bug。我使用了java中的Collection.sort()方法对项进行排序,但是使用时没理解Collection.sort()比较的机制,返回值只设置成1和-1两种情况(实际上应该设置0、-1、1三种),因此当输入某些式子的时候,Collection.sort()会抛出异常。
第二次作业,笔者的程序仍然存在bug。由于大正则存在爆栈的风险,因此本次作业判断输入正确与否时,我写出了表达式每一项的正则表达式,并最终利用长度判断整个表达式的正确性。但由于对正则表达式机制的理解不到位,在检索第一个合法项是否存在时,正则表达式的起点未加‘^’,导致正则表达式可能不从起点开始匹配并最终导致错误。此外,在合并同类项时,居然没有考虑到合并之后类的系数和指数会改变,把遍历确认合并的基准项值提取过程提到了遍历for循环的外面,导致错误(特别感谢找出该bug的同学,虽然第三次作业写的极为不堪,但是第二次作业此bug的找出保证了第三次作业中求导的正确性)。
第三次作业,没想到使用递归下降法,在思索如何构建正则表达式良久无果后,和同伴决定采用替换的方法判断输入的正确性。然而bug再次出现在正则表达式,替换表达式因子时,没有考虑到表达式因子的括号外层可能存在空格,因此导致错误。
(三)如何发现别人程序的bug
第一次作业,由于笔者是覆盖地考虑正则表达式的输入情况,自以为天衣无缝,因此没有提前构造测试数据。由于没有构造测试数据,加之第一次作业较为简单,再者本着学习他人代码(各个击破?)的目的,我选择通过阅读他人源码的方式查找错误并且设计测试用例,并且使用了总所周知的500个x连乘检查代码是否爆栈,然而阅读了三四份代码后感到力不从心,便放弃继续寻找bug。
第二次作业,笔者仍然是覆盖的考虑正则表达式,仍然对正则表达式十分有信心,因此仍然没有提前构造测试数据。然而阅读半份代码后感到力不从心,因此临时构造测试数据,并且使用脚本对所有人的代码进行测试,然而该脚本不含Sympy的功能,因此在大多数时候只能判断输出是否大致长这样。
第三次作业采用与第二次作业相同的方式,只是提前构造了测试集并且对自己的代码错了测试。
(四)对三次作业的分析
写完三次作业,仍然感到自己对类、继承、接口等概念不太熟悉。
第一次ComputePoly类过于复杂,且面向过程,修改起来不太容易。
第二次作业中将ComputePoly类拆成检查、求导、合并等类,并且构建三个存储数据的类。但是现在想来感觉自己在写函数,仍是面向过程。后来接触到了继承、接口等概念,感觉应该设计一个Item作为父类,Item中包含了系数以及三个指数作为属性,ItemP是Item的一个继承,其sin以及cos的指数均为0,ItemS是Item的一个继承,其x和cos的指数为0,ItemC是Item的一个继承,其x和sin的指数为0,对于上述四个类均实现一个求导的接口,再构建一个Items类,其属性为Item类型的ArrayList,并且实现对Items类的合并同类项以及改写的toString接口(或许理解仍然不到位,如有错误,还请指出)。
前文提到,第三次作业写的极为不堪,不仅没有优化,甚至没有清晰的类。参考了部分同学的代码后,我大致认为第三次作业的代码应该这样重构。首先需要有基本因子类(包括常数、幂函数、sin、cos,每个类中均有系数和指数属性)以及表达式因子类(系数、内表达式、指数3个属性),还需要有加法类、乘法类、嵌套因子类。读入字符串时,我们处于表达式层,调用加法类,提取出每个项,进入项层,调用乘法类,进入因子层,如果在因子层发现三角函数,进入嵌套函数类……由此,我们可构建一棵表达式树。求导时,为加法类、乘法类、嵌套因子类、基本因子类各设计求导接口,由此可实现表达式的求导。
以上是我对第一套OO作业的反思,若有不准确或可以改进的地方,欢迎指教。