(今天第一次去面试机器学习,被打击到不行,致郁)
未来可能有很多面试,这里就是打算把每一次面试的教训总结起来,告诉自己下次表现得会更好!
本文会不断补充完善…
经验:
1.重视常见算法的数学公式,要会默,要理解,要板书,要讲解;
2.项目经验:(台词必须准备充足)
项目经验中的算法说出自己熟悉的,因为面试的人下一步就会问到算法是怎么实现的,更进一步就是非常非常细节的东西;
如果这个项目你不是主要参与者,一定事先找好相应的算法,完善好相应细节,一定要自圆其说;
一定要有非常熟悉的几个算法,原理机制完全搞清楚,问到项目就引到自己熟悉的领域。
每逢面试必须面对的问题,要不断通过面试完善项目经验讲解的模板,上一轮技术面试指出的漏洞回去一定要及时完善。
(面试问题到我的:训练用的什么算法,样本提取什么特征,什么损失函数,然后各种为什么。。。。)
3.面试官会说你把这个算法讲一下,然后可能就懵了,感觉无法用语言说明。觉得最好板书,写公式,画画函数图。
公式:
有些面试官需要板书数学公式,简单罗列一下:
最好自己手写,之前面试公式写错,面试官直接打断我,把公式纠正回来,就没让我继续往下讲了,面试草草结束了。。
1.单变量线性回归假设函数:
0:偏置; 1:权重
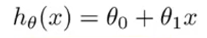
2.多变量线性回归假设函数:
0:偏置; 1~n:权重
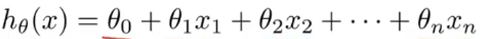
注意:!!!为了方便向量运算,我们会给偏置乘上一个常数1,如下:
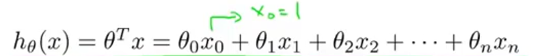
公式可以简化为:权重向量(第一个元素是偏置)与变量向量(第一个元素是1)做乘法;
3.平方差代价函数(损失函数)
这里可以把多个特征组合成一个向量;
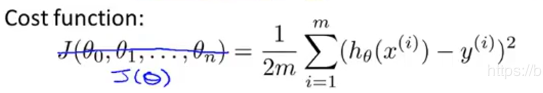
解读:预测值与真实值差的平方(保证正数)之和/2倍的样本数量;
为什么是除以2m而不是除以m?
因为1/2m方便求导,约掉求导后的*2
4.梯度下降算法
权重 = 原权重 - 步长 * 该权重的偏导数(可理解为斜率) * 损失函数
偏导数为正,则在最低点的右侧,权重会不断减小以接近最低点;
偏导数为负,则在最低点的左侧,权重会不断增大以接近最低点;
越接近最低点,损失函数就越小,则每次的变化幅度都不断减小;
步长过小则训练缓慢;步长过大则有直接越过最低点的风险;
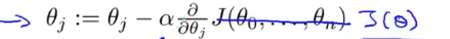
若是代入损失函数的公式化简后则如下:
注:这里可以看出之前平方差损失函数为什么要/2m
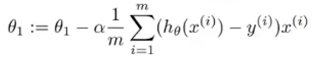
若是多个特征则以此类推:
偏置也会代入梯度下降算法(比较特殊)

5.关于逻辑回归相关公式:
逻辑回归:一种模型,通过S型函数用于线性预测,生成分类问题中每个可能的离散标签值的概率;常用于二分类;
s型函数定义如下:
z = b + w1x1 + w2x2 + … wNxN
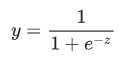
问答:
1.什么是熵?什么是交叉熵?交叉熵与平方差在作为代价函数上有什么区别?
1.熵:如果一个随机变量X的可能取值为X = {x1, x2,…, xk},其概率分布为P(X = xi) = pi(i = 1,2, …, n),则随机变量X的熵定义为:
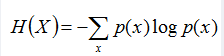
熵的代表的是期望的稳定性,反过来说也可以代表不确定性,值越小表示期望越稳定,值越大表示不确定性越高。熵为0时表示已经板上钉钉盖棺定论了,熵越大标识变数越大,结果越难预测。
2.交叉熵:考虑一种情况,对于一个样本集,存在两个概率分布 p(x) 和 q(x) ,其中 p(x) 为真实分布,q(x) 为非真实分布。基于真实分布 p(x) 我们可以计算这个样本集的信息熵也就是编码长度的期望为:
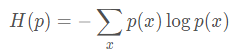
回顾一下负对数项表征了所含的信息量,如果我们用非真实分布 q(x)来代表样本集的信息量的话,那么:
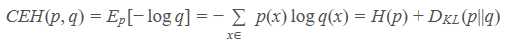
因为其中表示信息量的项来自于非真实分布 q(x) ,而对其期望值的计算采用的是真实分布 p(x) ,所以称其为交叉熵 (Cross Entropy)。
交叉熵=熵+相对熵,拟合度越高相对熵越小,交叉熵也越小,完美拟合的条件下交叉熵就等于熵。
3.平方差代价函数:常见于线性回归模型;
交叉熵代价函数:机器学习中经常用来处理分类问题(如MNIST)
2.如何进行深度学习的网络模型优化
提高速度
1. Mini-batch gradient descent
在数据集非常大的情况下,每次迭代若是对所有样本进行矩阵运算训练速度会很慢;
我们可将m训练样本分成T个样本子集,每次对单一子集进行梯度下降算法,然后循环T次,总共会进行T次梯度下降算法;
推荐常用的mini-batch size为64,128,256,512。这些都是2的幂
提升精度
1.网络性能在训练数据集上效果不好时,我们会调整网络结构,比如增加层数,神经元个数;(但不是越深代表越好,过于复杂会出现过拟合问题)
2.尝试新的激活函数,如Relu(可解决梯度消失问题)
3.选用优化算法。。。。。
3.关于dropout
dropout是以一定的概率丢弃部分单元,这样网络就简化了。防止过拟合
在min-batch的相关算法中,
对于每一个min-batch,我们都要重新进行drouput,改变网络的结构,并使用新的网络结构去训练。
4.关于梯度消失和梯度爆炸
出现梯度消失原因:通常神经网络都是sigmoid函数,可将正无穷到负无穷的数映射到0到1之间;神经网络的反向传播是逐层对函数偏导相乘;网络层数非常深时,接近输出的层可能会特别小,接近于0,造成梯度消失。
解决梯度消失:采用ReLu激活函数;BN层批规范化;
梯度爆炸:初始权重特别大,前面层会形成非常大的梯度,然后导致网络权重大幅更新,网络变得不稳定,后面权重会越来越大,梯度过大难以收敛;
解决梯度爆炸:采用ReLu激活函数;采用梯度阶段或正则化;重新设计网络模型,建立层数更少的网络;BN层批规范化;
5.神经网络的优点
遇到复杂的非线性问题时,难以手动创建模型,需要利用神经网络让计算机自主创建模型;
具有联想存储功能;
具有高速寻找优化解的能力;
6.cnn的优缺点
优点:
1.共享卷积核。权重共享网络结构,降低网络复杂度,减少权值数量使网络易于优化,降低过拟合风险;
2.局部连接。相比与传统神经网络的全连接,降低复杂度;
3.良好的容错能力,并行处理能力和自学习能力,可处理环境信息复杂的问题;
缺点:
1.实现比较复杂,训练所需时间比较久;
2.反向传播BP需要大量数据集的支持;
3.平移不变性,同一 object 发生轻微朝向或位置变化时,可能并不会激活那些识别该 object 的神经元
4.pooling层会丢失大量的有价值信息,以及忽略局部与整体的关联性;
7.BN层的作用
BN:batch normalization 批规范化
BN层具有加速网络收敛速度,提升训练稳定性的效果;
原理:通过规范化操作将输出信号规范化保证网络的稳定性;
例如:BN层解决梯度上的问题(w影响梯度爆炸和梯度消失)
对于sigmoid函数,整体分布逐渐往非线性函数的取值区间的上下限两端靠近,这是训练深度神经网络越来越慢的本质原因。BN通过一定规范化的手段,把每层神经网络任意神经元这个输出值分布强行拉回均值为0,方差为1的标准正态分布。
8.神经网络输出特征图大小的计算公式
9.vgg16的模型结构
10.简述逻辑回归
一种模型,将S型函数用于线性预测,生成分类问题中每一个离散标签值的概率;常用于二分类问题;逻辑回归是一种极其高效的概率计算机制;
s型函数:一种函数,可将逻辑回归输出或多项回归输出(对数几率)映射到概率,以返回介于 0 到 1 之间的值。
s型函数定义:
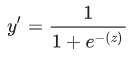
11.防止过拟合的方法
1.正则化;
2.dropout
3.优化网络模型,降低网络复杂度(如图形问题用cnn替代传统神经网络)