笔记
本节给出快速排序运行时间的详细分析。
(1) 最坏情况运行时间
假设
是最坏情况下QUICKSORT的运行时间,那么
满足以下递归式
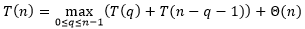
因为调用PARTITION生成的2个子数组的长度加起来为
,因此上式中参数
的变化范围是
。我们用代入法来证明
。
先证明
。假设
,其中
为一个常数。
我们先看初始情况
。此时有
。
为常数时间,显然只要
足够大,就能使得
成立。
现在进行数学归纳。假设
对
都成立。于是有
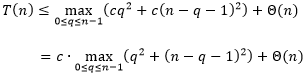
在
范围内,表达式
在
或
时取得最大值,并且最大值为
。因此
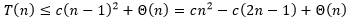
如果
足够大,使得
大于
,就可以使得
成立。
综上所述,只要选取足够大的
,就可以使得
对所有
的取值都成立。因此,
成立。
我们同样可以证明
(见练习7.4-1)。因此,快速排序的最坏情况运行时间为
。
(2) 期望运行时间
快速排序的运行时间实际上取决于元素之间比较的次数,我们假设总的比较次数为
。我们假设一个数组
中的元素从小到大依次为
,并用
表示
与
之间的元素集合
。我们要考察任意
个元素
与
什么时候会进行比较。
首先我们可以断言,每一对元素至多比较一次。因为在PARTITION调用过程中,每个元素只会与选出来的划分主元进行比较,并且比较结束后,这个被选出来的划分主元就会被放置到正确的位置,在之后递归调用PARTITION过程中,这个划分元素就不会再参与比较了。
我们用
表示元素
与
的比较次数。根据上面的分析,
是一个随机变量,并且只可能有
个取值:
和
。换言之,
是一个指示器随机变量。
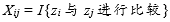
由随机变量
,我们可以很容易得到总的比较次数
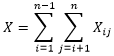
我们要计算快速排序的期望运行时间,也就是要计算总的比较次数
的期望值
,于是有
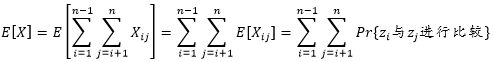
其中
{
与
进行比较} 是
与
进行比较的概率。
我们现在来分析任意
个元素
与
会进行比较的概率。我们假设数组中每个元素都是互异的。如果在包含
中的所有元素的一次PARTITION调用中,一旦满足
的一个元素
被选择为划分主元,那么
和
就会划分到2个不同的子数组中,
和
就再也没有机会进行比较了。相反地,如果在包含
中的所有元素的一次PARTITION调用中,
被选为划分主元,那么
就会和
比较;同样,如果
被选为划分主元,那么
也会和
比较。因此,当且仅当
或
在
中被首先选为划分主元时,
和
才会进行比较。
中的元素都会等可能地被首先选为划分主元,所以每个元素被选择的概率为
。于是有

于是我们可以得到

我们令
,将上式做一下变换。
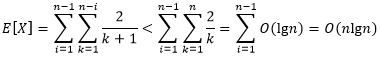
由此我们得到,快速排序的期望运行时间的上界为
。在7.2节,我们得到结论:快速排序的最好情况运行时间为
,即快速排序的运行时间的下界为
。因此,我们可以断言,快速排序的期望时间复杂度为
。
练习
7.4-1 证明:在递归式
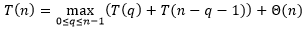
中,
。
解
假设
,其中
为一个常数。我们用数学归纳法来证明。
(1) 初始情况n = 1
此时有
。
为常数时间,显然只要
足够小,就能使得
成立。
(2) 归纳过程
假设
对
都成立,于是有
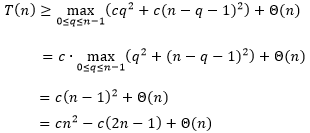
显然,只要
足够小,就能使得
,也就可以使得
成立。
综上所述,只要选取足够小的
,就能使得
对所有
的所有取值都成立。因此,
成立。
7.4-2 证明:在最好情况下,快速排序的运行时间为
。
解
在最好情况下,快速排序的运行时间
满足以下递归式
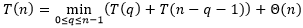
假设
,其中
为一个常数。我们用数学归纳法来证明。
(1) 初始情况n = 1
此时有
。显然无论
取何值,都能使得
成立。
(2) 归纳过程
假设
对
都成立,于是有
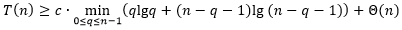
定义函数
,其中自变量
的取值范围为
,我们要求这个函数的最小值。对
求导,得到
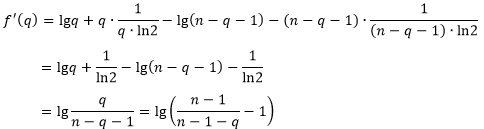
当
时,有
;当
时,有
;而当
时,有
。因此,
在
时取得最小值,最小值为
。于是有
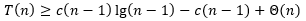
为了让
成立。我们令
。将这个不等式变换一下,得到
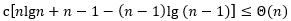
由于
,所以上面的不等式可以求解得到
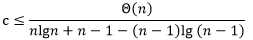
上式说明,只要
足够小,就能够使得
成立。
综上所述,只要选取足够小的
,就能使得
对所有
的取值都成立。因此,
成立。
7.4-3 证明:在
区间内,当
或
时,
取得最大值。
解
定义函数
。这是一个二次函数,它的曲线是一个开口向上的抛物线。我们知道,抛物线
的顶点的
坐标为
。于是,
的顶点横坐标为
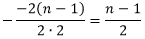
在顶点
处取得最小值,并且
正好位于区间
的正中间。根据抛物线的对称性,可以得出
在
或
时取得最大值。
7.4-4 证明:RANDOMIZED-QUICKSORT期望运行时间是
。
略
7.4-5 当输入数据已经“几乎有序”时,插入排序速度很快。在实际应用中,我们可以利用这一特点来提高快速排序的速度。当对一个长度小于
的子数组调用快速排序时,让它们不做任何排序就返回。当上层的快速排序调用返回后,对整个数组运行插入排序来完成排序过程。试证明:这一排序算法的期望时间复杂度为
。分别从理论和实践的角度说明我们应该如何选择
?
解
该题如果要严格证明很有难度,只做简单的分析。
该算法分为快速排序阶段和插入排序阶段。为简化分析,假设快速排序阶段后,留下的还未排序的子数组长度都为
。实际上,快速排序阶段有可能会得到长度小于
的子数组,但如果要考虑这些情况的话,分析太过复杂了。
下面对2个阶段分别进行分析。
(1) 快速排序阶段
我们回想一下本节对快速排序的分析,比较次数的期望值为
。在累加式中,下标
从i+1开始,到
结束。
对于本题的排序方案,在快速排序阶段,递归调用PARTITION划分到所有子数组的规模等于
为止。于是在快速排序阶段,只需要考虑长度不小于
的子数组。因此,在累加式中,下标
应当从
开始,到
结束。同时,下标
应当从
开始,到
结束。于是,比较次数的期望值为

故快速排序阶段的期望时间复杂度为
。
(2) 插入排序阶段
插入排序阶段虽然还是对整个数组执行插入排序,但是实际上可以看作是分别对快速排序阶段留下的每一个长度为
的子数组执行插入排序,因为子数组与子数组之间的顺序已经是正确的,只有子数组内部是还未经排序的。
长度为
的子数组不超过
个,对每个子数组执行插入排序的期望时间复杂度为
。因此,对所有长度为
的子数组进行插入排序的期望时间复杂度为
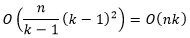
综合以上两部分,得到本题提出的排序算法的期望时间复杂度为
。
从理论上来说,
的选择与两种排序算法时间复杂度中的常量因子有关。如果快速排序时间复杂度中的常量因子相比插入排序常量因子越大,那么
也应当越大。反之,
应当越小。
实际应用中,可以通过实验来确定
应当如何选择。这部分实验后期再补上。
7.4-6 考虑对PARTITION过程做这样的修改:从数组
中随机选出三个元素,并用这三个元素的中位数(即这三个元素按大小排在中间的值)对数组进行划分。求以
的函数形式表示的、最坏划分比例为
的近似概率,其中
。
解
我们不妨设定
的取值范围为
。
实际上是对称的情况。
如果数组已经排好序,可以按照元素的大小顺序将数组分为
个部分,如下图所示。
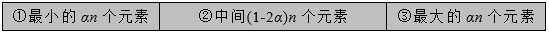
如果PARTITION过程选择的划分主元位于第②部分,那么产生的划分比
更好;而如果选择的划分主元位于第①部分和第③部分,那么产生的划分比
更坏。因此,我们需要求在数组中任取
个元素,中位数位于第②部分的概率。而中位数于第②部分,又可分为3种情况。
(1) 从第②部分任取3个元素
从第②部分
个元素中任取3个,有以下这么多种取法。
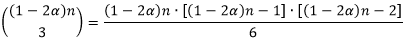
(2) 从第②部分任取2个元素,从第①部分或第③部分任取1个元素
从第②部分
个元素中任取2个,并且从第①部分和第③部分
个元素中任取1个,有以下这么多种取法。
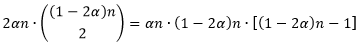
(3) 从第①部分、第②部分和第③部分中各任取1个元素
从第①部分
个元素中任取1个,从第②部分
个元素中任取1个,再从第③部分
个元素中任取1个,有以下这么多种取法。
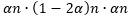
而从整个数组中任取3个元素,一共有以下这么多种取法。
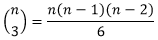
因此,中位数位于第②部分的概率
为
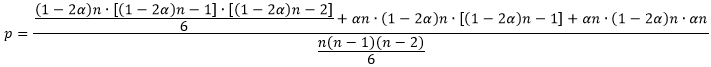
这个概率与数组的规模
有关。通常我们更关注
比较大的情况。我们计算
趋近于
时,概率
的极限,有
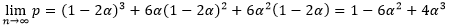
(注意:求
时
的极限,只需要将分子和分母中的低阶项删掉,保留高阶项即可。)
所以对规模
足够大的数组,采用三数取中法,中位数位于第②部分的概率接近于
。这也是应用三数取中法得到的数组划分好于
的近似概率。
我们可以侧面检验一下这个结果的正确性。将
代入
的极限,得到
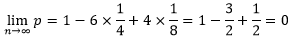
这说明“数组划分好于
(即完全平衡划分)”是不可能出现的。显然,这符合“数组划分的最好情况就是完全的平衡划分”这一事实。
我们再做一点分析,将“三数取中法”与原始方法进行比较。原始方法是随机选择一个划分元素,只有当这个元素位于第②部分时,才能得到一个好于
的划分,这种情况出现的概率为
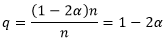
我们比较
与
的大小,有
。显然,在
取值范围内,有
。因此,“三数取中法”较原始方法有更高的可能性得到更好的划分。